People Detection: Deep Learning Approaches
Deep Learning for Object Detection
- People detections is a special case of object detection (one of the most challenging object classes to detect)
- Recently, most detectors are trained for the more challenging task of multi-object detection
- Goal: Given an image, detect all instances of, say, 1000 different object classes
- “Person” always one of the classes
- Speed is an issue
- Sliding Window: Look at each position, each scale
- Cascades look at each position too
- They just take a shorter look at most positions/scales
- Region Proposals: Avoid useless positions/scales from the beginning
Region Proposals
💡Idea
- Identify image regions that are likely to contain an object
- Don’t care about the object class in the regions at this point
Characterization of a general object
- Find “blobby” regions
- Find connected regions that are somehow distinct from their surroundings
Requirements
- FAST!!!
- High recall
- Can allow a relatively high amount of false positives
2 main categories
Grouping methods
Generate proposals based on hierarchically grouping meaningful image regions
Often better localization
E.g. Selective search
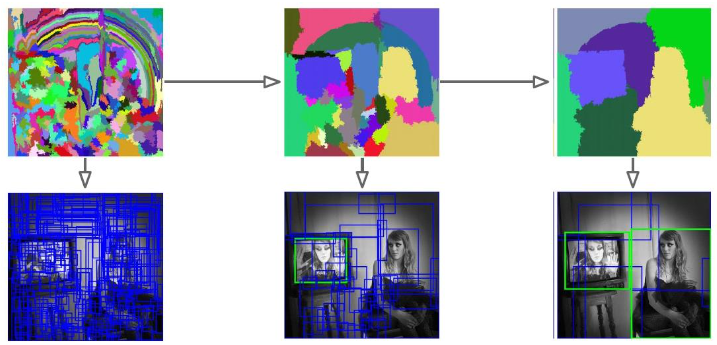
Window scoring methods
- Generate a large amount of windows
- Use a quickly computed cue to discard unlikely windows (“objectness” measure)
- Often faster
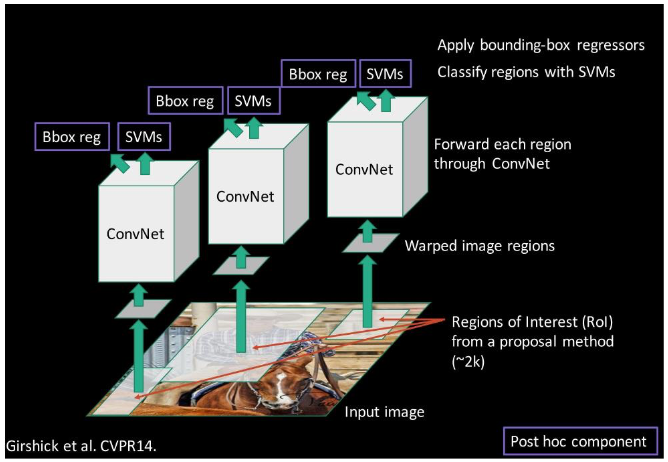
R-CNN 1
Idea and structure
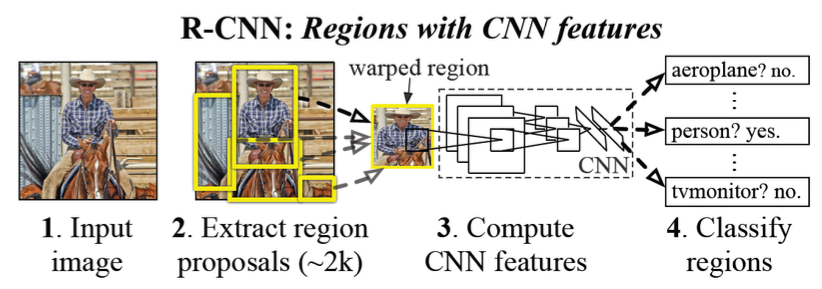
Training
Train AlexNet on ImageNet (1000 classes)
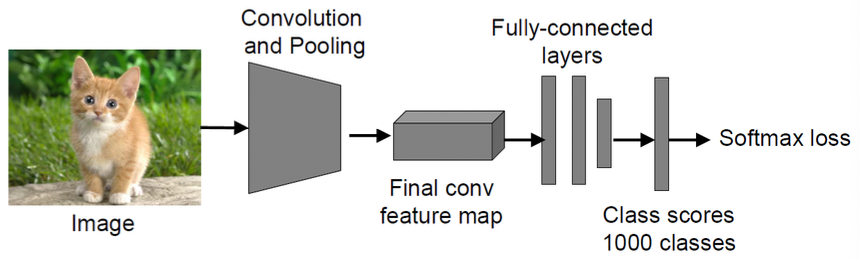
Re-initialize last layers to a different dimension (depending on the #classes of the new classifier) and train new model
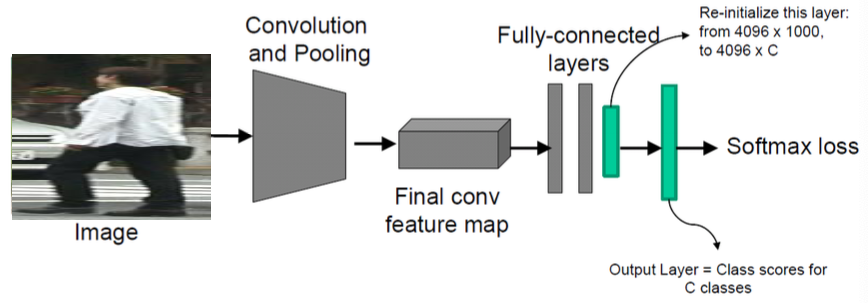
Train a classifier
