Partikel Filter
Naives Partikelfilter
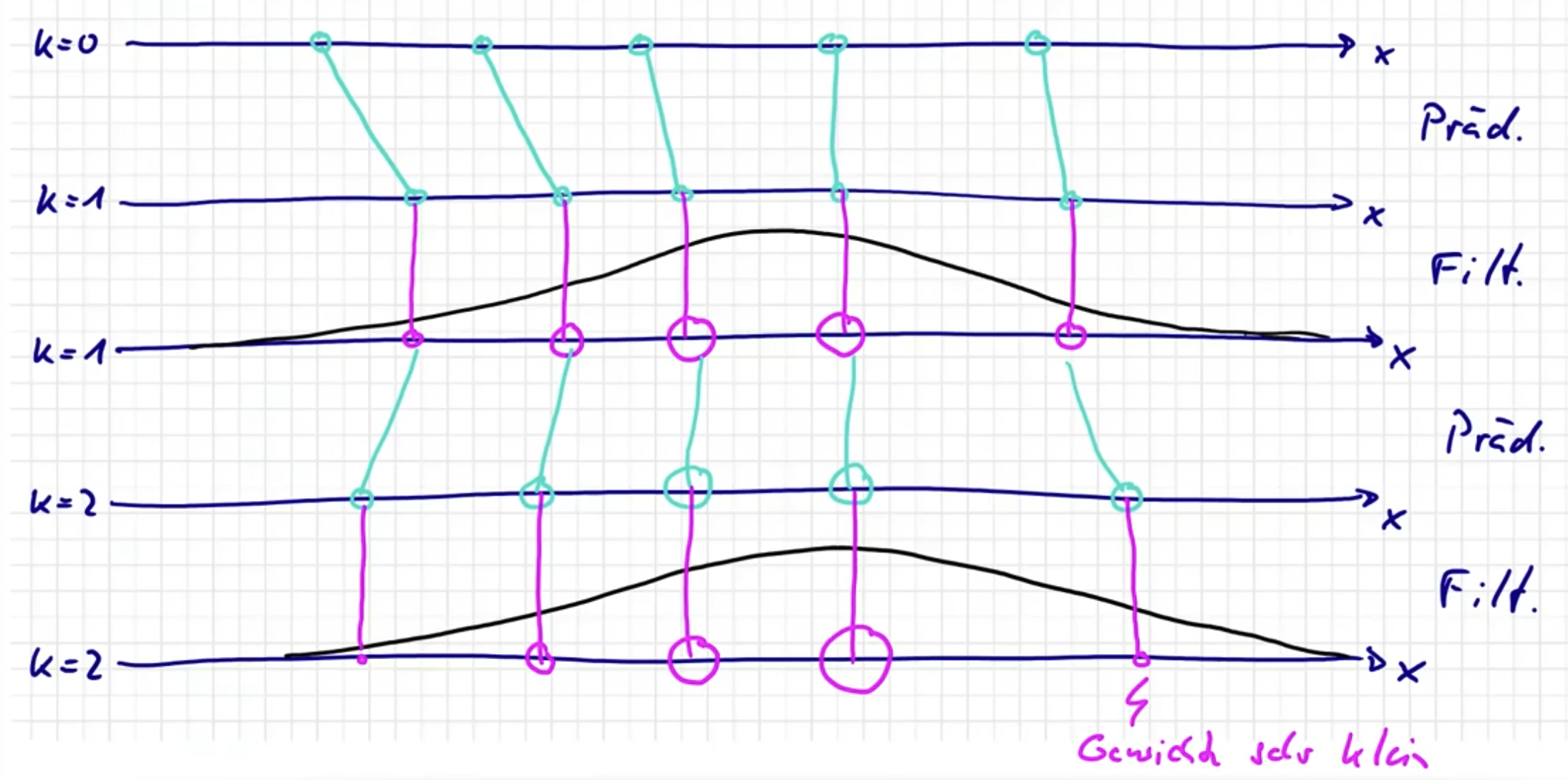
Prädiktions- und Filterschritt
Prädiktionsschritt
Zum Startzeitpunkt (z.B. $k=0$): Initiale Samples gegeben
$$ f_{k}^{e}\left(\underline{x}_{k}\right)=\sum_{i=1}^{L} w_{k}^{e, i} \cdot \delta\left(\underline{x}_{k}-\underline{\hat{x}}_{k}^{e, i}\right) \qquad w_{k}^{e, i}=\frac{1}{L}, i \in\left\{1, \ldots, L\right\} $$Prädiktion mithilfe des probabilistischen Systemmodells $f(\underline{x}_{k+1} \mid \underline{x}_k)$
Ziehe Samples zum Zeitpunkt $k+1$
$$ \underline{\hat{x}}_{k+1}^{p, i} \sim f\left(\underline{x}_{k+1} \mid \hat{x}_{k}^{e, i}\right) $$Gewichte bleiben gleich
$$ w_{k+1}^{p, i} = w_{k}^{e, i} $$
$\Rightarrow$
$$ f_{k+1}^{p}\left(\underline{x}_{k+1}\right)=\sum_{i=1}^{L} w_{k+1}^{p, i} \delta\left(\underline{x}_{k+1}-\underline{\hat{x}}_{k+1}^{p, i}\right) $$Bei gegebenen geschriebenen Systemmodell
$$ \underline{x}_{k+1} = \underline{a}_k(\underline{x}_k, \underline{w}_k) $$- Ziehe $\underline{w}_k^i \sim f_k^w(\cdot)$
- $\underline{\hat{x}}_{k+1}^{p, i}=\underline{a}_{k}\left(\underline{\hat{x}}_{k}^{e, i}, \underline{w}_{k}^{i}\right), i \in\left\{1, \ldots,L\right\}$
Filterschritt
Filterung mithilfe des probabilistischen Messmodells $f(\underline{y}_k \mid \underline{x}_k)$, falls Messung verfügbar.
