SIFT was presented in 1999 by David Lowe and includes both a keypoint detector and descriptor. SIFT is computed as follows:
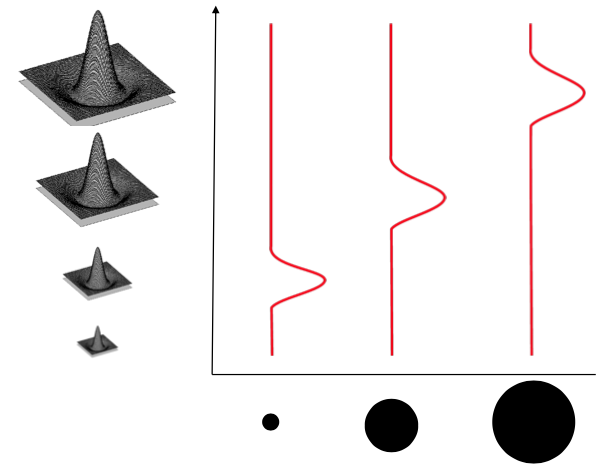
First, detect keypoints using the SIFT detector, which also detects scale and orientation of the keypoint.
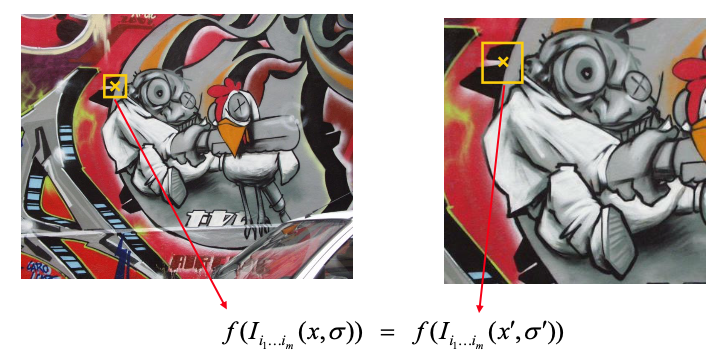
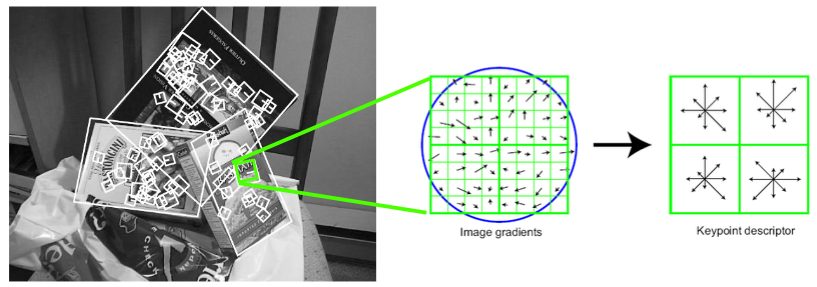
Next, for a given keypoint, warp the region around it to canonical orientation and scale and resize the region to 16X16 pixels.
Compute the gradients for each pixels (orientation and magnitude).
Divide the pixels into 16, 4X4 pixels squares.
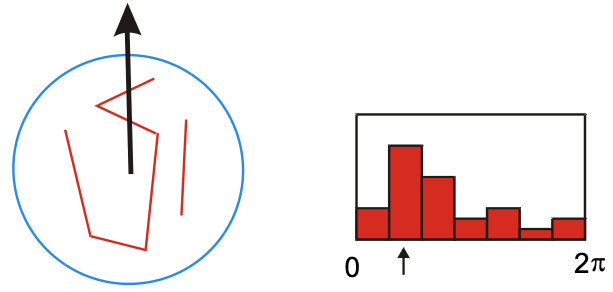
For each square, compute gradient direction histogram over 8 directions
concatenate the histograms to obtain a 128 (16*8) dimensional feature vector:
SIFT descriptor illustration:
SIFT is invariant to illumination changes, as gradients are invariant to light intensity shift. It’s also somewhat invariant to rotation, as histograms do not contain any geometric information.