Binary SVMs (e.g. is human? yes/no) for each object class SVMs in our case
The outputs of pool5 of the retrained AlexNet are used as features
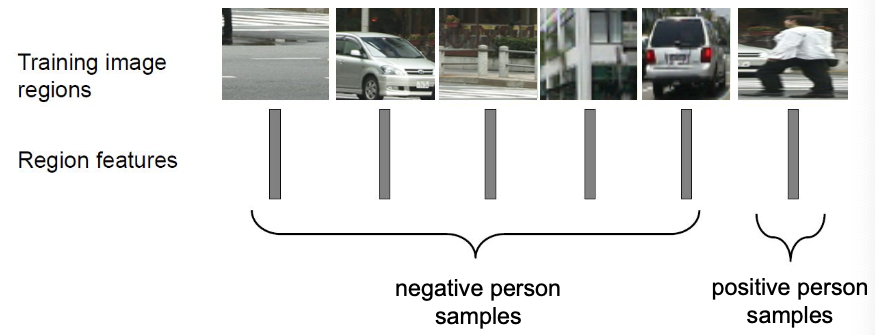
Improve the region proposals
Use a regression model to improve the estimated locatin of the object
- Input: features of proposed region (pool5)
- output: x, y, width, height of the estimated region
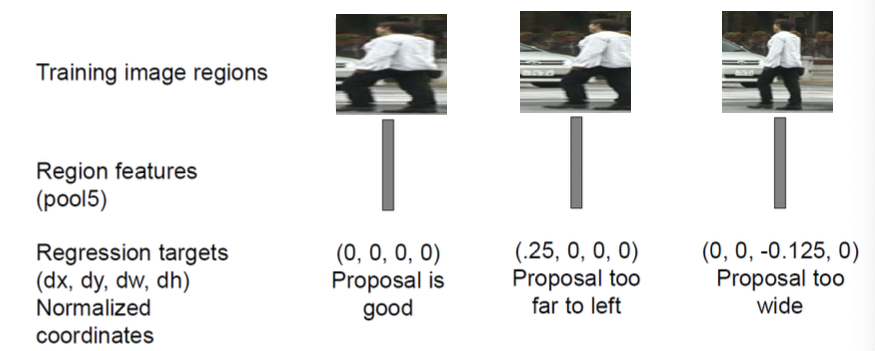
Downsides
Speed: Need to forward-pass EACH region proposal through entire CNN!!!
SVM & BBox regressor are trained after CNN is fixed
- No simultaneous update/adaptation of CNN features possible
Complexity: multi-stage approach
Improvement:
For 1: Can we make (part of) the CNN run only once for all proposals?
For 2&3: Can we make the CNN perform these steps?
Fast R-CNN 2
Overview
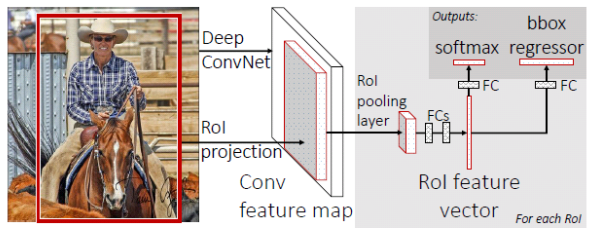
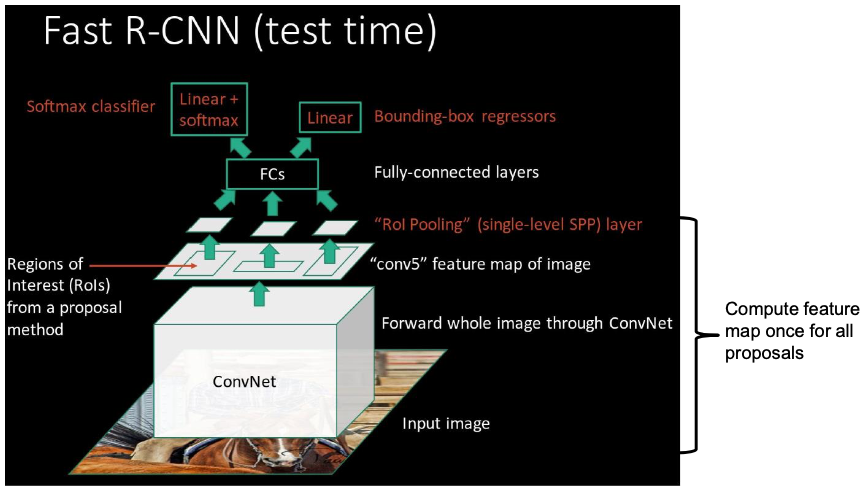
