Einfache Filter für stark nichtlineare Systeme
Nutzung „einfacher“ Filter für stark nichtlineare Systeme
2 Variante
- Approximation der Zustandsdichten durch Gaussian Mixture $\rightarrow$ Bank von nichtlinearen Kalman Filter für Prädiktion und Filterung
- Approximation aller Dichten durch wertdiskrete Repräsentation $\rightarrow$ Wertdiskreter Filter
Gaussian Mixture Filter
Motivation
Approximation der Zustandsschätzung durch Gaussian Mixture
$$ f(\underline{x})=\sum_{i=1}^{L} w_{i} \mathcal{N}\left(\underline{x}-\underline{\hat{x}}_{i}, C_{i}\right) $$mit
$$ \begin{aligned} &w_{i} \geqslant 0, \quad i \in\{1, \ldots,L\} \\ &\sum_{i=1}^{L} w_{i}=1 \end{aligned} $$(Damit ist Gaussian Mixture für beliebige $L$ eine gültige Dichte)
Parameter
- Gewichtsvektor $\underline{w} = [w_1, \dots, w_L]^T$
- Mittelwerte $\underline{\hat{x}}_1, \dots, \underline{\hat{x}}_L$
- Kovarianzmatrizen $C_1, \dots, C_L$
Gaussian Mixtures sind universelle Approximators. Falls $L$ genügend groß, kann jede Dichte beliebig genau approximiert werden.
Vorgehen
Ziel: Nutzung der Erkenntnisse zum Kalman Filter für schwach nichtlineare Systeme $\rightarrow$ stark nichtlinearer Fall
Deshalb: Individuelle Verarbeitung der einzelnen Komponente $i$ (also Vernachlässigung der Überlappung)
Ergibt Bank von nichtlinearen Kalman Filter, die parallel arbeiten.
Funktioniert besonders gut, wenn
- Überlappung der Komponenten klein
- einzelne Komponenten schmal (induzierte Nichtlinearität)
Prädiktionsschritt
Systemmodell
$$ \underline{x}_{k+1} = \underline{a}_k(\underline{x}_k) + \underline{w}_k $$Einfache Schreiweise:
$$ \underline{z} = \underline{a}(\underline{x}) + \underline{w} \quad \underline{w} \sim \text{Gauß} $$💡Kernidee: Aufspaltung der Chapman-Kolmogorov-Gleichung
$$ \begin{aligned} f^{p}(\underline{z})&=\int_{\mathbb{R}^{N}} f^{w}(\underline{z}-\underline{a}(\underline{x})) \cdot f^{e}(\underline{x}) d \underline{x}\\ &=\int_{\mathbb{R}^{N}} f^{w}(\underline{z}-\underline{a}(\underline{x})) \cdot\left[\sum_{i=1}^{c} w_{i} \mathcal{N} \left(\underline{x}-\underline{\hat{x}}_{i}^{e}, C_{i}^{e}\right)\right] d \underline{x}\\ &=\sum_{i=1}^{L} w_{i} \underbrace{\int_{\mathbb{R}^{N}} f^{w}(\underline{z}-\underline{a}(\underline{x})) \mathcal{N}\left(\underline{x}-\underline{\hat{x}}_{i}^{e}, C_{i}^{e}\right) d \underline{x}}_{\approx \mathcal{N}(\underline{z} - \underline{z}_{i+1}^p, C_{i+1}^p)} \end{aligned} $$Also wir approximieren das Integral einfach mit einem lokalen Posterior für jedes $i$, die wieder Gauß ist, da sie so schmal ist.