Messupdate
$$ \begin{aligned} f_{k}^{e}\left(\underline{x}_{k}\right) &\propto f\left(\underline{y}_{k} \mid \underline{x}_{k}\right) \cdot f_{k}^{p}\left(\underline{x}_{k}\right)\\ &=f\left(\underline{y}_{k} \mid \underline{x}_{k}\right) \cdot \sum_{i=1}^{L} w_{k}^{p, i} \cdot \delta\left(\underline{x}_{k}-\underline{\hat{x}}_{k}^{p, i}\right)\\ &=\sum_{i=1}^{L} \underbrace{w_{k}^{p, i} \cdot f\left(\underline{y}_{k} \mid \hat{\underline{x}}_{k}^{p, i}\right)}_{\propto w_{k}^{e, i}} \cdot \delta(\underline{x}_{k}-\underbrace{\underline{\hat{x}}_{k}^{p, i}}_{\underline{\hat{x}}_{k}^{e, i}}) \end{aligned} $$Positionen bleiben gleich
$$ \underline{\hat{x}}_{k}^{e, i} = \underline{\hat{x}}_{k}^{p, i} $$Gewichte werden adaptiert
$$ w_{k}^{e, i} \propto w_{k}^{p, i} \cdot f\left(\underline{y}_{k} \mid \hat{\underline{x}}_{k}^{p, i}\right) $$Normalisierung erforderlich
$$ w_{k}^{e, i}:=\frac{w_{k}^{e, i}}{\displaystyle \sum_{i} w_{k}^{e,i}} $$
Ablauf
Gewichte sind repräsentiert mit Kreise.
Vor- und Nachteile
👍 Vorteile
- Problemlose Behandlung vom nichtlinearen System- und Messmodellen
- Einstellbare Genauigkeit und Rechenaufwand nach Anzahl der Partikel balancieren
- Extreme einfache Implementierung
👎 Nachteile
- Varianz der Samples erhöht sich mit Filterschritten
- Partikel sterben aus $\rightarrow$ Degenerierung des Filters
- Aussterben schneller, je genauer die Messung, da Likelihood schmaler ($\rightarrow$ Paradox!)
Verbesserungen
Resampling
Maßnahme zur Veringerung der Varianz der Samples
Approximation der gewichteter Samples durch ungewichtete
$$ f_{k}^{e}\left(\underline{x}_{k}\right)=\sum_{i=1}^{L} w_{k}^{e, i} \cdot \delta\left(\underline{x}_{k}-\underline{\hat{x}}_{k}^{e, i}\right) \approx \sum_{i=1}^{L} \frac{1}{L} \delta\left(\underline{x}_{k}-\underline{\hat{\hat{x}}}_{k}^{e, i}\right) $$$\underline{\hat{\hat{x}}}_{k}^{e, i}$ : i.d.R nicht die gleiche Orte wie $\underline{\hat{x}}_{k}^{e, i}$
Sehr einfaches Verfahren
- Verwerfen von Samples mit kleinen Gewichten
- Duplizieren von Samples mit hohen Gewichten proportional zu $w_i$ (importance resampling)
Positionen der Samples nicht verändert
- Veränderung der Position erst im nachfolgenden Prädiktionsschritt
Partikelfilter mit Resampling
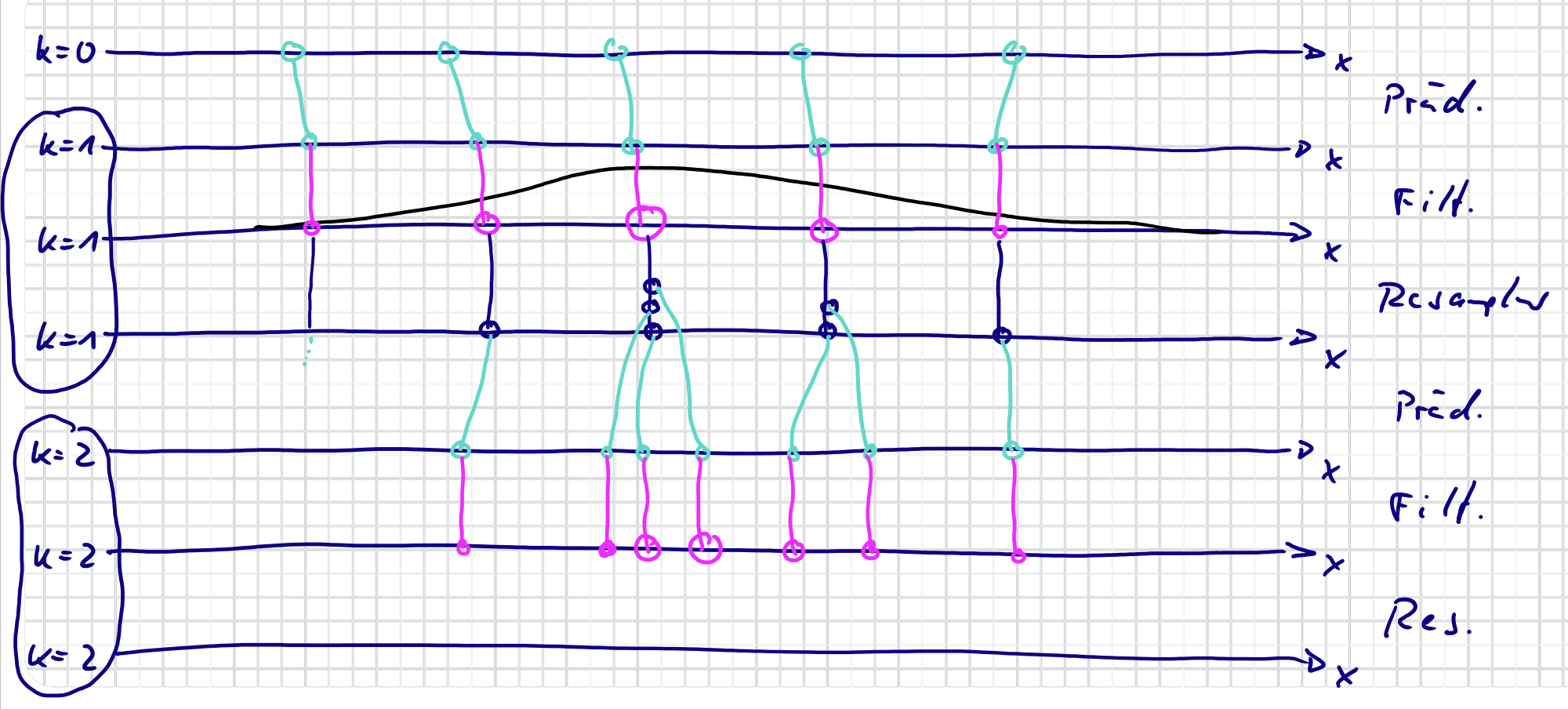
- Fangen mit Samples der gleichen Gewichte an
- In $k=1$
- Propagieren durch Prädiktionsschritt. Die Orte werden verändert, während die Geweichte gleich bleiben.
