Progressive Filterung
Systematisches Resampling
Gegeben: Priore Dirac Mixture
$$ f_{p}(\underline{x})=\sum_{i=1}^{L} w_{i}^{p} \delta(\underline{x}-\underline{\hat{x}}_i^p) $$Filterschritt (Bayes)
$$ \tilde{f}_e(\underline{x}) \propto f_{p}(\underline{x}) \cdot f_{L}(\underline{x})=\sum_{i=1}^{L} \underbrace{w_{i}^{p} \cdot f_{L}\left(\hat{\underline{x}}_{i}^{p}\right)}_{w_{i}^{e}} \cdot \delta(\underline{x} - \underbrace{\underline{\hat{x}}_{i}^{p}}_{\underline{x}_{i}^{e}}) $$Probleme
- Falls Support / Träger von $f_L(\cdot)$ kleiner als Support von $f_p(\cdot)$, sterben viele Partikel aus!
- Positionen $\underline{\hat{x}}_i^e$ sterben aus!
Lösung
- Progressive Verarbeitung
- Reapproximation durch Optimierung
Progressive Filterung
Progressiv = Der Filterschritt wird nicht in einen Schlag verwendet, sondern wir verwenden mehrere Likelihood, um die Filterung durchzuführen.
Effektives Support:
$$ \alpha_{\varepsilon}(f(\cdot))=\{x: f(x) \geqslant \varepsilon\} \qquad (\alpha-\text{Schritt bei } \epsilon) $$Gegeben: Likelihood $f_L(\underline{x})$ mit $\alpha_{\varepsilon}(f_L(\cdot)) \ll \alpha_{\varepsilon}(f_p(\cdot))$
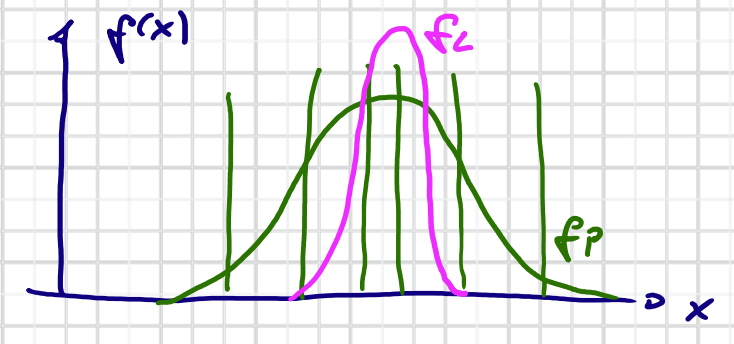
Dekomposition von $f_L(\underline{x}) $
$$ f_L(\underline{x}) = f_L^1(\underline{x}) \cdot f_L^2(\underline{x}) \cdots f_L^k(\underline{x}) $$Der Produkt von Dichten: $f_L^i(\underline{x})$ “breiter” als $f_L(\underline{x})$ $\rightarrow$ Effektives Support ist größer ($\alpha_{\varepsilon}(f_L^i(\cdot)) > \alpha_{\varepsilon}(f_L(\cdot))$ )
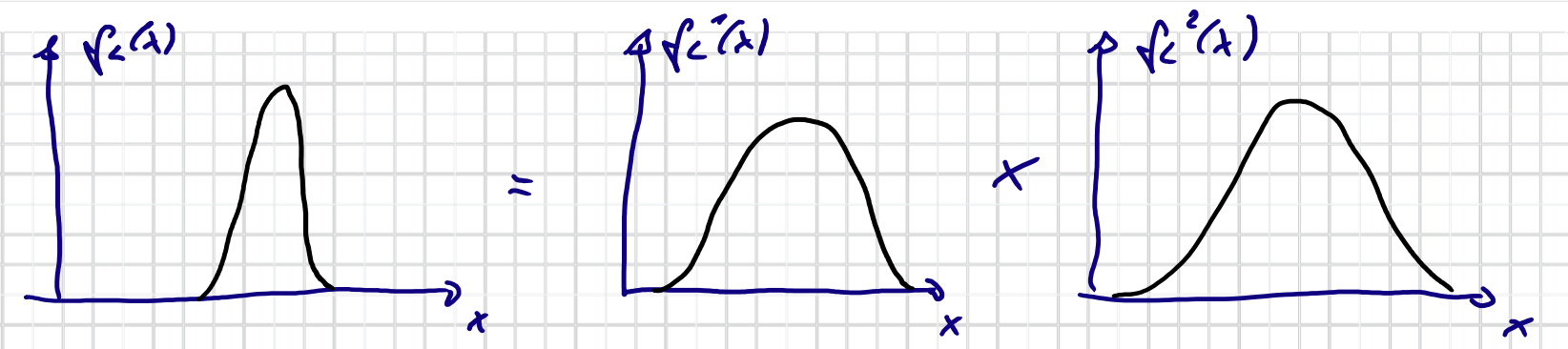
Note: Dekomposition ist NICHT eindeutig.
