Time-Delay Neural Network (TDNN)
Motivation
Ensure shift-invariance
- The model should produce the same output regardless of the position of the considering object
Overview
Multilayer Neural Network: Nonlinear Classifier
Consider Context (Receptive Field)
Shift-Invariant Learning
- All Units Learn to Detect Patterns Independent of Location in Time
- No Pre-segmentation or Pre-alignment Necessary
- Approach: Weight Sharing
Time-Delay Arrangement
- Networks can represent temporal structure of speech
Translation-Invariant Learning
- Hidden units of the network learn features independent of precise location in time
Structure
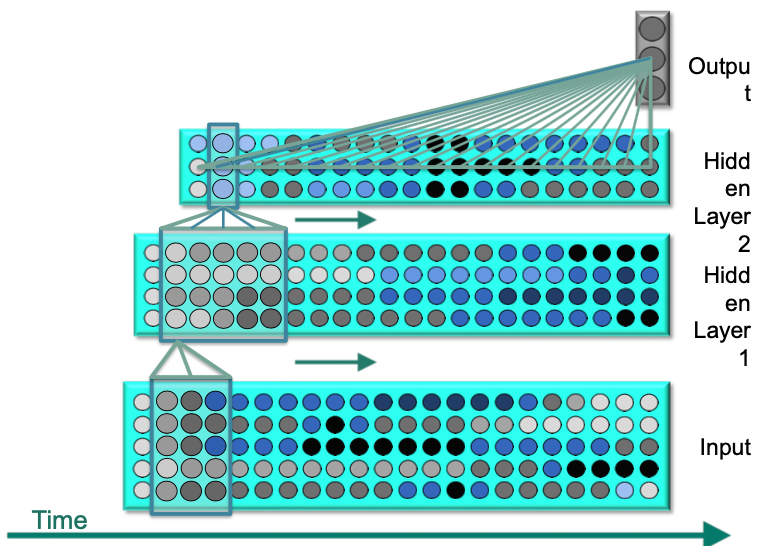
- Input: spectrum of a speech
- $x$-axis: time
- $y$-axis: frequency
How TDNN works?
Input layer $\to$ Hidden layer
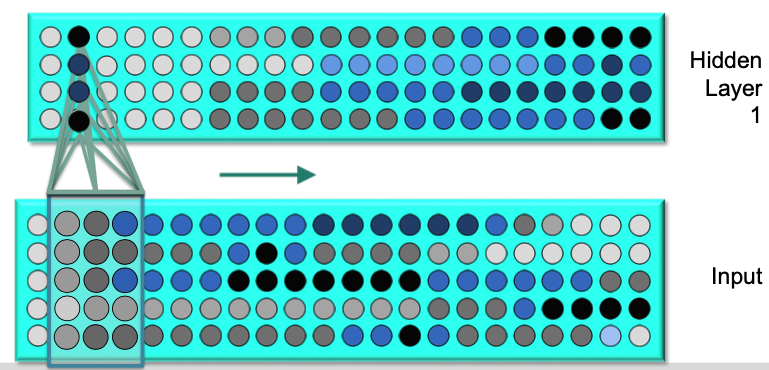
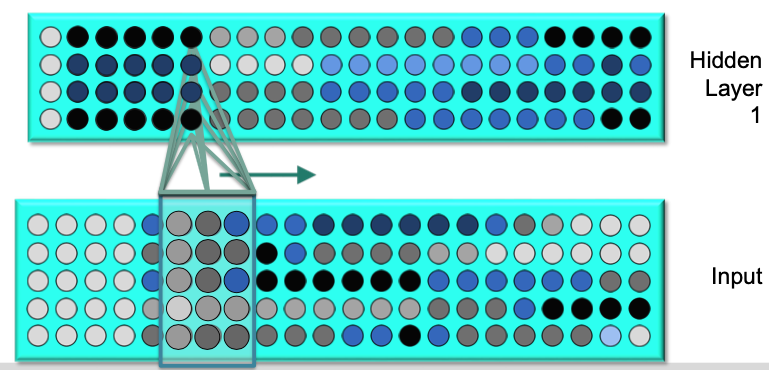
Hidden layer 1 $\to$ Hidden layer 2
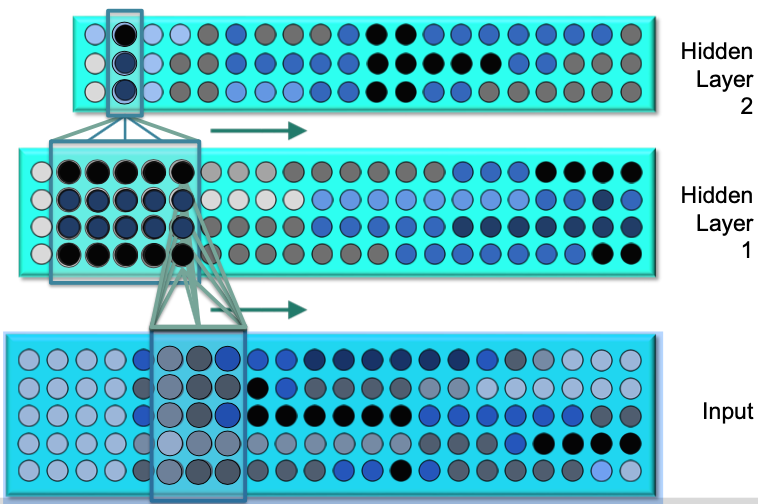
- As this input flows by, we have these hidden units generated activations over time as activation patterns.