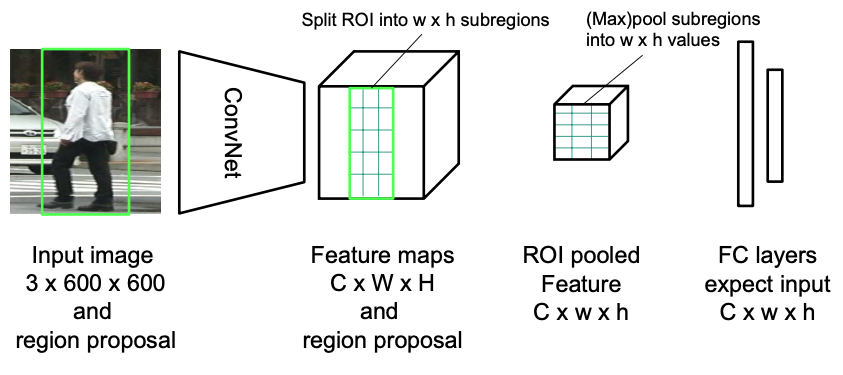
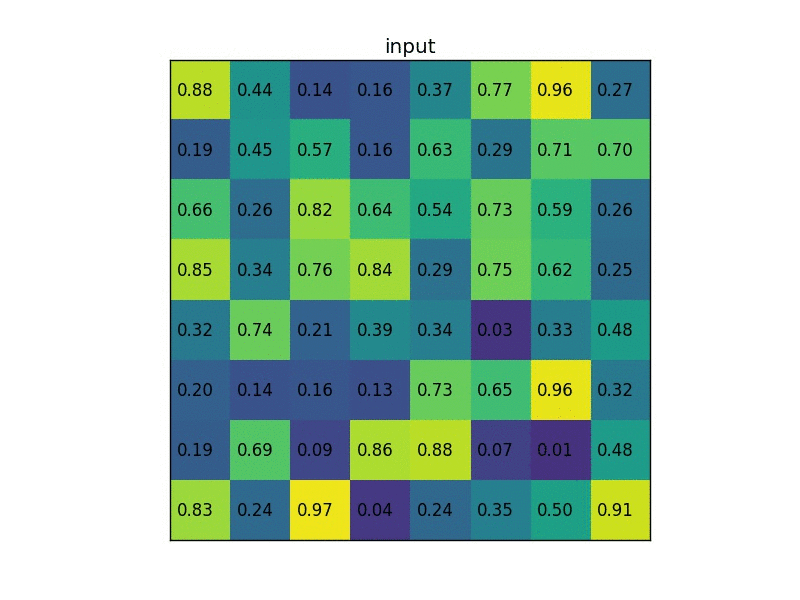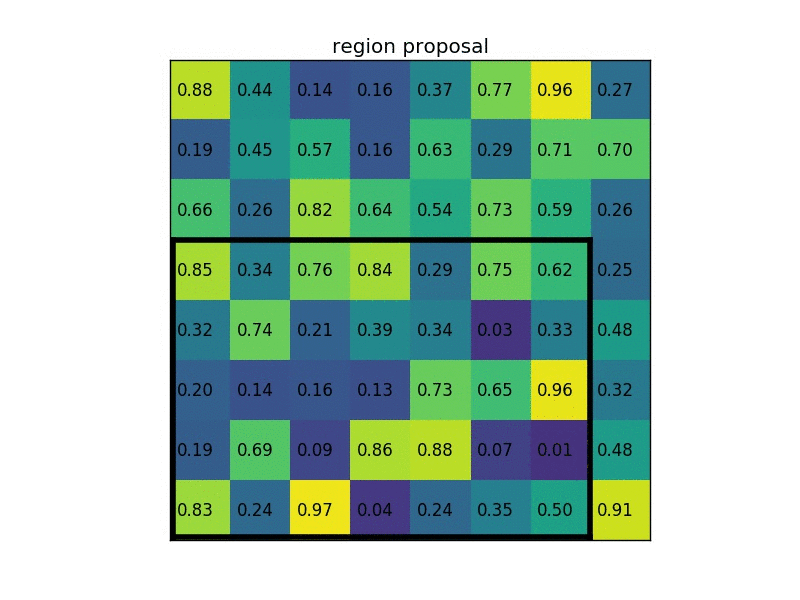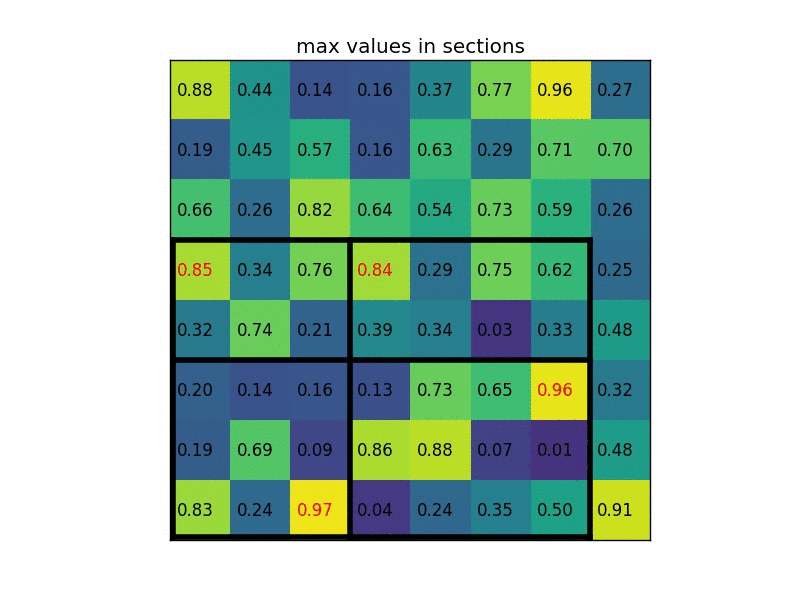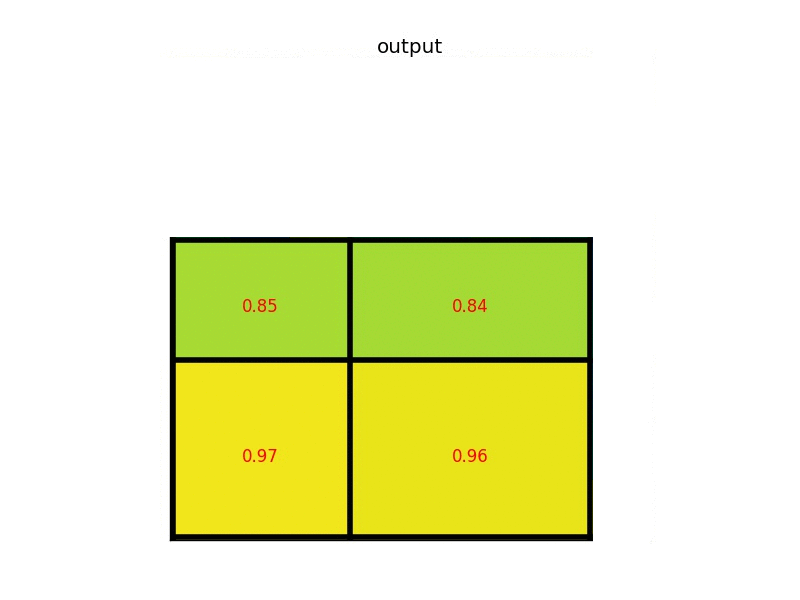
ROI pooling
- Conv layers don’t care about input size, FC layers do
- ROI pooling: warp the variable size ROIs into in a predefined fix size shape.
End-to-end training
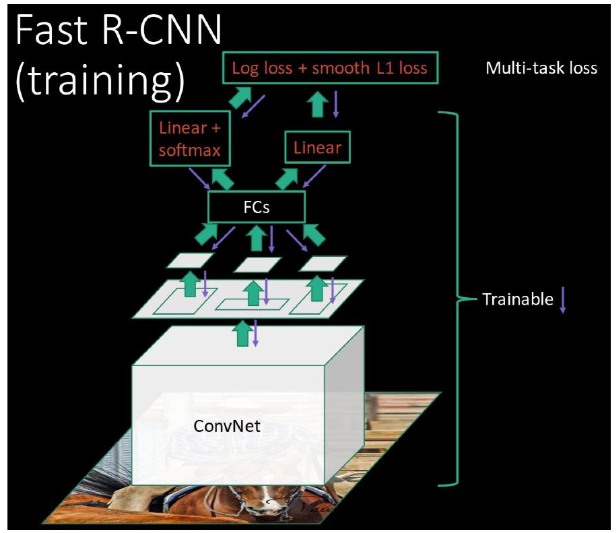
- Instead of SVM & Regressor just add corresponding losses and train the system for both (multitask)
- Gradients can backprop. into feature layers through ROI pooling layers (just as with normal maxpool layers)
- End-to-end brings slight improvement 👏
- Softmax (integrated) loss slightly but consistently outperforms external classifier 👏
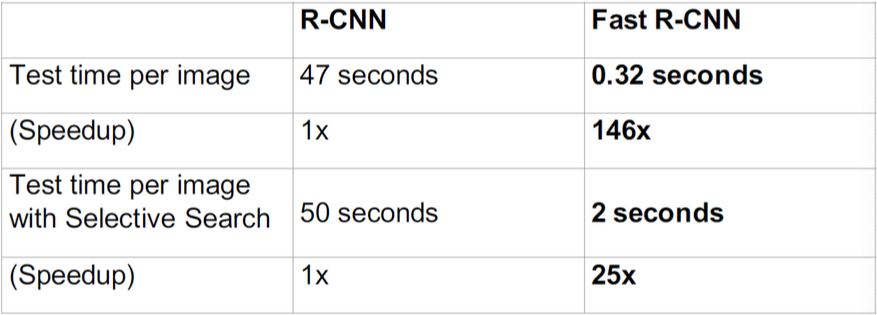
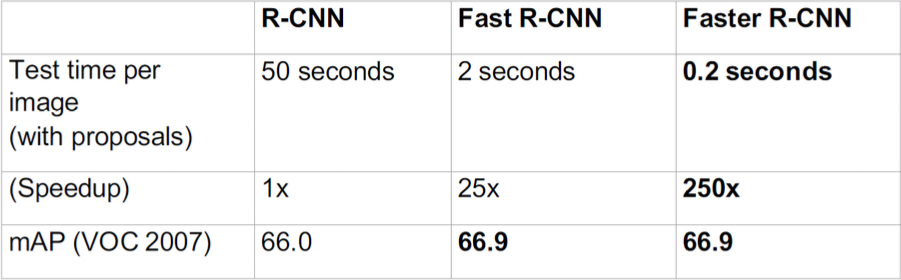
Fast R-CNN vs R-CNN
Speed:
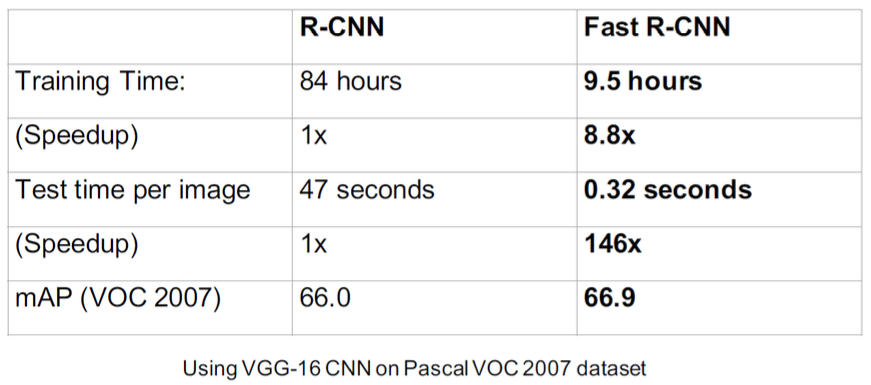