- In Filterschritt, verändert die Gewichte. Orte bleiben gleich.
- Die größeren Sample werden repliziert. Die ganz kleinere werden weg.
Verschiedene Techniken für Resampling
Gegeben: $L$ Partikel mit Gewichten $w_i$
Gesucht: $L$ Partikel mit Geweichte $\frac{1}{L}$ (gleichgewichtet)
Achtung
- Hier nur Vervielfältigung
- Positionen der Partikel unverändert
Kann als Kategoriale Verteilung gesehen werden
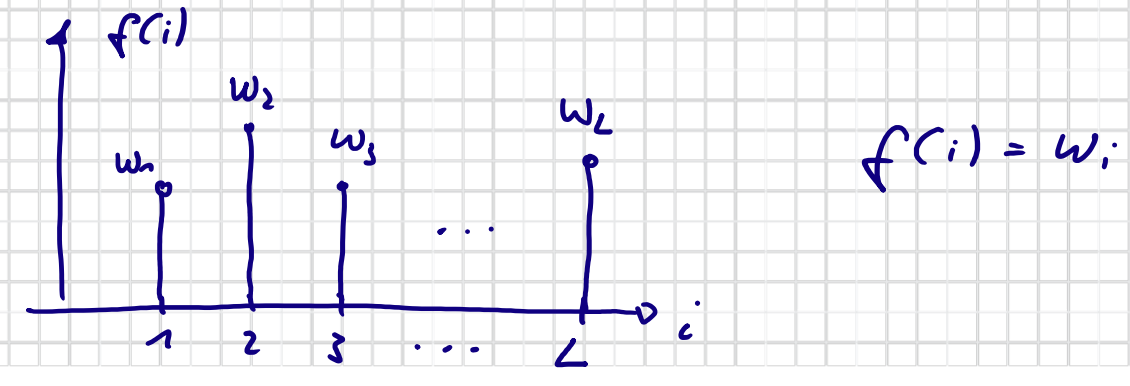