$\underline{z}_{i+1}^p, C_{i+1}^p$ durch Anwendung nichtlinearer Kalman Filter
Filterschritt
Messmodell:
$$ \underline{y}_k=\underline{h}_{k}\left(\underline{x}_{k}\right)+\underline{v}_{u} $$Einfache Schreibweise:
$$ \underline{y}=\underline{h}_{k}(\underline{x})+\underline{v} \quad \underline{v} \sim \operatorname{Gauß} $$Filterschritt
$$ \begin{aligned} f^{e}(\underline{x}) &= \underline{c^{e}}_{\text{Normalisierungskonstante}} f^{v}\left(\underline{\hat{y}}-\underline{h}(\underline{x})\right) \cdot \sum_{i=1}^{L} w_{i} \mathcal{N}\left(\underline{x}-\hat{\underline{x}}_{i}^{p}, C_{i}^{p}\right) \\ &=c^{e} \sum_{i=1}^{L} w_{i} \underbrace{f^{v}(\underline{\hat{y}}-\underline{h}(\underline{x})) \cdot \mathcal{N} \left(\underline{x}-\underline{\hat{x}}_{i}^{p}, C_{i}^{p}\right)}_{\approx k_i \mathcal{N} \left(\underline{x}-\underline{\hat{x}}_{i}^{e}, C_{i}^{e}\right)} \\ &= c^e \sum_{i=1}^{L} w_{i} k_i \mathcal{N} \left(\underline{x}-\underline{\hat{x}}_{i}^{e}, C_{i}^{e}\right) \end{aligned} $$$\underline{\hat{x}}_{i}^{e}, C_{i}^{e}$ durch nichtlinearen Kalman Filter bestimmen.
Rasterbasierte Filter
Rasterbasierte Repräsentation von Dichten
Zunächst: Skalarer Fall
Gegeben: Dichte $f(x), x \in \mathbb{R}$
Gescuht: Wertdiskrete Repräsentation
$$ \underline{\eta} \in \mathbb{R}_{+}^{L}, \quad \underline{\mathbf{1}}^{\top} \cdot \underline{\eta}=1 \text{ (Normalisierung)} $$
Rasterbasierter Filter- und Prädiktionsschritt
 $$
\underline{\eta}=\left[\begin{array}{c}
\eta
_{1} \\
\eta
_{2} \\
\vdots \\
\eta
_{L}
\end{array}\right]
$$
$$
\underline{\eta}=\left[\begin{array}{c}
\eta
_{1} \\
\eta
_{2} \\
\vdots \\
\eta
_{L}
\end{array}\right]
$$Annahme: Repräsentiere $\eta_i$ in Mitte jedes Intervalls durch Dirac’sche Deltafunktion
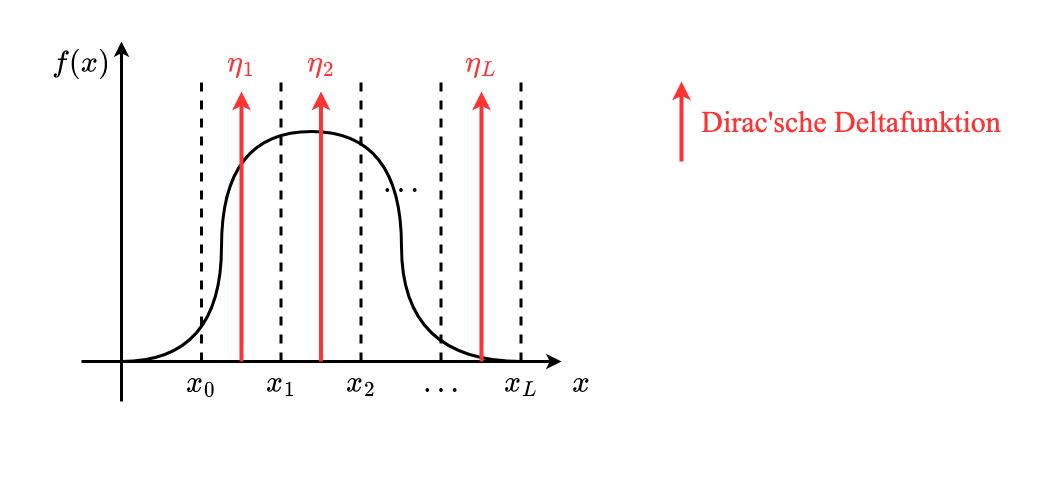
Kriterium: Integralwerte sollen gleich sein.