Downsides
Majority of time is lost for region proposals
Model is also not fully end-to-end: proposals come from “outside”
(Can we include them in the CNN as well? 🤔)
Faster R-CNN3
Overview
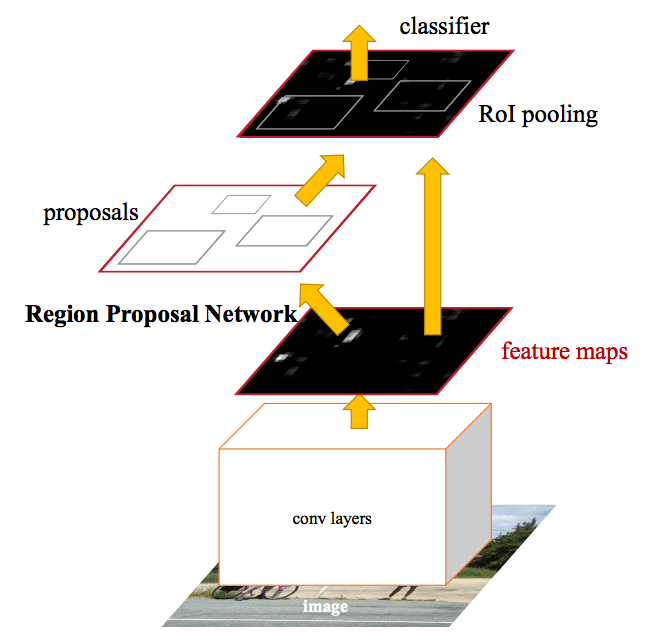
Region Proposal Network (RPN)
Input: Feature map from larger conv network of size
Output
- List of proposals
- “Objectness” score of size
- coordinates (top-left and bottom-right coordinates) for bounding box
- for objectness (with vs. without object) per location
General approach:
- Take a mini net (RPN) and slide it over the feature map (stepsize 1)
- At each position evaluate different window sizes for objectness
- Results in approx. windows/proposals
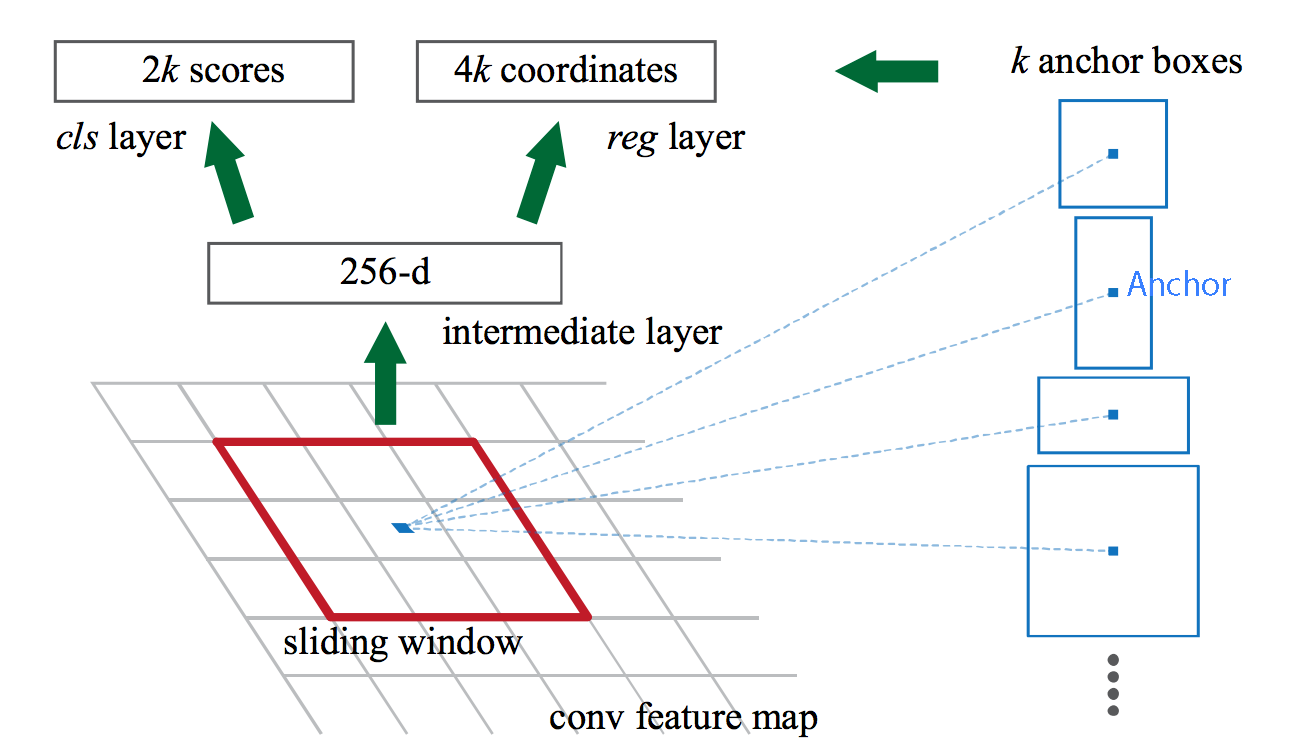
Fully convolutional network
Anchors: tackle the scale problem of the feature map
- Initial reference boxes consisting of aspect ratio and scale, centered at sliding window
