👍 RNN Summary
Intuition
Humans don’t start their thinking from scratch every second. As you read this article, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking from scratch again. Your thoughts have persistence.
Traditional neural networks can’t do this, and it seems like a major shortcoming. For example, imagine you want to classify what kind of event is happening at every point in a movie. It’s unclear how a traditional neural network could use its reasoning about previous events in the film to inform later ones.
Recurrent neural networks (RNNs) address this issue and solve it pretty well.
Sequence Data
- Sequence: a particular order in which one thing follows another
- Forms of sequence data
- Audio: natural sequence. You can chop up an audio spectrogram into chunks and feed that into RNN’s.
- Text: You can break Text up into a sequence of characters or a sequence of words.
Sequential Memory
RNN’s are good at processing sequence data for predictions by having a concept called sequential memory.
Let’s take a look at an example: the alphabet.
Say the alphabet in your head:

That was pretty easy right. If you were taught this specific sequence, it should come quickly to you.
Now try saying the alphabet backward.

This is much harder. Unless you’ve practiced this specific sequence before, you’ll likely have a hard time.
Now let’s try starting at the letter “F”:

At first, you’ll struggle with the first few letters, but then after your brain picks up the pattern, the rest will come naturally.
So there is a very logical reason why this can be difficult. You learn the alphabet as a sequence. Sequential memory is a mechanism that makes it easier for your brain to recognize sequence patterns.
Recurrent Neural Network (RNN)
How does RNN replicate the abstract concept of sequential memory?
Let’s look at a traditional neural network also known as a feed-forward neural network. It has its input layer, hidden layer, and the output layer.
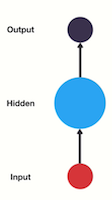
💡 Get a feed-forward neural network to be able to use previous information to effect later ones: add a loop in the neural network that can pass prior information forward
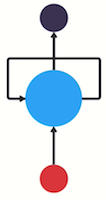
And that’s essentially what a recurrent neural network does! A RNN has a looping mechanism that acts as a highway to allow information to flow from one step to the next.
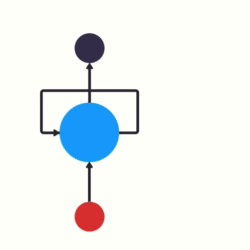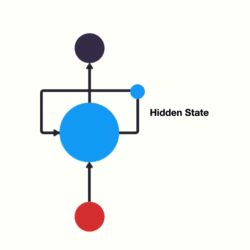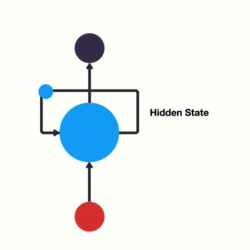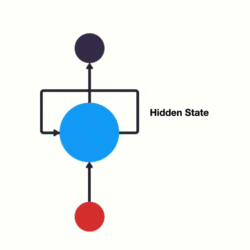
This information is the hidden state, which is a representation of previous inputs.