- Then we can take a contextual window of activation patterns over time and feed them into neurons in the second hidden layer
Hidden layer $\to$ Output layer
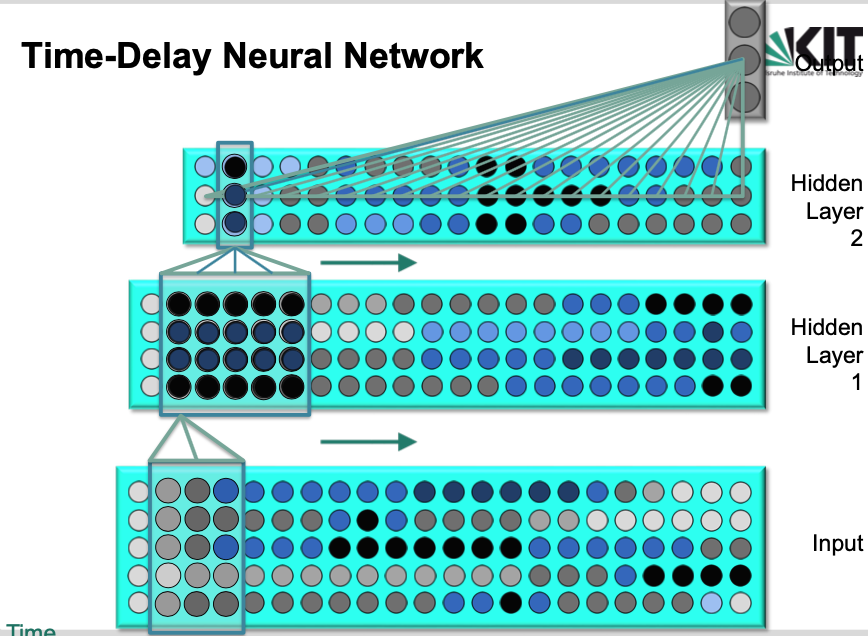
- We assemble all the evidence from activations over time and integrate them into one joint output
Shift-Invariance Training
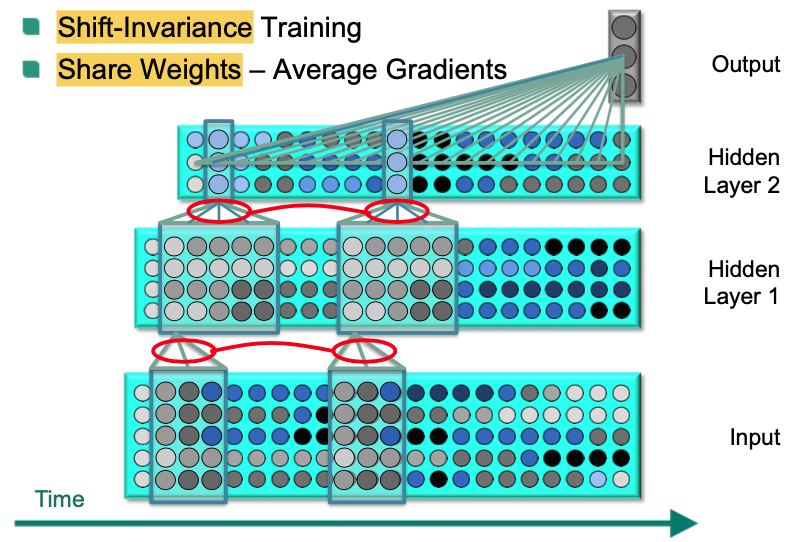
Connections with the same color share the same weight.