Damit kann Filterschritt dekomponiert werden:
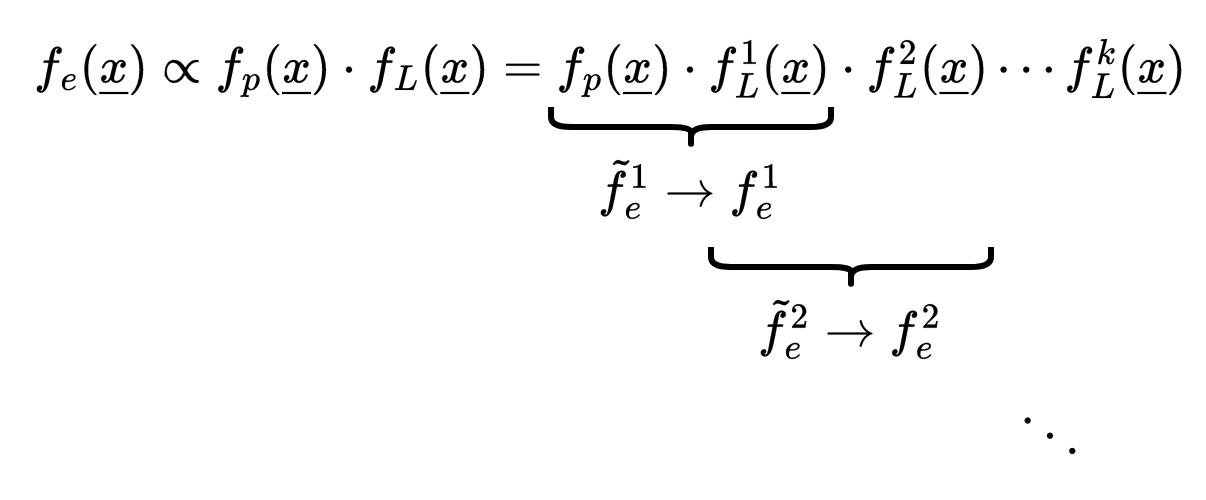
- In jedem Schritt Gewichtung der prioren Dirac Mixture
- Reapproximation nach jedem Teil-Filterschritt
Algorithms:
- $f_e^0 (\underline{x}) = f_p(\underline{x})$
For $i \in \{1, \dots, k\}$
$$ \begin{aligned} \tilde{f}_e^i(\underline{x}) &= f_e^{i-1}(\underline{x}) \cdot f_L^i((\underline{x})) \text{ (gewicht)} \quad \to f_e(\underline{x}) \\ f_e^{i}(\underline{x}) &= \operatorname{Reapproximate}(\tilde{f}_e^i(\underline{x})) \text{ (ungewicht)} \quad \to = f_e^k(\underline{x}) \end{aligned} $$
Reapproximation
Ziel
Gegeben: Gewichtete Dirac Mixture
$$ \tilde{f}(\underline{x}) = \sum_{i=1}^L \tilde{w}_i \cdot \delta(\underline{x} - \underline{\hat{x}}_i) $$Gesucht: Ungewichtete Dirac Mixture