$$ \begin{aligned} &\int_{x_{i-1}}^{x_i}f(x)dx \overset{!}{=} \underbrace{\int_{x_{i-1}}^{x_i} \eta_i \cdot \delta(x - \frac{x_i + x_{i-1}}{2}) dx}_{=\eta_i} \\ &\Rightarrow \eta_i \propto \int_{x_{i-1}}^{x_i}f(x)dx \quad i \in \{1, \dots, L\} \end{aligned} $$Normalisierung erfordlich:
$$ \eta_{i}:=\frac{\eta_{i}}{\sum_{i} \eta_{i}} \quad i \in\left\{1, \dots, L\right\} $$In vielen Fällen, Integral über $f(x)$ nicht analytisch lösbar. $\Rightarrow$ Integration zu aufwändig.
Alternative: Stückweise Konstant Approximation von $f(x)$
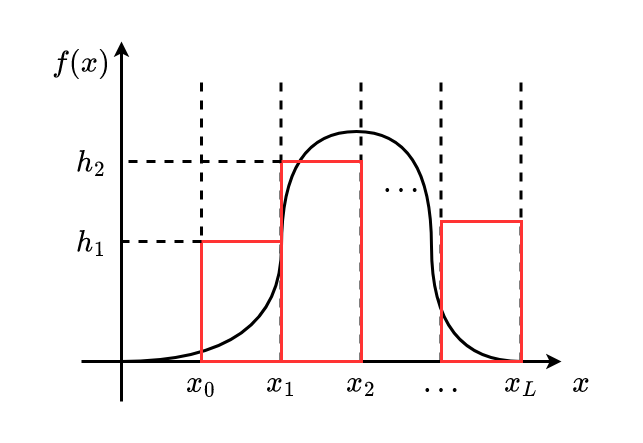
Aber: Optimaler Vergleich erfordert auch Integration
Deshalb: Verwendung des Dichtwerts an Stelle
$$ h_i = f(\frac{x_i + x_{i-1}}{2}) $$Damit
$$ \begin{aligned} &\int_{x_{i-1}}^{x_i} f(x) dx \approx \int_{x_{i-1}}^{x_i} h_i dx = h_i(\underbrace{x_i - x_{i-1}}_{=\Delta}) \\ & \Rightarrow \eta_i \propto \Delta \cdot h_i = \Delta \cdot f(\frac{x_i + x_{i-1}}{2}) \end{aligned} $$mit Normalisierung
Rasterbasierter Filterschritt
Generatives Modell
$$ y = h(x, v) $$Kovertiere in probabilitisches Modell $f(y \mid x)$
Messung $\hat{y}$ sidn nicht wertdiskret $\rightarrow$ Quantisierung von $f(\hat{y} \mid x) = f^L(x)$
Da $f(\hat{y} \mid x)$ i.d.R. nicht analytisch integrierbar $\rightarrow$
$$ \eta_{i}^{L} \propto \Delta f^{L}\left(\frac{x_{i}+x_{i-1}}{2}\right) \quad i \in\{1, \dots,L\} $$und Normalisierung.
Für gegebene Dichte $\underline{\eta}^{p}=\left[\eta_{1}^{p}, \eta_{2}^{p}, \ldots, \eta_{L}^{p}\right]^{\top}$
$$ \underline{\eta}^{e} \propto \underline{\eta}^{L} \odot \underline{\eta}^{p} \tag{posteriore Verteilung} $$Rasterbasierter Prädiktionsschritt
Generatives Modell
$$ x_{k+1} = a_k(x_k, w_k) $$Einfache Schreibweise
$$ z = a(x, w) $$probabilitisches Modell: $f(z \mid x)$
Hier müssen wir für skalare Zustände eine 2D-Dichte quantisieren.