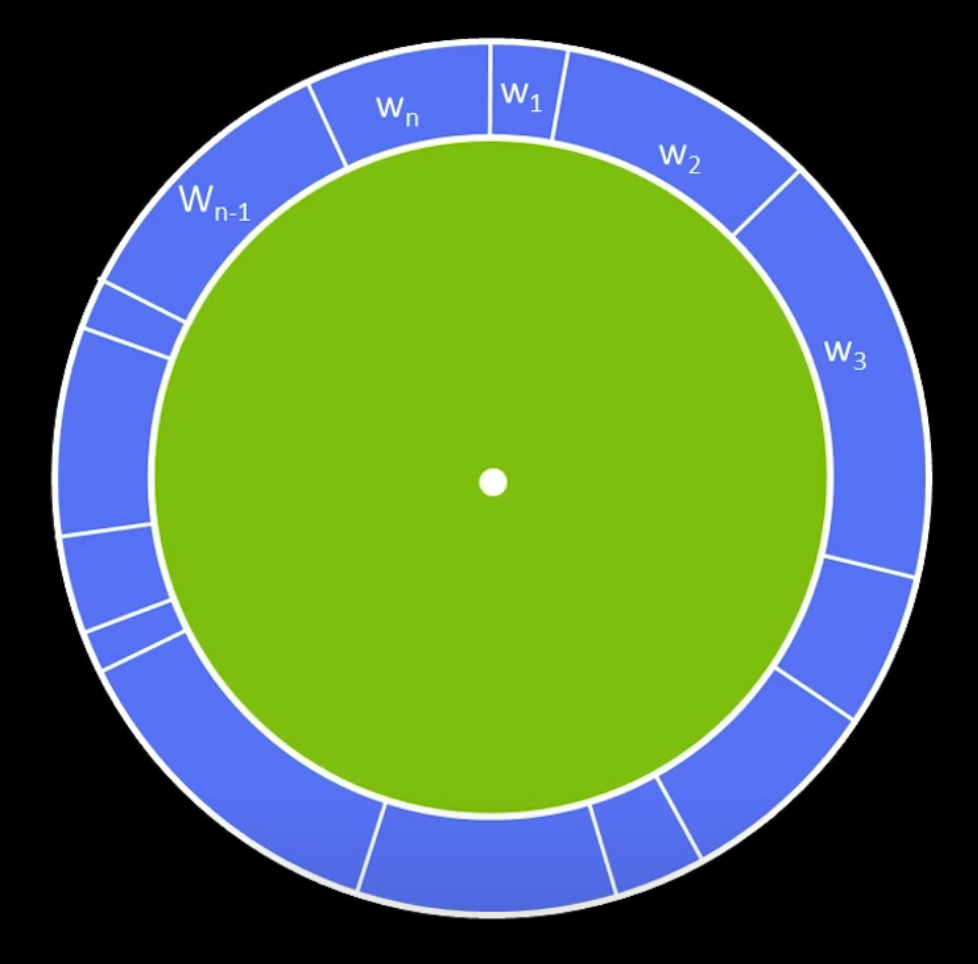
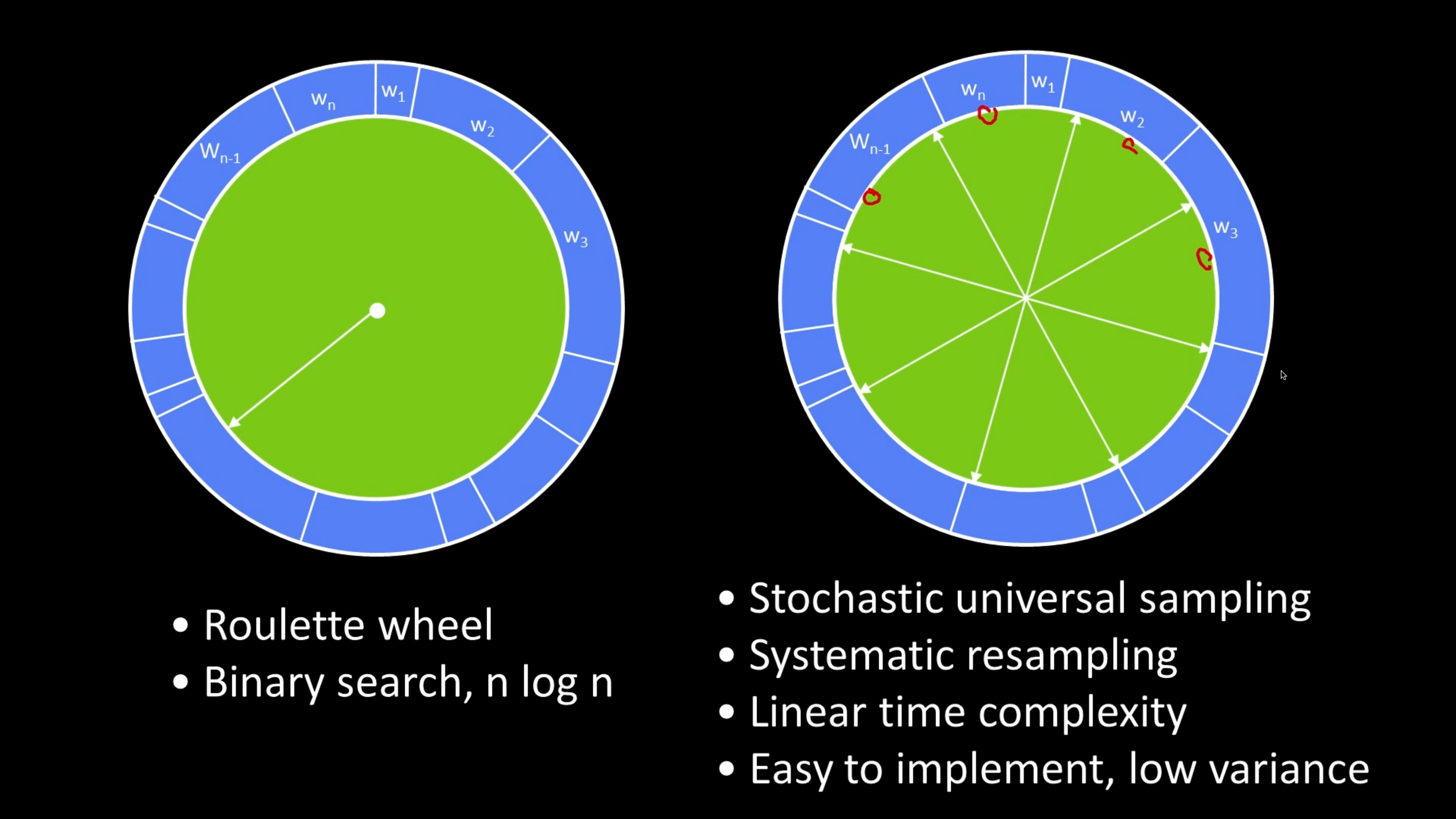
Rouletterad
Resampling proportional zu der Gewichten $w_i$
Betrachtung der kumulative Verteilung $F(i)$
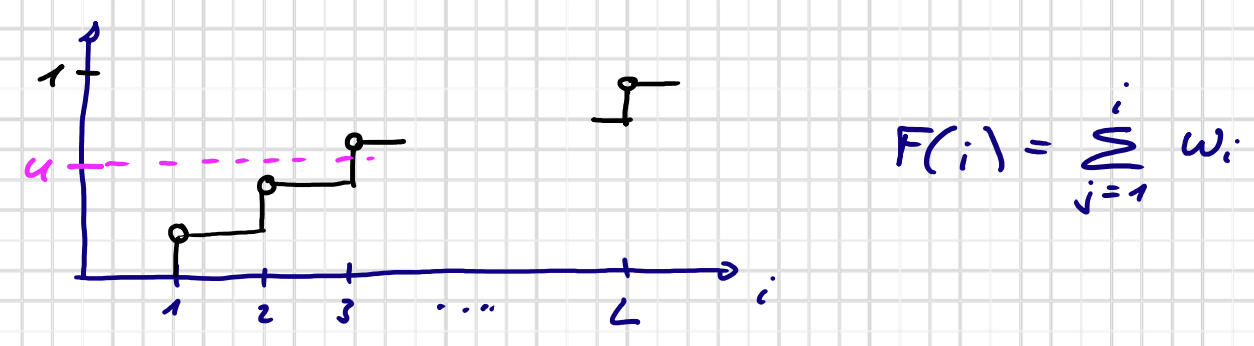
Ziehe $L$-mal Zufallszahl $u$ und wähle größte $i$ mit $F(i) \leq u$
Entspricht Auswahl mit Rouletterad (z.B. hier $L=5$)

Problem
- Sehr kleine Gewichte nicht ausreichend proportional gezogen werden.