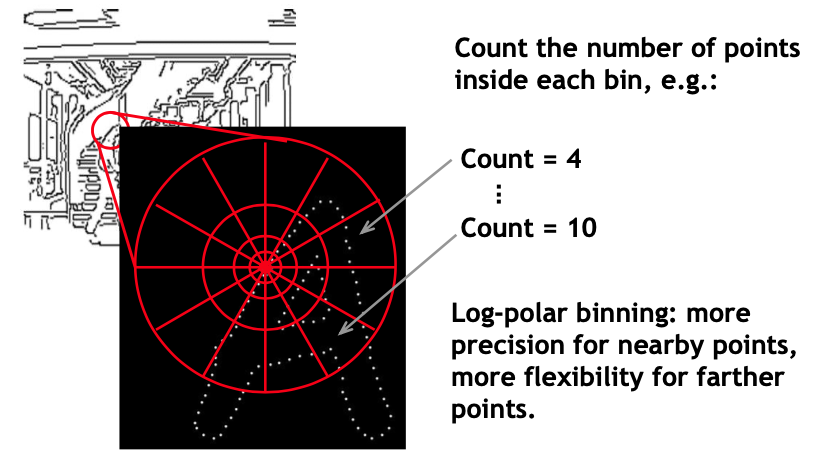
Shape Context Descriptor
What Local Features Should I Use?
Best choice often application dependent
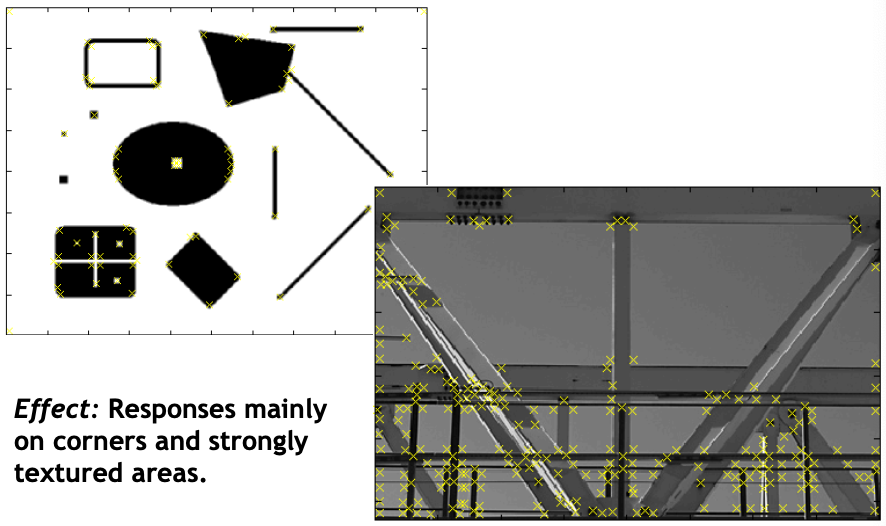
Harris-/Hessian-Laplace/DoG work well for many natural categories
More features are better
combining several detectors often helps
Learning Part Appearances
Visual Vocabulary
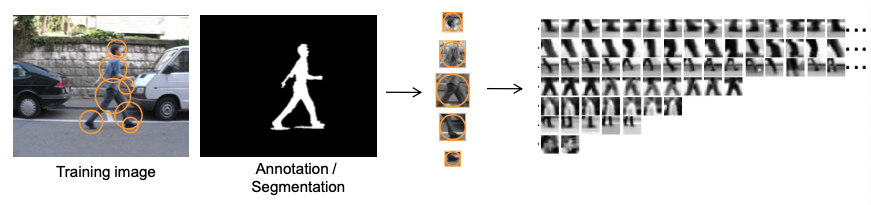
Detect keypoints on all person training examples
Compute local descriptors for all keypoints
-> Result: Large set of local image descriptors that all occur on people
Group visually similar local descriptors
similar local descriptors = parts that are reoccurring
parts, that occur only rarely are discarded (they could result from noise or background structures)
result: descriptor groups representing human body parts
Grouping Algorithms / Clustering
Partitional Clustering
K-Means
Gaussian Mixture Clustering (EM)
Hierarchical of Agglomerative Clustering
Single-Link (minimum)
Group-Average
Ward’s method (minimum variance)