$\Rightarrow$ Es ergibt sich eine Matrix
 $$
A_{i j} \propto f\left(\frac{z_{j}+z_{j-1}}{2}, \frac{x_{i}+x_{i-1}}{2}\right)
$$
$$
A_{i j} \propto f\left(\frac{z_{j}+z_{j-1}}{2}, \frac{x_{i}+x_{i-1}}{2}\right)
$$Normalisierung
- Es handelt sich um Transitionsmatrix
- Stochastische Matrix, Zeilensumme = 1
- $A_{i j}:=\displaystyle\frac{A_{i j}}{\sum_{i=1}^{L} A_{i j}}, i \in\{1, \ldots,L\}$
Gegeben:
- Transitionsmatrix $A \in \mathbb{R}_{+}^{L \times L}$
- Schätzung aus letzen Filterschritt $\underline{\eta}^e \in \mathbb{R}_{+}^{L}$
Ergebnis des Prädiktionsschritts:
$$ \underline{\eta}^p = A^\top \underline{\eta}^e $$Aufwändiger als Filterschritt 🤪
Erweiterung Prädiktionsschritt
Bisher angenommen: Raster für $z$ (also $x_{k+1}$) schon bekannt/fest
Das ist leider nicht praxisgerecht, da sich Wertbereich aus Abbildung ergibt.
Speizialfall: Lineares System mit additives Rauschen (i. Allg. schwieriger)
$$ z = \underbrace{x + u}_{z^\prime} + w \quad w \sim f^w(w) $$Zwischengröße $z^\prime$: Nutze Eingang $\hat{u}$, um Raster zu verschieben (bewegliches Raster)
$$ z_i^\prime = x_i + \hat{u} \quad i \in \{1, \dots, L\} $$Wir setzen $z_i = z_i^\prime$
Danach Faltung mit $f_w(w)$:
$$ fz\left(z^{\prime}\right)=f^{w}\left(z-z^{\prime}\right) $$Dann Quantisierung von $f(z \mid z^\prime) \Rightarrow$
$$ \begin{aligned} A_{i j} &=f^{w}\left(\frac{z_{j}+z_{j - 1}}{2} \mid \frac{z_{i}^{\prime}+z_{i - 1}^\prime}{2}\right) \\ A_{i j}&=f^{\omega}\left(\frac{1}{2}\left[z_{i}+z_{j-1}-\left(z_{i}^{\prime}+z_{i-1}^{\prime}\right)\right]\right) \end{aligned} $$Wir wissen
$$ \begin{aligned} \frac{z_{i}+z_{j-1}}{2}&=\frac{2 j-1}{2} \Delta+z_{0} \\ \frac{z_{i}^{\prime}+z_{i-1}^{\prime}}{2}&=\frac{z_{i}-1}{2} \Delta+z_{0}^{\prime} \\ \Rightarrow A_{ij} &= f^w(\Delta[j - i]), \text{ falls } z_0 = z_0^\prime \Rightarrow j - i \in \{-(L-1), \dots, -1, 0, 1, \dots, L - 1\} \end{aligned} $$Vorabdiskretisierung von $f^w(\cdot)$
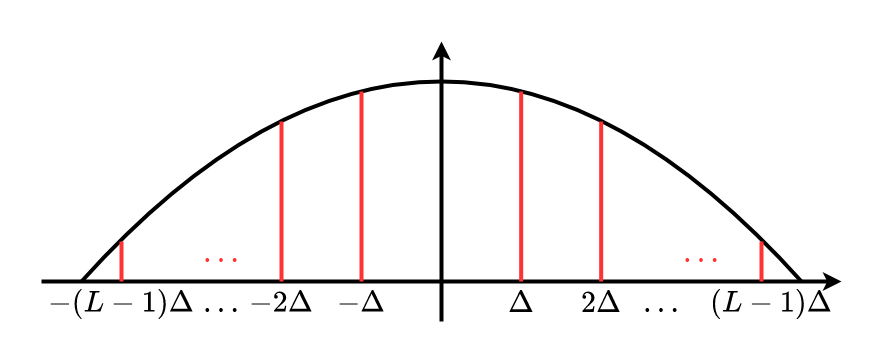
Eintragen der Werte in Transitionsmatrix $A$ mit $A_{ij} = f^w(\Delta(j-i))$
Dann Berechnung der Posteriro wie gehabt.