- Man bevorzugt ganz große Gewichte.
Given: Set $S$ of weighted samples
Wanted: Random sample, where the probability of drawing $x_i$ is given by $w_i$
Typically done $n$ times with replacement to generate new sample set $S^\prime$
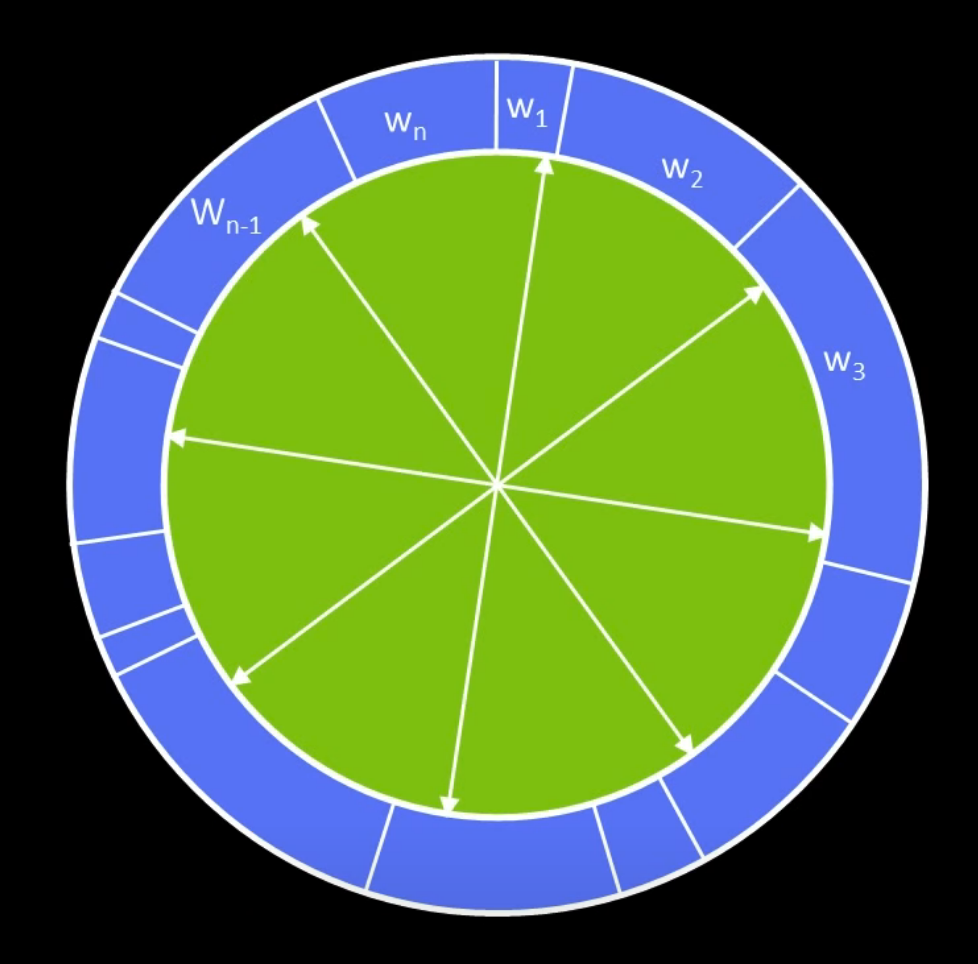
We have a roulette ring, where the arc length is proportional to the weight.
We can think of the sampling as following:
We just randomly pick a direction. If I hit $w_3$, then I will take sample Nr. 3
And repeat this for $n$ times.
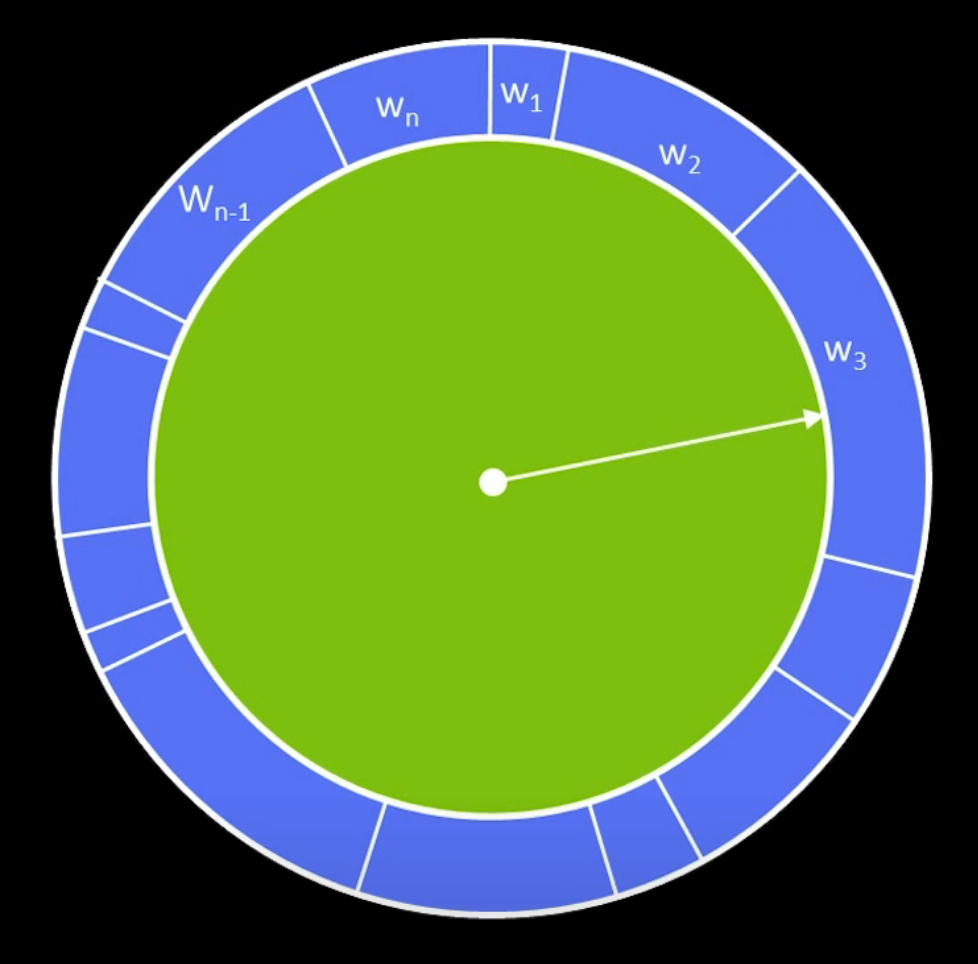
Stochastic Universal Sampling