$$ \tilde{f}(\underline{x}) \approx f(\underline{x}) = \sum_{i=1}^L \frac{1}{L} \cdot \delta(\underline{x} - \underline{\hat{x}}_i) $$Gütemaß: Distanz $D(\tilde{f}(\underline{x}) , f(\underline{x}))$
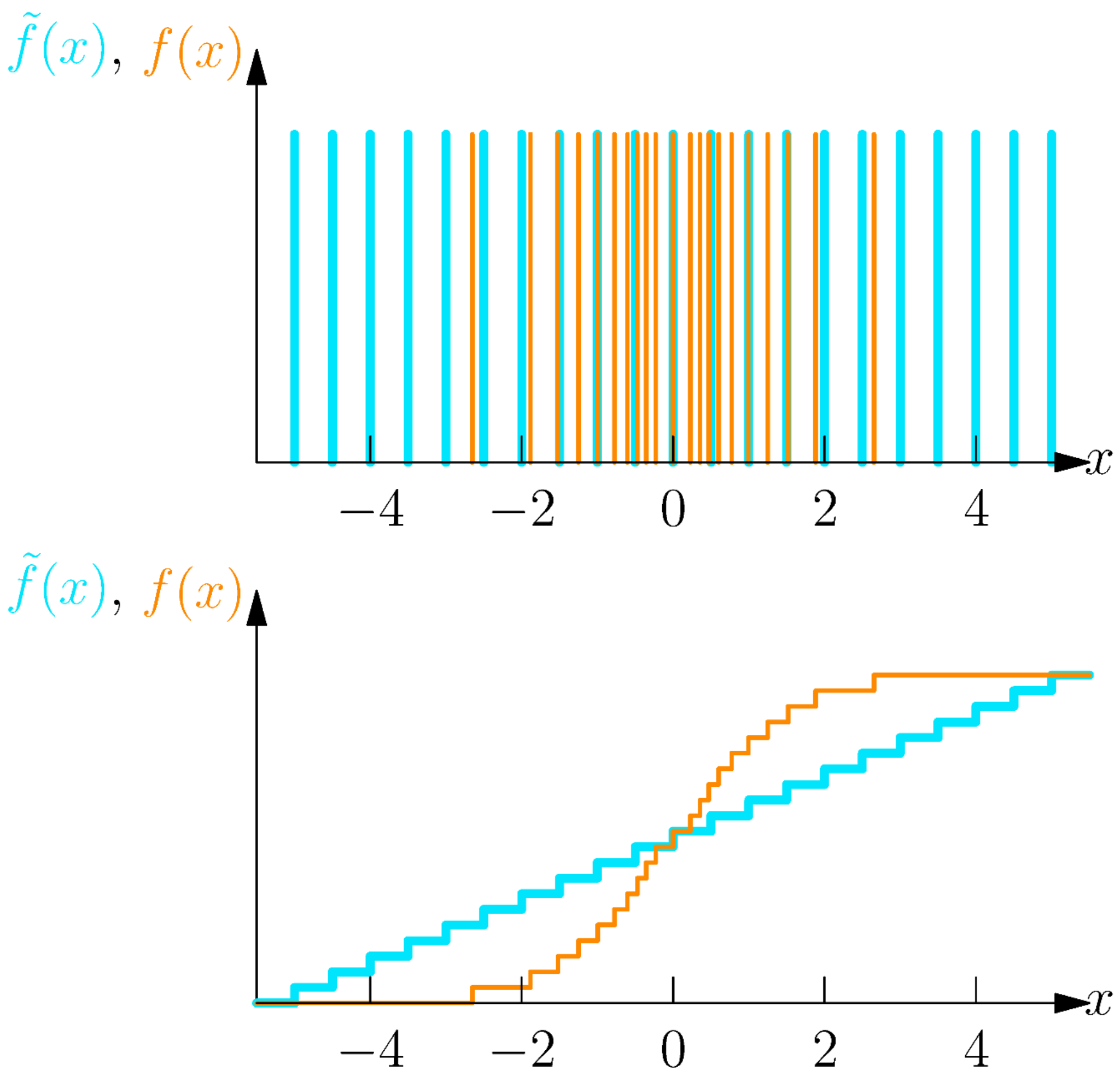
Aber Abstand zwischen Dirac Mixtures in Dichtebereich schwierig 🤪 $\rightarrow$ Wir betrachten die Kumulative Verteilung $\tilde{F}(\underline{x}), F(\underline{x})$
$$ \begin{aligned} \tilde{F}(\underline{x}) &= \sum_{i=1}^L \tilde{w}_i \cdot H(\underline{x} - \underline{\hat{x}}_i) \\ F(\underline{x}) &= \sum_{i=1}^L \frac{1}{L} \cdot H(\underline{x} - \underline{\hat{x}}_i) \\ \end{aligned} $$
Herausforderungen