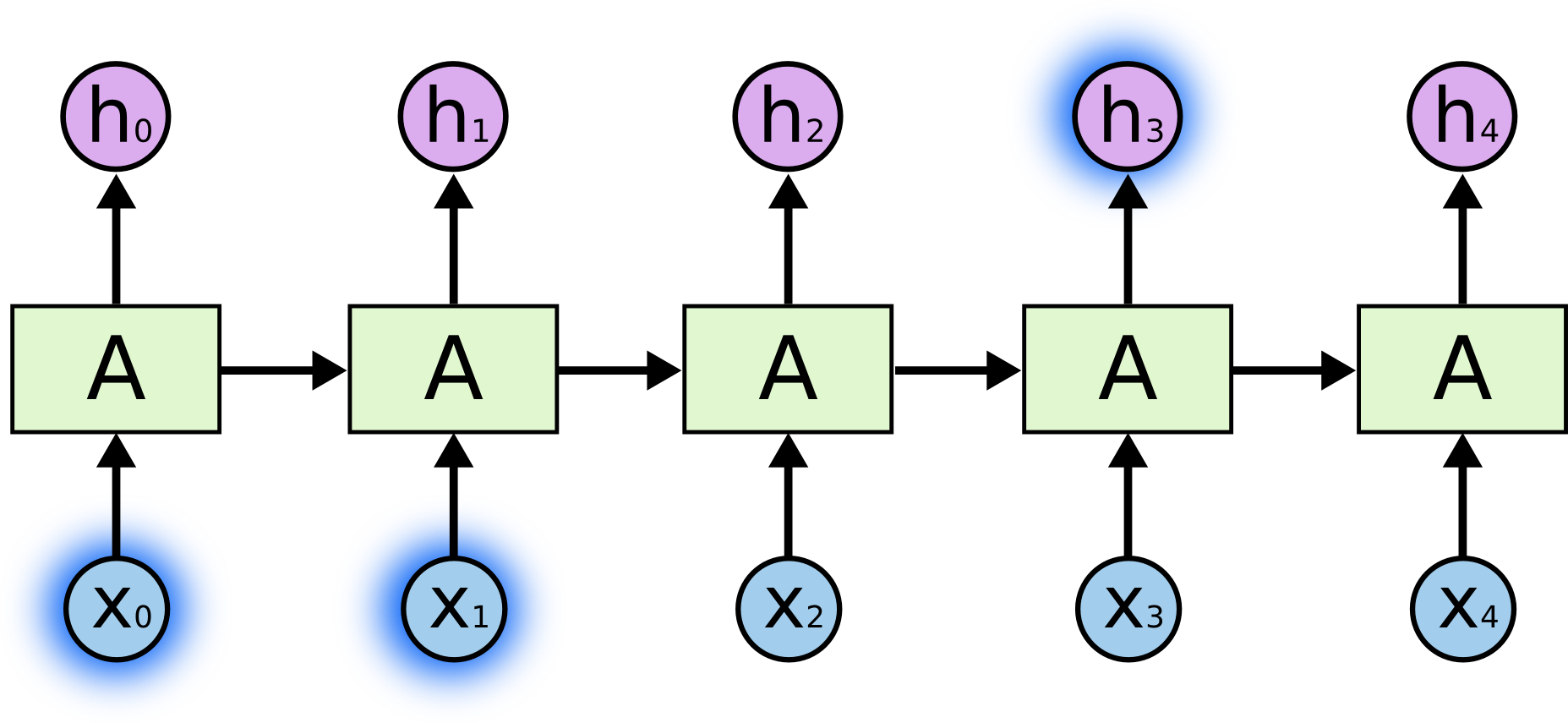
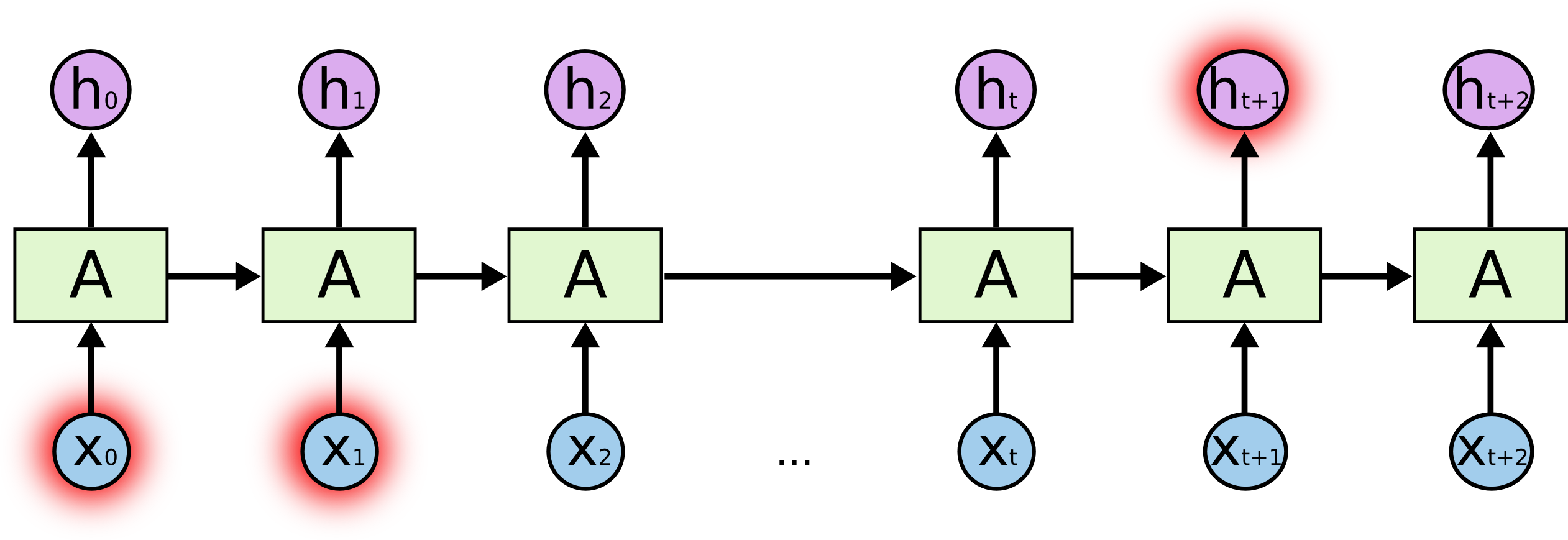
Unrolled RNN
These loops make recurrent neural networks seem kind of mysterious. However, if you think a bit more, it turns out that they aren’t all that different than a normal neural network.