Bisher
- starkes Rauschen $\rightarrow$ Auswahl variiert stark
- Bevorzugung großer Gewichte
Daher: Determistisches Auswahl
Randomisierung durch einmaliges Ziehen von $\epsilon \in [0, \frac{1}{2}]$
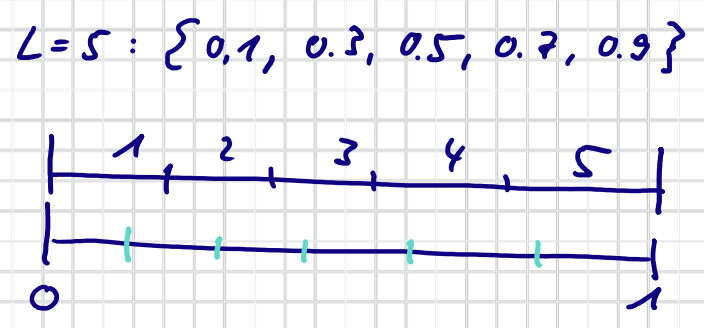
$$ u_i = \frac{i}{L} - \epsilon \qquad i \in \{1, \dots, L\} $$Für $\epsilon = \frac{1}{2L}$:
$$ u_i = \frac{2i - 1}{2L} $$
Bsp: $L=5$
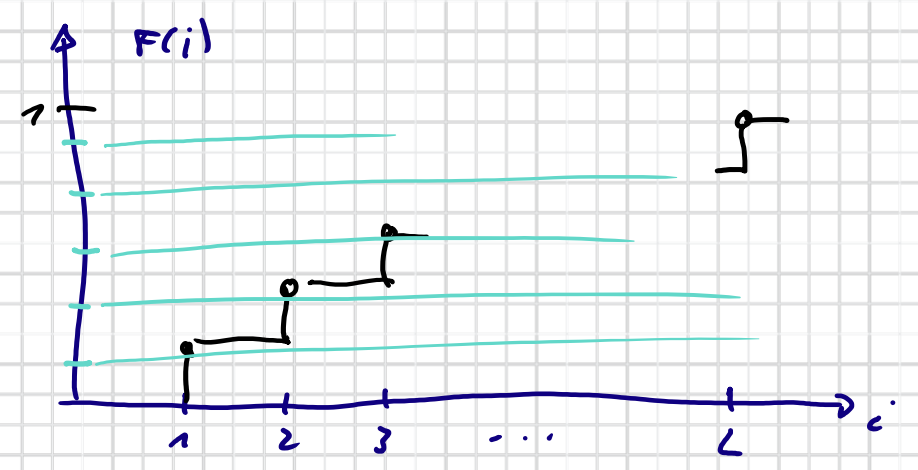
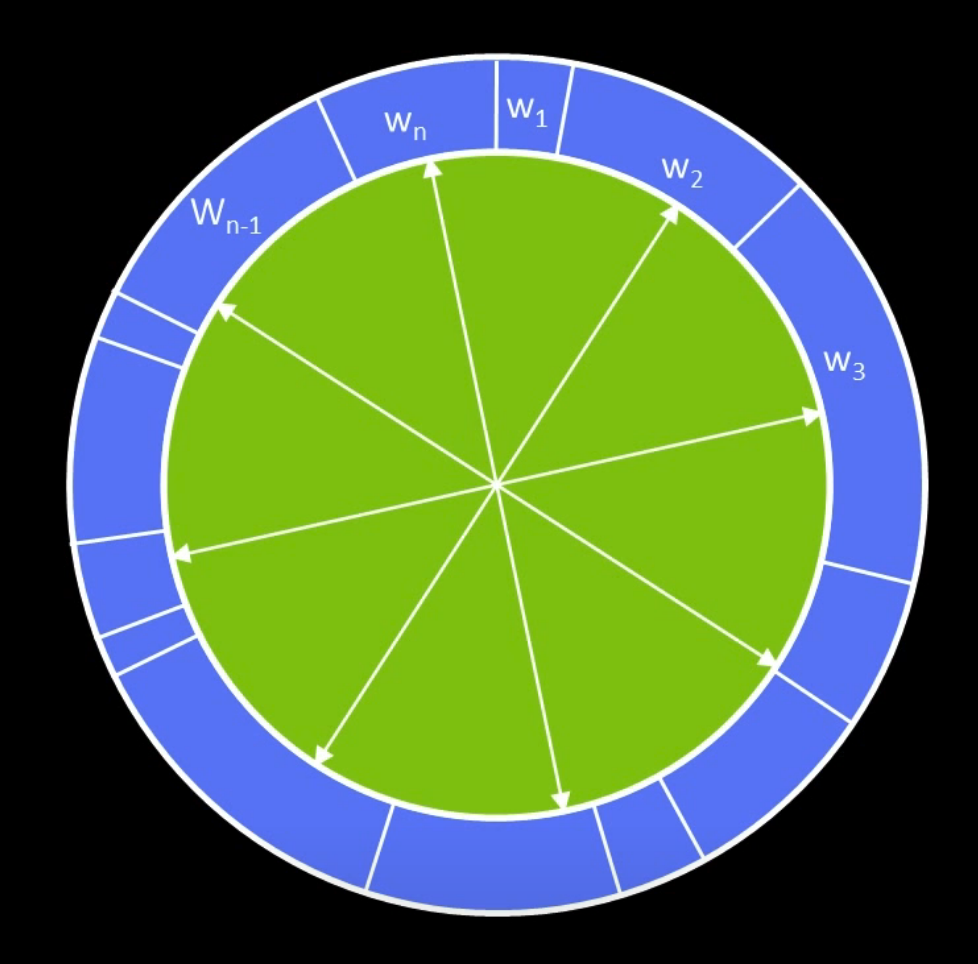
We model the roulette wheel like a wagen wheel:
We can make a set of spokes that are $\frac{1}{n}$ full rotation around.