Rekonstruktion kontinuierlicher Dichten
Ergebnis von Prädiktion und Filterung in wertdiskreter Form $\underline{\eta} \in \mathbb{R}_+^L$
Berechnung von Kenngröße einfach, dazu Positionen erforderlich
Erwartungswert
$$ \begin{aligned} \hat{x} &=\int_{\mathbb{R}} x \sum_{i=1}^{2} \eta_{i} \int\left(x-\frac{x_{i}+x_{i-1}}{2}\right) d x \\ &=\sum_{i=1}^{L} \eta_{i} \frac{x_{i}+x_{i-1}}{2} \quad \mid \frac{x_{i}+x_{i-1}}{2}=\frac{2 i-1}{2} \Delta+x_{0} \\ &= \sum_{i=1}^{L} \eta_{i} (\frac{2i-1}{2} \Delta + x_0) \end{aligned} $$Analog für Varianz.
Gesucht: kontinuierliche Rekonstruktion $f(x)$ aus $\eta$
Als Dirac Mixture
$$ f(x) \approx \sum_{i=1}^{L} \eta_{i} \delta\left(x-\frac{x_{i}+x_{i-1}}{2}\right) $$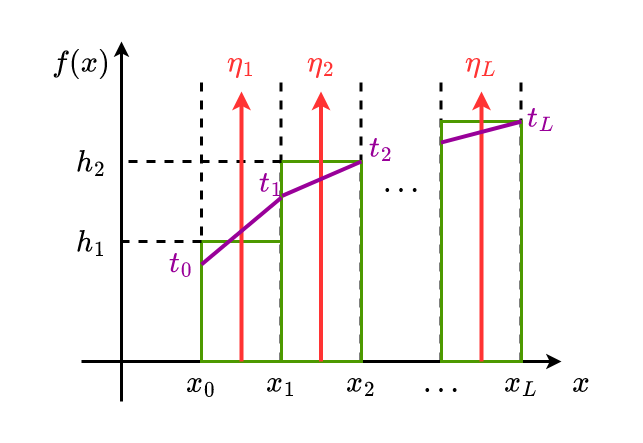
Verschiedenen Möglichkeiten der Interpolation
Stückweise Konstante Interpolation
$$ \int_{x_{i-1}}^{x_{i}} h_{i} d x \overset{!}{=} \int_{x_{i=1}}^{x_{i}} u_{i} \delta() d x \Rightarrow h_{i}=\frac{\eta_{i}}{\Delta} $$Stetige, stückweise lineare Interpolation
$$ (t_i + t_{i-1}) \frac{\Delta}{2} = \eta_i $$und weitere Bedingung
$$ t_0 = t_1 $$
Erweiterungen
Mehrdimensional Fall: $\underline{x} \in \mathbb{R}^N$
- Filterschritt analog
- Prädiktionsschritt: $f(\underline{z} \mid \underline{x})$ nun von $\mathbb{R}^N$aud $\mathbb{R}^N \Rightarrow A \in \mathbb{R}^{2N}$
Lösung
- Bewegliches Raster für nichtlineare Systemmodelle
- Adaptive Auflösung eines äquidistanten / homogenen Rasters
- Inhomoge Raster $\rightarrow$ variable Auflösung
- Effiziente Implementierung, z.B. dünn besetzte Matrizen ($0$ nicht explizit dargestellt)