A recurrent neural network can be thought of as multiple copies of the same network, each passing a message to a successor.
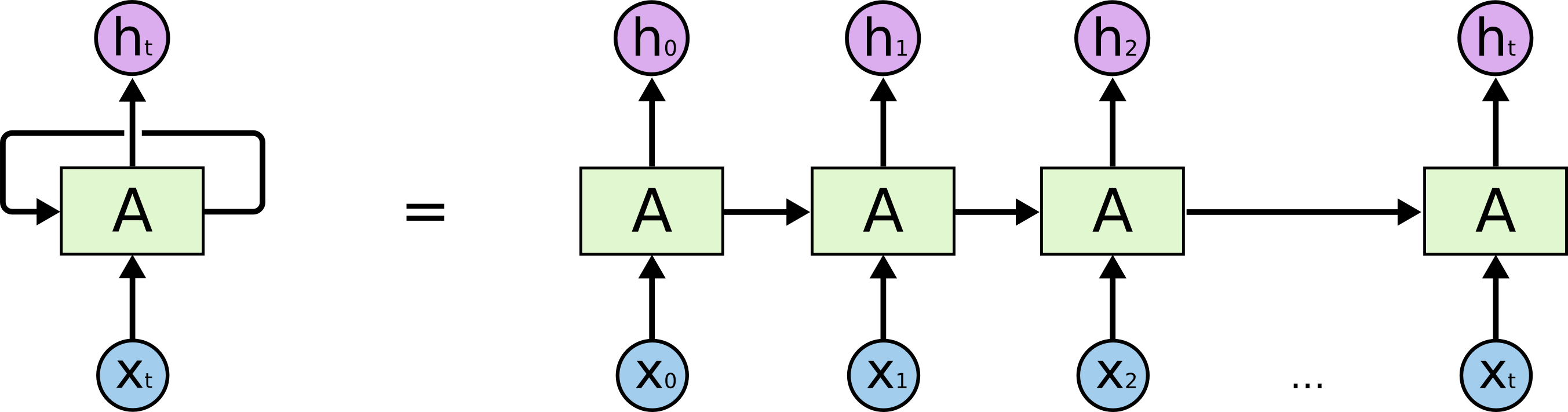
This chain-like nature reveals that recurrent neural networks are intimately related to sequences and lists. They’re the natural architecture of neural network to use for such data.