We can randomly put it down someplace, and read off, which $w$ did each spoke hit.
Compared to roulette wheel:
Importance Sampling
🎯 Ziel: Berechung des Integrals
$$ E = \int_{\mathbb{R}^N} g(\underline{x}) f(\underline{x}) d\underline{x} $$$E$: Erwartungswert
$g(\underline{x})$ : nichtlineare Funktion
$f(\underline{x})$ : Verteilungsdichte
Falls Samples von $f(\underline{x})$ verfügbar:
$$ E=\int_{\mathbb{R}^{N}} g(\underline{x}) \sum_{i=1}^{L} w_{i} \cdot \delta\left(\underline{x}-\underline{\hat{x}}_{i}\right) d \underline{x}=\sum_{i=1}^{L} w_{i} g(\underline{x}_i) $$Aber: Oft Sampling von $f(\underline{x})$ nicht möglich 🤪
Abhilfe: Proposal distribution (a.k.a instrumental distribution, importance distribution) $p(\underline{x})$ mit
$$ \operatorname{supp}\{f(\cdot)\} \subset \operatorname{supp}\{p(\cdot)\} $$($\operatorname{supp}$ steht für support)
d.h. $p(\underline{x}) > 0$ falls $f(\underline{x}) > 0$.
Für $p(\underline{x})$ müssen wir so auswählen, dass Sampling von $p(\underline{x})$ einfach ist (z.B. Gaußdichte).
Einsetzen:
$$ E=\int_{\mathbb{R}^{N}} g(\underline{x}) \cdot \frac{p(\underline{x})}{p(\underline{x})} \cdot f(\underline{x}) d \underline{x}=\int_{\mathbb{R}^{N}} g(\underline{x}) \cdot \frac{f(\underline{x})}{p(\underline{x})} \cdot p(\underline{x}) d \underline{x} $$Jetzt würden wir nicht $f(\underline{x})$ in eine Dirac Mixture entwickeln, sondern $p(\underline{x})$ . Davon können wir samplen.
$$ p(\underline{x}) \approx \sum_{i=1}^{L} w_{i} \cdot \delta\left(\underline{x}-\underline{\hat{x}}_{i}\right) $$ $$ \begin{aligned} \Rightarrow E &\approx \int_{\mathbb{R}^{N}} g(\underline{x}) \cdot \frac{f(\underline{x})}{p(\underline{x})} \cdot \sum_{i=1}^{L} w_{i} \delta\left(\underline{x}-\underline{\hat{x}}_{i}\right) d \underline{x} \\\\ &= \sum_{i=1}^{L} g(\underline{\hat{x}}_{i}) \cdot \underbrace{\frac{f(\underline{\hat{x}}_i)}{p(\underline{\hat{x}}_{i})} \cdot w_i}_{=: w_{i}^\prime} \\\\ &= \sum_{i=1}^{L} w_{i}^\prime \cdot g(\underline{\hat{x}}_{i}) \end{aligned} $$Konvergenz gegen $E$ für $L \to \infty$
I.e. Wir teilen den Ausdruck so auf, dass wir Sample $\underline{\hat{x}}_i$ von der Proposal $p(\underline{x})$ sampeln und ihr ursprüngliches Gewicht $w_i$ mit “Importance” $\frac{f(\underline{\hat{x}}_i)}{p(\underline{\hat{x}}_{i})} $ anpassen.
Sequential Importance Sampling
Vor-positionierung von Samples
🎯 Ziel: Systematische und korrekte Positionierung der Samples an Stellen hoher Likelihood vor Filterschritt
- Verwendung von Proposal statt Systemmodell $f(\underline{x}_{k+1} \mid \underline{x}_k)$
💡Idee: Importance Sampling für $f(\underline{x}_k, \underline{x}_{k-1} \mid \underline{y}_{1:k})$ (die Messung wird auch in Berücksichtigung genommen)
$$ f_{k}^{e}\left(\underline{x}_{k}\right)=f\left(\underline{x}_{k} \mid \underline{y}_{1: k}\right)=\int_{\mathbb{R}^{N}} \cdots \int_{\mathbb{R}^{N}} f\left(\underline{x}_{1: k} \mid \underline{y}_{1 : k}\right) d \underline{x}_{1: k-1} $$Proposal: $p\left(\underline{x}_{1: k} \mid \underline{y}_{1 : k}\right)$ hängt auch von $\underline{y}_k$ ab.