Minimalbeispiel: Approximation von zwei Dirac Komponenten durch eine Komponent
$$ \begin{aligned} \tilde{F}(\underline{x}) &= w_1 \cdot H(x - \tilde{x}_1) + w_2 \cdot H(x - \tilde{x}_2) \qquad w_1, w_2 > 0, w_1 + w_2 = 1 \\ F(x) &= H(x - \hat{x}) \end{aligned} $$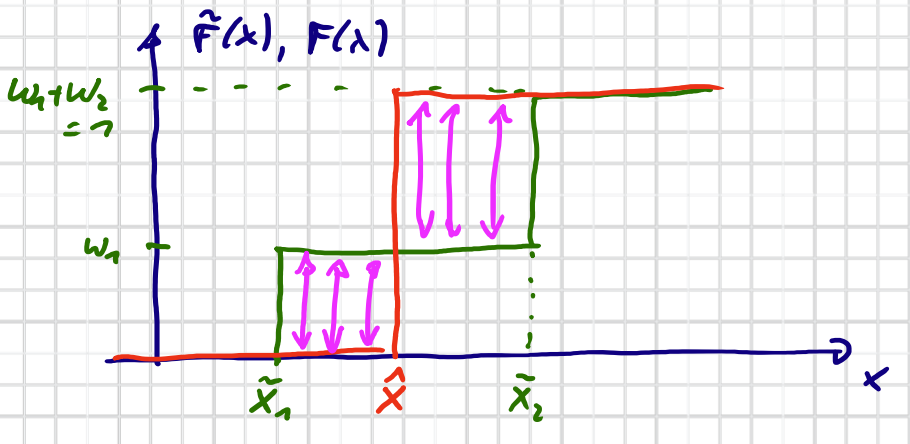
Cramér–von Mises Distanz:
$$ D=\int_{-\infty}^{\infty}[\tilde{F}(x)-F(x)]^{2} d x=\left(\hat{x}-\tilde{x}_{1}\right) \cdot w_{1}^{2}+\left(\hat{x}-\tilde{x}_{2}\right) \cdot w_{2}^{2} \quad \text{für} \quad \tilde{x}_{1} \leq \hat{x} \leq \tilde{x}_{2} $$ $$ \frac{\partial D}{\partial \hat{x}} = w_1^2 + w_2^2 $$D.h., Für alle $\hat{x}$ mit $\tilde{x}_{1} \leq \hat{x} \leq \tilde{x}_{2}$ , $D$ is immer minimiert $\rightarrow$ NICHT eindeutig!