- 3 scales and 3 aspect ratios = 9 anchors
Layers
- reg layer: regression of the reference anchor
- cls layer: object/no object score
Loss
Need a label for each anchor to train the objectness classification
Labelling anchors
- Positive: highest IoU with groundtruth or IoU > 0.7 (can be more than one)
- Also store the association between anchor and groundtruth box
- Negative: others, if their IoU < 0.3
- Other anchors do not contribute to training
Convert to classification problem
- Positive: highest IoU with groundtruth or IoU > 0.7 (can be more than one)
RPN multitask loss:
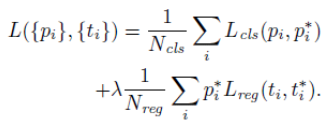
- : Batch size (256)
- : number of window positions ( 2400)
Training
As in paper
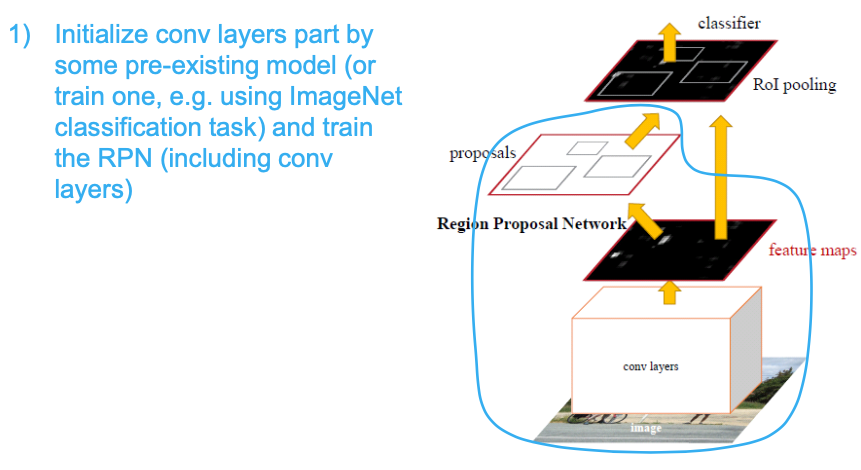
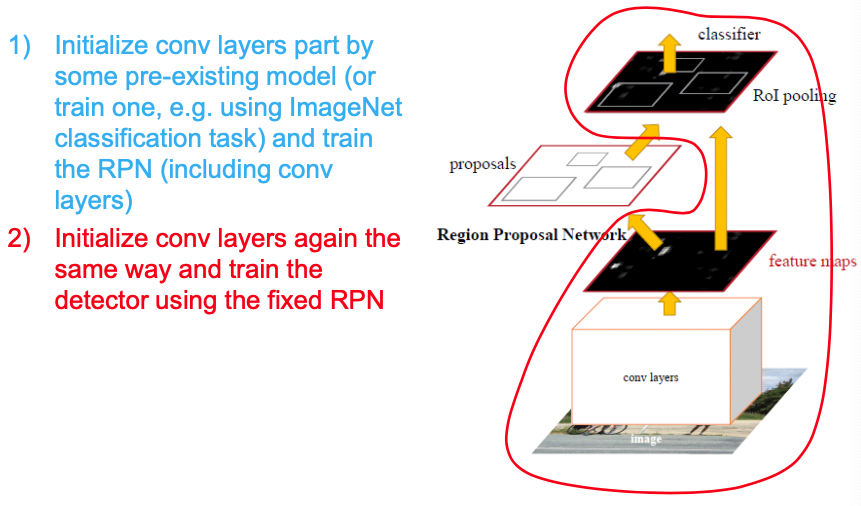
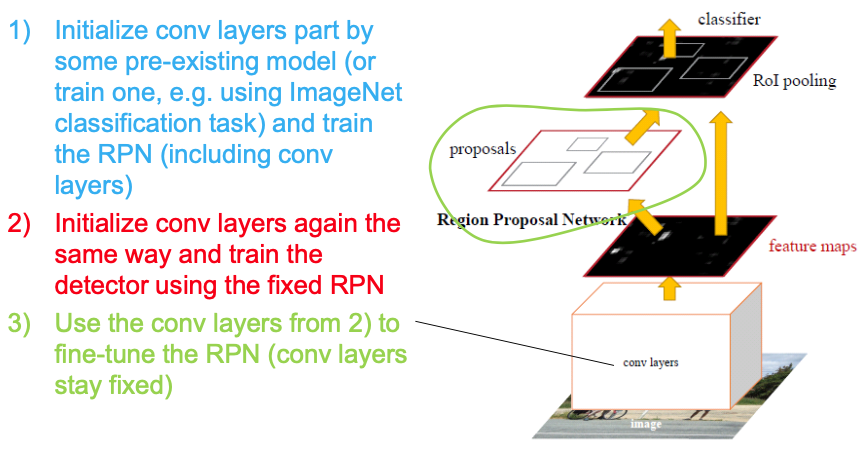
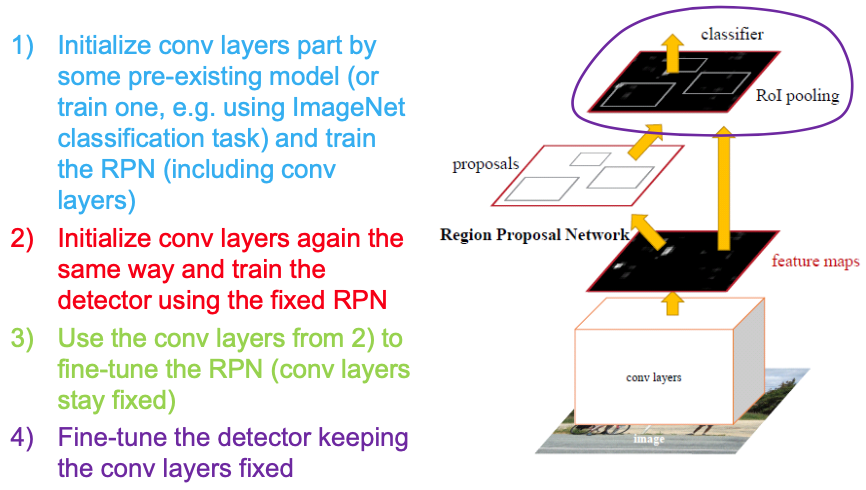