Damit:
$$ f_{k}^{e}\left(\underline{x}_{k}\right) = \int_{\mathbb{R}^{N}} \cdots \int_{\mathbb{R}^{N}} \underbrace{\frac{f\left(\underline{x}_{1: k} \mid \underline{y}_{1 : k}\right)}{p\left(\underline{x}_{1: k} \mid \underline{y}_{1 : k}\right)}}_{=: w_k^{e, i}} p\left(\underline{x}_{1: k} \mid \underline{y}_{1 : k}\right) d \underline{x}_{1: k-1} $$Annahme: Proposal ist faktorisierbar
$$ p\left(\underline{x}_{1: k} \mid \underline{y}_{1: k}\right)=p\left(\underline{x}_{k} \mid \underline{x}_{1: k - 1}, \underline{y}_{1: k}\right) \cdot p\left(\underline{x}_{1: k -1} \mid \underline{y}_{1: k - 1}\right) $$Für gegebenes Sample $\underline{\hat{x}}_{k-1}^{e, i}$ aus letzten Zeitpunkt, ziehe
$$ \underline{x}_{k}^{e, i} \sim P\left(\underline{x}_{k} \mid \hat{\underline{x}}_{k-1}^{e, i}, \underline{y}_{k}\right) $$Jetzt umschreiben von $\frac{f\left(\underline{x}_{1: k} \mid \underline{y}_{1 : k}\right)}{p\left(\underline{x}_{1: k} \mid \underline{y}_{1 : k}\right)}$
Zähler
$$ \begin{aligned} f\left(\underline{x}_{1: k} \mid \underline{y}_{1: k}\right) &\propto f\left(\underline{y}_{k} \mid \underline{x}_{1: k}, \underline{y}_{1: k - 1}\right) \cdot f\left(\underline{x}_{1: k} \mid \underline{y}_{1: k-1}\right)\\ &=f\left(\underline{y}_{k} \mid \underline{x}_{k}\right) \cdot f\left(\underline{x}_{k} \mid \underline{x}_{1:k-1}, \underline{y}_{1:k-1}\right) \cdot f\left(\underline{x}_{1:k-1} \mid \underline{y}_{1: k-1}\right)\\ &=f\left(\underline{y}_{k} \mid \underline{x}_{k}\right) \cdot f\left(\underline{x}_{k} \mid \underline{x}_{k-1}\right) \cdot f\left(\underline{x}_{1: k-1} \mid \underline{y}_{1: k \cdot 1}\right) \end{aligned} $$Nenner
$$ p\left(\underline{x}_{1: k} \mid \underline{y}_{1: k}\right)=p\left(\underline{x}_{k} \mid \underline{x}_{1: k - 1}, \underline{y}_{1: k}\right) \cdot p\left(\underline{x}_{1: k -1} \mid \underline{y}_{1: k - 1}\right) $$
$\Rightarrow$ Gewicht für Position $i$:
$$ w_k^{e, i} = \frac{f\left(\underline{\hat{x}}_{1: k} \mid \underline{y}_{1 : k}\right)}{p\left(\underline{\hat{x}}_{1: k} \mid \underline{y}_{1 : k}\right)} \propto \frac{f\left(\underline{y}_{k} \mid \underline{x}_{k}^i\right) \cdot f\left(\underline{x}_{k}^i\mid \underline{x}_{k-1}^i\right)}{p\left(\underline{x}_{k}^i \mid \underline{x}_{1: k - 1}^i, \underline{y}_{1: k}\right)} \cdot \underbrace{\frac{f\left(\underline{x}_{1: k-1}^i \mid \underline{y}_{1: k \cdot 1}\right)}{p\left(\underline{x}_{1: k -1}^i \mid \underline{y}_{1: k - 1}\right)}}_{=w_{k-1}^{e, i}} $$mit Normalisierung.
Spezielle Proposal
Standard Proposal
Einfache Verwendung der Systemdynamik:
$$ p\left(\underline{x}_{k} \mid \underline{x}_{k-1}, \underline{y}_{k}\right) \stackrel{!}{=} f\left(\underline{x}_{k} \mid \underline{x}_{k-1}\right) $$Es ergibt sich
$$ w_{k}^{e, i} \propto \frac{f\left(\underline{y}_{k} \mid \hat{\underline{x}}_{k}^{i}\right) \cdot f\left(\hat{\underline{x}}_{k}^{i} \mid \hat{\underline{x}}_{k-1}^{i}\right)}{p\left(\underline{\hat{x}}_{k}^{i} \mid \hat{\underline{x}}_{k-1}^{i}, \underline{y}_k\right)} \cdot w_{k-1}^{e, i}=f\left(\underline{y}_{k} \mid \hat{\underline{x}}_{k}^{i}\right) \cdot w_{k - 1}^{e, i} $$Sehr einfach, aber KEINE verbesserte Performance 🤪
Optimales Proposal
Verwende
$$ \begin{aligned} p\left(\underline{x}_{k} \mid \underline{x}_{k-1}, \underline{y}_{k}\right) &=f\left(\underline{x}_{k} \mid \underline{x}_{k-1}, \underline{y}_{k}\right) \\ & \propto f\left(\underline{y}_{k} \mid \underline{x}_{k}\right) \cdot f\left(\underline{x}_{k} \mid \underline{x}_{k-1}\right) \end{aligned} $$Damit wäre
$$ w_k^{e, i} = w_{k-1}^{e, i} $$Wird als optimales Proposal genannt
- Minimierte Varianz der Gewicht
- Varianz der Gewicht ändert sich nicht
‼️ Aber typischerweise können wir hiervon nicht samplen $\rightarrow$ Nur in Spezialfällen verwendbar.
Einfaches praktisches Filter: SIR-Partikelfilter
Standard Proposal
Resampling nach jedem Filterschritt
Da Gewichte in Prädiktionsschritt unverändert
$$ w_{k-1}^{e, i} = \frac{1}{L} $$und damit
$$ w_k^{e, i} \propto f(\underline{y}_k \mid \underline{\hat{x}}_k^i) $$Einfachstes praktisches Partikelfilter
Algorithm
Input
- $\underline{\hat{x}}_{k-1}^{e, i}$
- $w_{k-1}^{e, i} = \frac{1}{L}, i \in \{1, \dots, L\}$
For $i \in \{1, \dots, L\}$
Ziehe
$$ \underline{\hat{x}}_{k-1}^{e, i} \sim f(\underline{x}_k \mid \underline{\hat{x}}_{k-1}^i) $$Gewichtung
$$ w_k^{e, i} \propto f(\underline{y}_k \mid \underline{\hat{x}}_{k}^{e, i}) $$
Normalisierung Gewichte $w_k^{e, i}$
Resampling
$$ \underline{\hat{x}}_{k}^{e, i}, \quad w_{k}^{e, i} = \frac{1}{L} \qquad i \in \{1, \dots, L\} $$