Chatbot Example
Let’s say we want to build a chatbot, which can classify intentions from the users inputted text. We’re going to tackle this problem as follows:
- Encode the sequence of text using a RNN
- Feed the RNN output into a feed-forward neural network which will classify the intents.
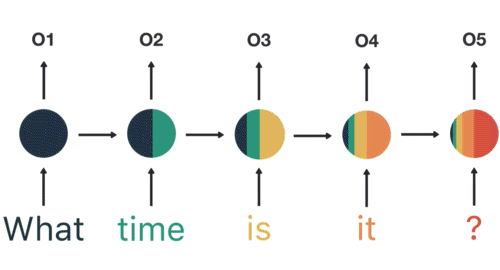
Now a user types in “What time is it?”
To start, we break up the sentence into individual words. RNNs work sequentially so we feed it one word at a time.

Then we feed each word into the RNN until the final step. In each step, the RNN encodes each input word and produces an output
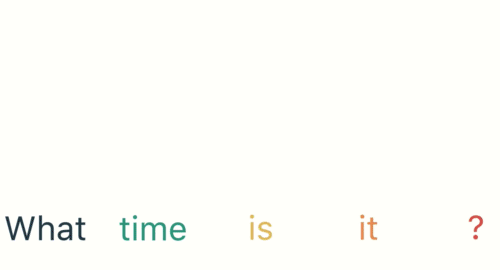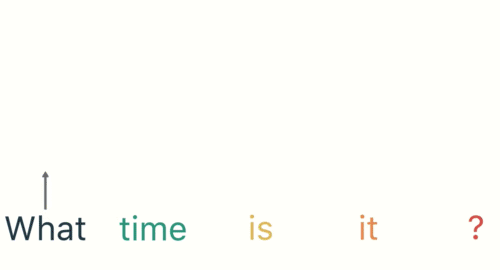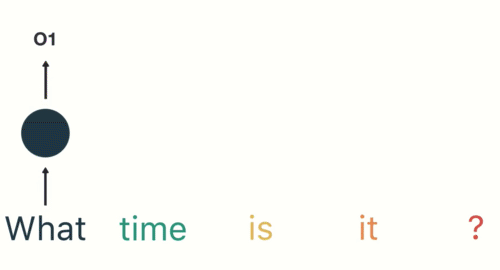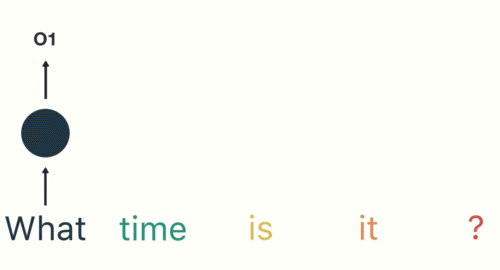
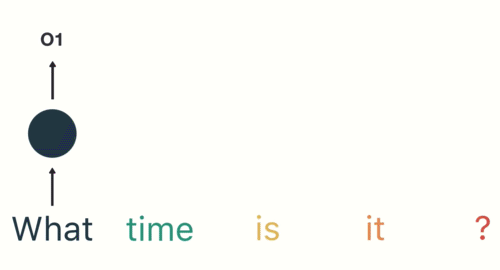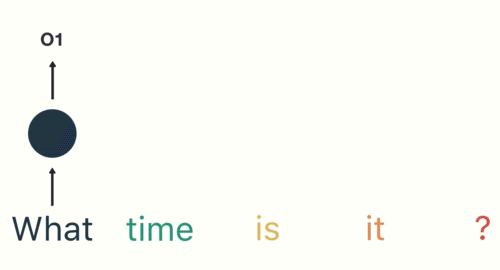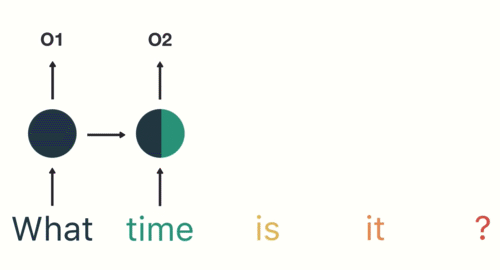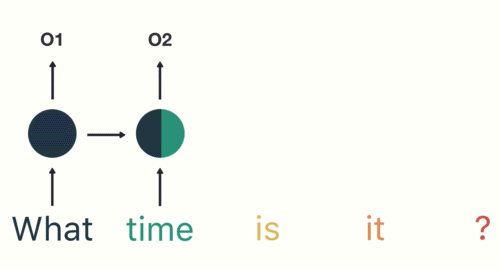 $$
\vdots
$$
$$
\vdots
$$
we can see by the final step the RNN has encoded information from all the words in previous steps.