Demo
TDNN / Convolutional Nets - Demo
TDNN’s→Convolutional Nets
In Vision the same problem:
- Local Contexts – Global Integration – Shared Weights
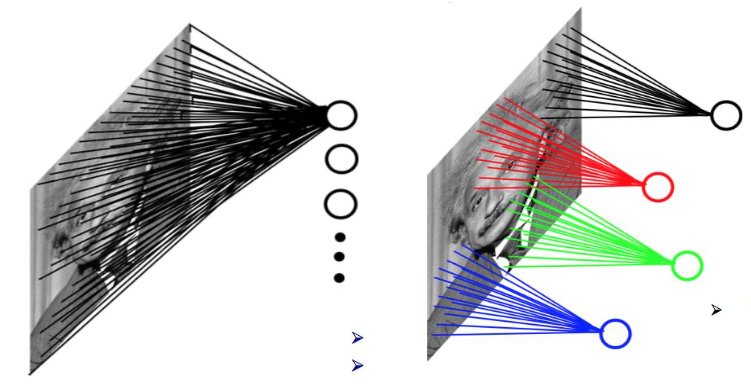
TDNN is equivalent to 1-dimensional CNN
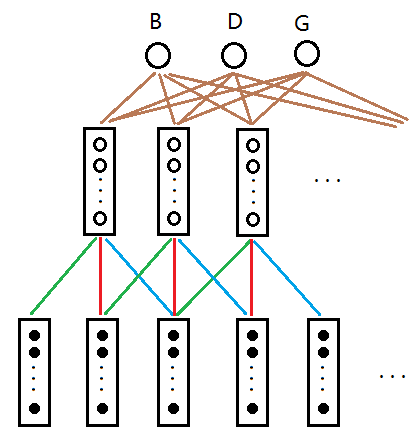
TDNN Parameters Calculation
Exam WS1819, Task 4.1
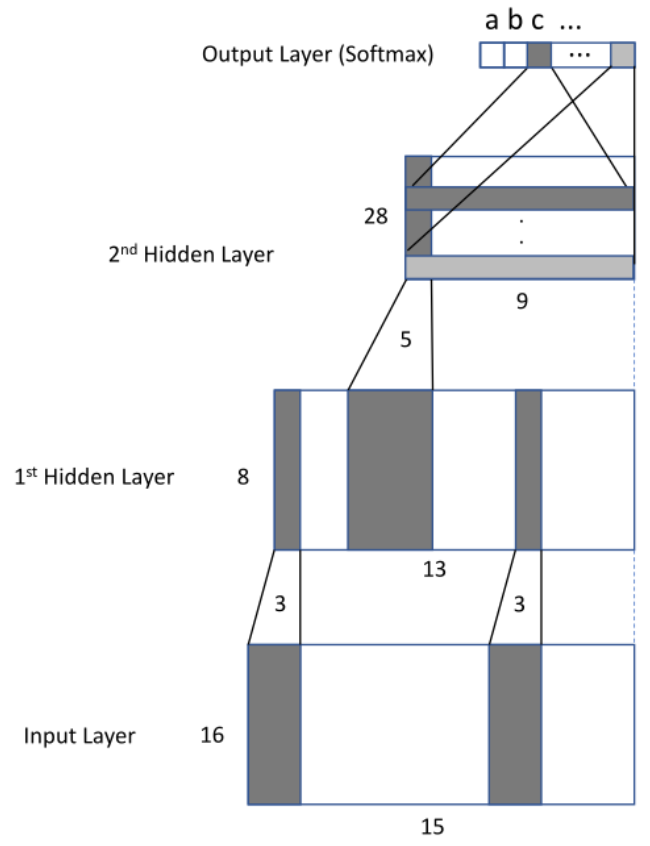
- Input: matrix of the dimension 16 × 15
- Chunks of a sequence of 15 frames
- Each frame is a feature vector of 16 real numbers
- 3 subsequent frames are connected to a 1 frame in the first hidden layer in a shift-invariant path, i.e. these connection weights of this shift-invariant matrix are shared.
- A similar approach is used for the second hidden layer
- No bias for the first and second hidden layer
- The output layer is a layer that connects each row of outputs from the previous layer, followed by a soft-max that calculates the probabilities of each letter.
- Possible output: 26 letters (a - z) ,
<blank>,<space>
Question: Number of parameters?