Learning the Spatial Layout of Parts
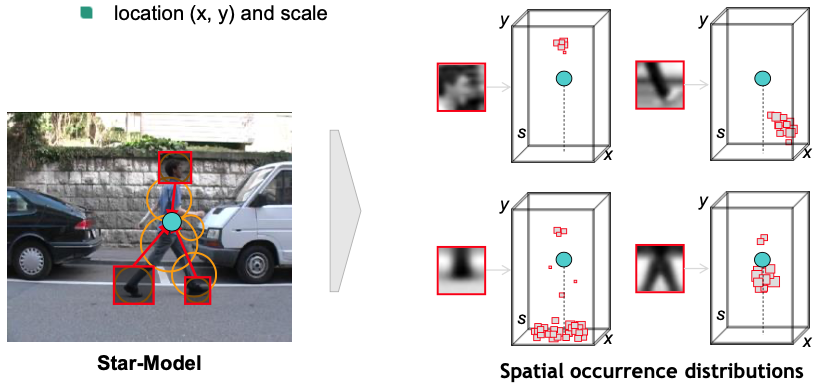
Spatial Occurrence (Star-Model)
Record spatial occurrence
match vocabulary entries to training images
record occurrence distributions with respect to object center (location $(x, y)$ and scale)
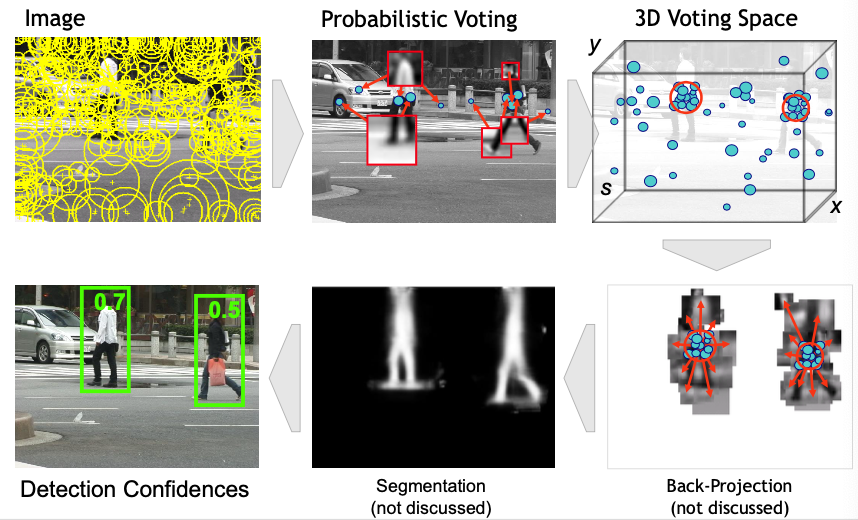
Generalized Hough Transform
For every feature, store possible “occurrences”
For new image, let the matched features vote for possible object positions
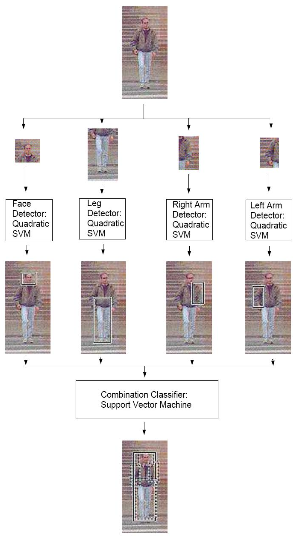
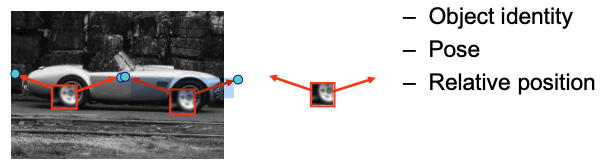
Combination of Part Detections
ISM Detection Procedure:
A. Mohan, C. Papageorgiou and T. Poggio, “Example-based object detection in images by components,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 23, no. 4, pp. 349-361, April 2001, doi: 10.1109/34.917571. ↩︎
Leibe, B. & Leonardis, Ales & Schiele, B.. (2004). Combined object categorization and segmentation with an implicit shape model. Proc. 8th Eur. Conf. Comput. Vis. (ECCV). 2. ↩︎