Since the final output was created from the rest of the sequence, we should be able to take the final output and pass it to the feed-forward layer to classify an intent.
Python pseudocode for the above workflow:
# initialize network layers
rnn = RNN()
ff = FeedForwardNN()
# initialize hidden state
# (shape and dimension will be dependent on the RNN)
hidden_state = [0.0, 0.0, 0.0, 0.0]
# Loop through inputs, pass the word and hidden state into the RNN,
# RNN returns the output and a modified hidden state.
# Continue to loop until out of words
for word in input:
output, hidden_state = rnn(word, hidden_state)
# Pass the output to the feedforward layer, and it returns a prediction
prediction = ff(output)
Problem of RNN
Intuition and Example
Sometimes, we only need to look at recent information to perform the present task. For example, consider a language model trying to predict the next word based on the previous ones.
- If we are trying to predict the last word in “the clouds are in the sky,” we don’t need any further context – it’s pretty obvious the next word is going to be sky. In such cases, where the gap between the relevant information and the place that it’s needed is small, RNNs can learn to use the past information.
But there are also cases where we need more context.
Consider trying to predict the last word in the text “I grew up in France… I speak fluent French.”
- Recent information suggests that the next word is probably the name of a language.
- But if we want to narrow down which language, we need the context of France, from further back. It’s entirely possible for the gap between the relevant information and the point where it is needed to become very large.
Unfortunately, as that gap grows, RNNs become unable to learn to connect the information. 😢