Jointly
Train everything in one go
Combination of four losses
- objectness classification
- anchor regression
- object class classification
- detection regression
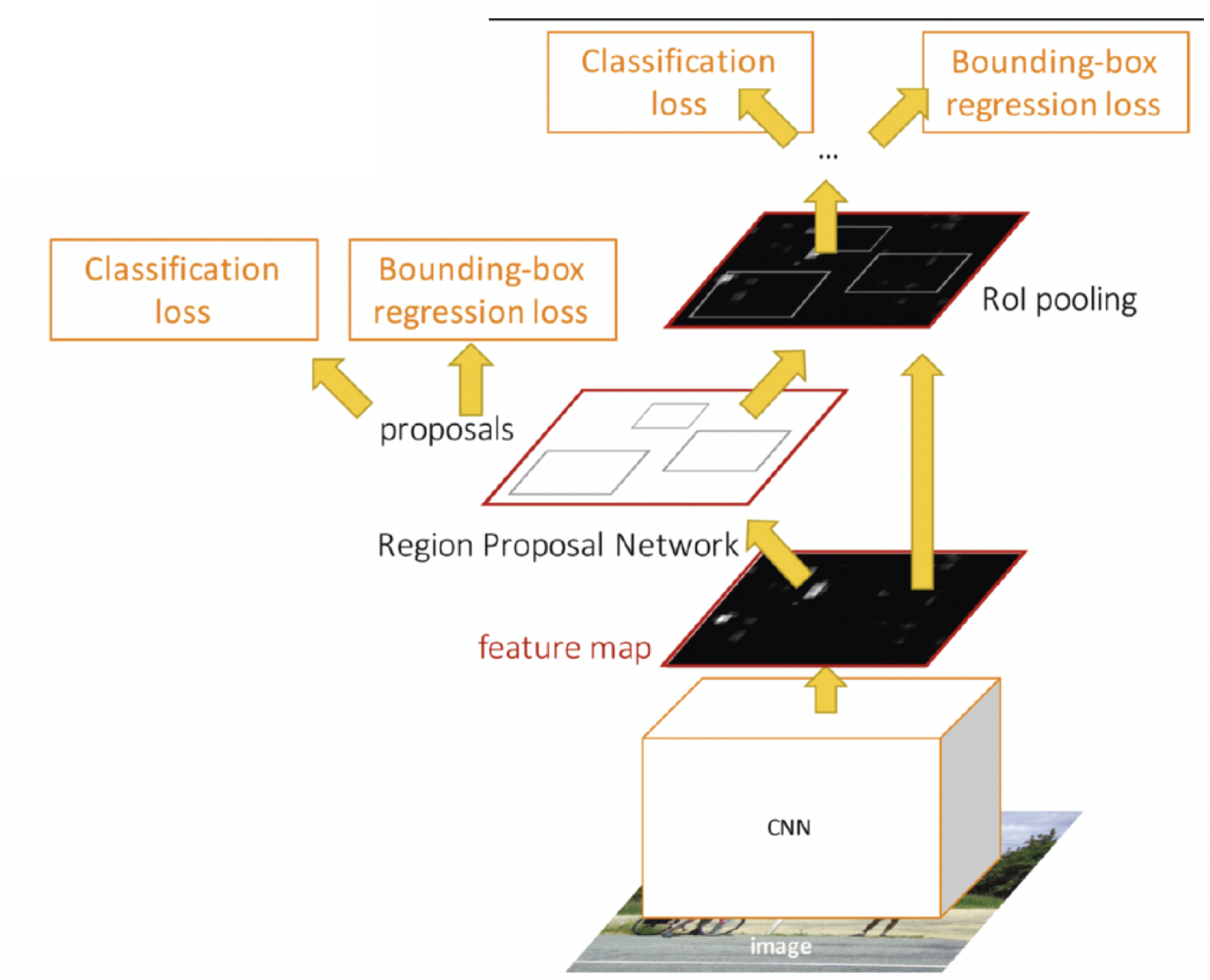
Why two regression losses?
Anchor regression directly impacts the feature used for detection. Detection regression merely improves final localization
Comparison between all the R-CNNs
SSD Detector 4
Motivation
Thus far, deep multiclass detectors rely on variants of three steps:
- generate bounding boxes (proposals)
- resample pixels/features in boxes to uniform size
- apply high quality classifier
Can we avoid / speed up any of those steps to increase overall speed?
Overview
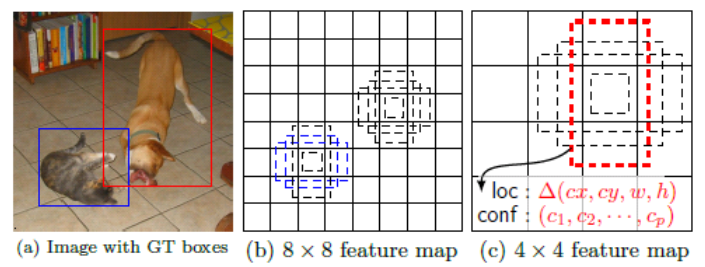
- 💡Core Idea: Use a set of fixed default boxes at each position in a feature map (similar to anchors)
- Classify object class and box regression for each default box
- pply boxes at different layers in the ConvNet
- Use layers of different sizes
- Avoids the need for rescaling
Structure

- Detectors at various stages with varying numbers of default boxes
- Resulting number of detections is fixed
- Reduced by non maximum suppression
Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 580–587. https://doi.org/10.1109/CVPR.2014.81 ↩ ↩︎
Girshick, R. (2015). Fast R-CNN. Proceedings of the IEEE International Conference on Computer Vision, 2015 International Conference on Computer Vision, ICCV 2015, 1440–1448. https://doi.org/10.1109/ICCV.2015.169 ↩ ↩︎
Ren, S., He, K., Girshick, R., & Sun, J. (2017). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6), 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031 ↩ ↩︎
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu: “SSD: Single Shot MultiBox Detector”, 2016; arXiv:1512.02325. ↩︎