Short-term Memory
This issue of RNN is known as short-term memory.
Short-term memory is caused by the infamous vanishing gradient problem, which is also prevalent in other neural network architectures.
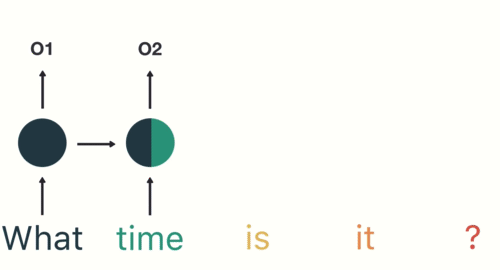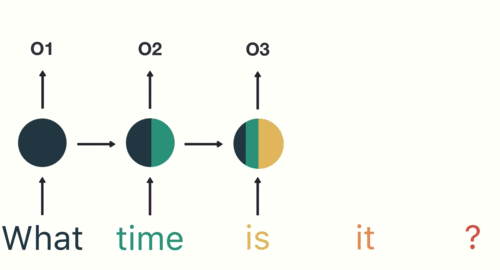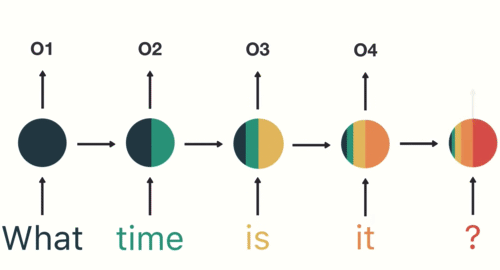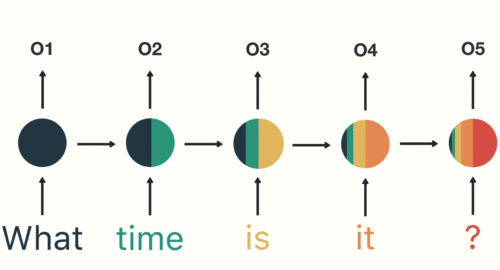
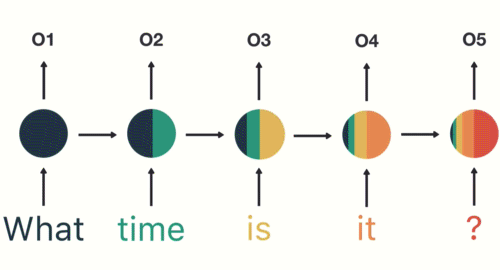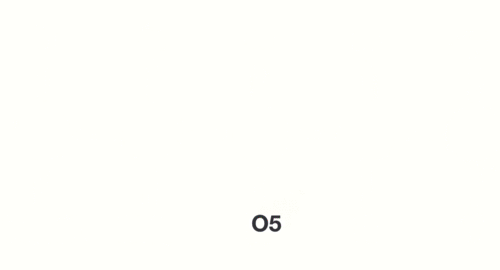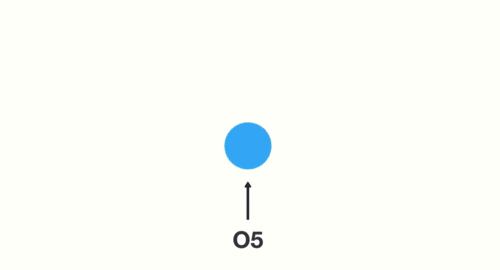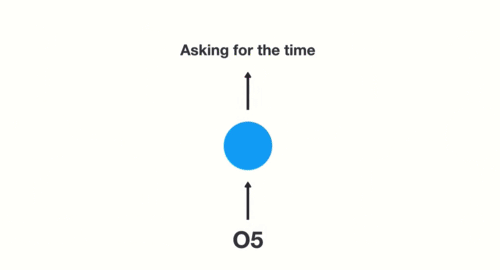
As the RNN processes more steps, it has troubles retaining information from previous steps. As you can see, in the above chatbot example, the information from the word “what” and “time” is almost non-existent at the final time step.

Vanishing Gradient
Short-Term memory and the vanishing gradient is due to the nature of back-propagation, an algorithm used to train and optimize neural networks. To understand why this is, let’s take a look at the effects of back propagation on a deep feed-forward neural network.
Training a neural network has three major steps:
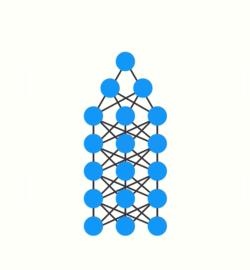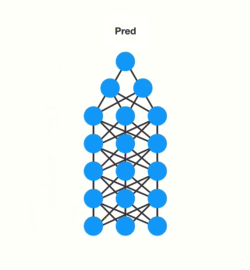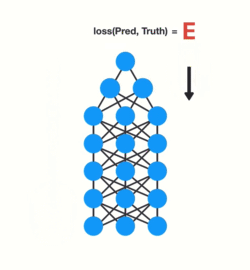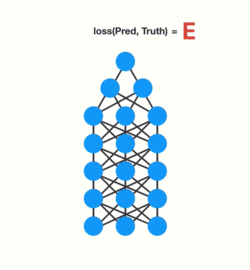
- It does a forward pass and makes a prediction.
- It compares the prediction to the ground truth using a loss function. The loss function outputs an error value which is an estimate of how poorly the network is performing.
- It uses that error value to do back propagation which calculates the gradients for each node in the network.
The gradient is the value used to adjust the networks internal weights, allowing the network to learn. The bigger the gradient, the bigger the adjustments and vice versa.
Here is where the problem lies!
When doing back propagation, each node in a layer calculates it’s gradient with respect to the effects of the gradients, in the layer before it. So if the adjustments to the layers before it is small, then adjustments to the current layer will be even smaller. That causes gradients to exponentially shrink as it back propagates down. The earlier layers fail to do any learning as the internal weights are barely being adjusted due to extremely small gradients. And that’s the vanishing gradient problem.
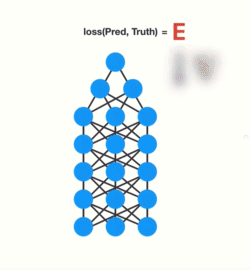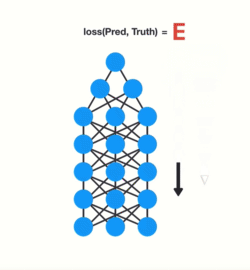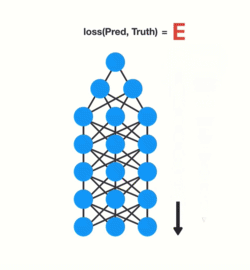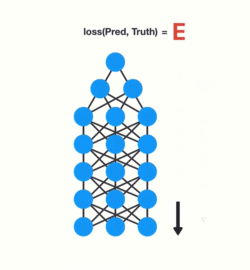
Let’s see how this applies to RNNs. We can think of each time step in a recurrent neural network as a layer. To train a recurrent neural network, you use an application of back-propagation called Back-Propagation Through Time (BPTT). The gradient values will exponentially shrink as it propagates through each time step. 😢
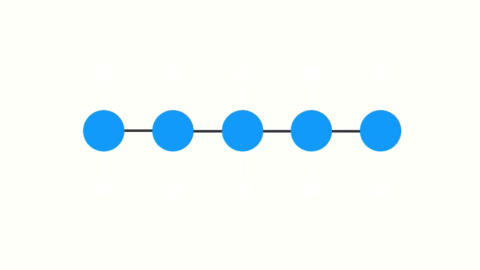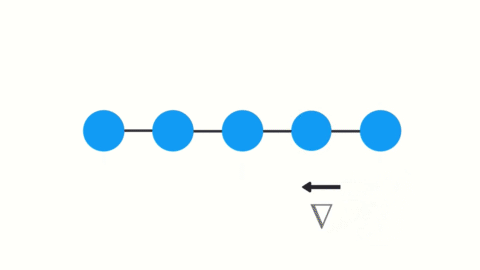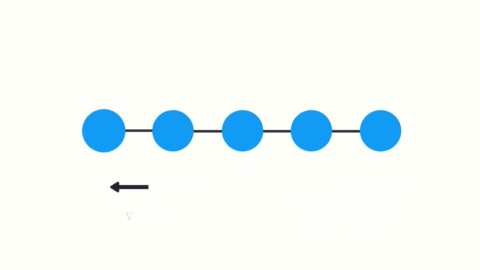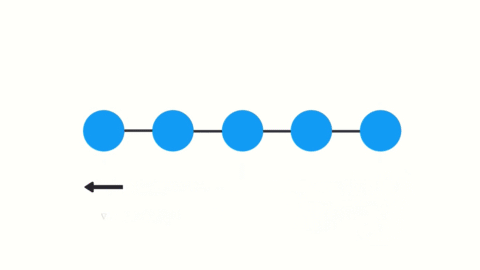
Again, the gradient is used to make adjustments in the neural networks weights thus allowing it to learn. Small gradients mean small adjustments. That causes the early layers NOT to learn. 🤪
Because of vanishing gradients, the RNN doesn’t learn the long-range dependencies across time steps. That means that in our chatbot example there is a possibility that the word “what” and “time” are not considered when trying to predict the user’s intention. The network then has to make the best guess with “is it?”. That’s pretty ambiguous and would be difficult even for a human. So not being able to learn on earlier time steps causes the network to have a short-term memory.
Solution
- Long Short-Term Memory (LSTM)
- Gated Recurrent Unit (GRU)