Wasserstein-Distanz
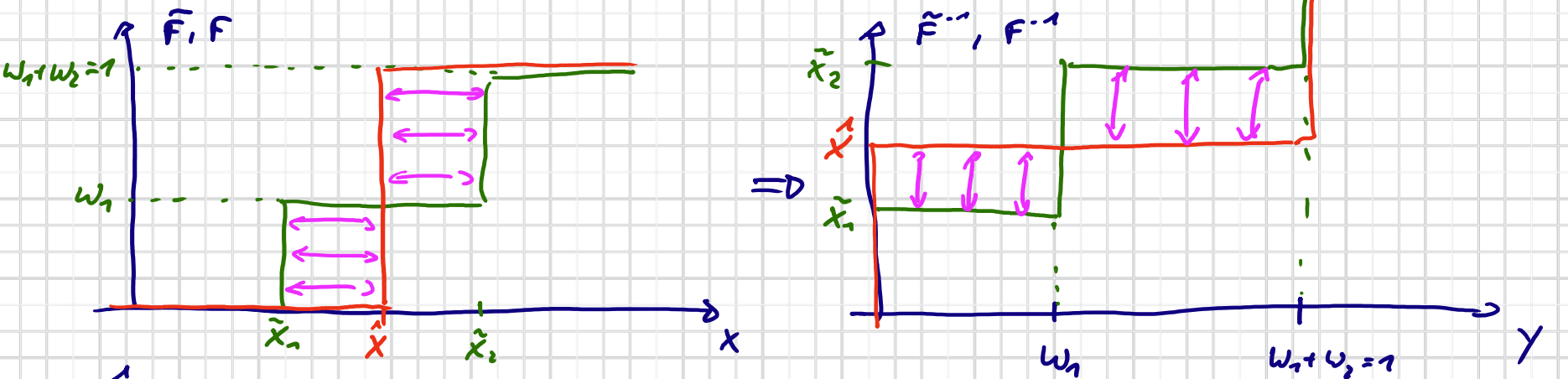 $$
D=\int_{0}^{1}\left[\tilde{F}^{-1}(y)-F^{-1}(y)\right]^{2} d y=w_{1}\left(\hat{x}-\tilde{x}_{1}\right)^{2}+w_{2}\left(\hat{x}-\tilde{x}_{2}\right)^{2}
$$
$$
\begin{aligned}
&\frac{\partial D}{\partial{x}}=2 w_{1}\left(\hat{x}-\tilde{x}_{1}\right)+2 w_{2}\left(\hat{x}-\tilde{x}_{2}\right) \\
&\Rightarrow \hat{x}=\frac{w_{1} \cdot \tilde{x}_{1}+w_{2} \tilde{x}_{2}}{w_{1}+w_{2}} \quad \text{(Gewichteter Mittelwert)}
\end{aligned}
$$
$$
D=\int_{0}^{1}\left[\tilde{F}^{-1}(y)-F^{-1}(y)\right]^{2} d y=w_{1}\left(\hat{x}-\tilde{x}_{1}\right)^{2}+w_{2}\left(\hat{x}-\tilde{x}_{2}\right)^{2}
$$
$$
\begin{aligned}
&\frac{\partial D}{\partial{x}}=2 w_{1}\left(\hat{x}-\tilde{x}_{1}\right)+2 w_{2}\left(\hat{x}-\tilde{x}_{2}\right) \\
&\Rightarrow \hat{x}=\frac{w_{1} \cdot \tilde{x}_{1}+w_{2} \tilde{x}_{2}}{w_{1}+w_{2}} \quad \text{(Gewichteter Mittelwert)}
\end{aligned}
$$Allgemeines Verfahren
 $$
\begin{aligned}
&\hat{x}_{1}=\frac{w_{1} \cdot \tilde{x}_{1}+\left(0.5-w_{1}\right) \cdot \tilde{x}_{2}}{0.5} \\
&\hat{x}_{2}=\frac{\left(w_{1}+w_{2}-0.5\right) \tilde{x}_{2}+\left(1-w_{1}-w_{2}\right) \tilde{x}_{3}}{0.5}
\end{aligned}
$$
$$
\begin{aligned}
&\hat{x}_{1}=\frac{w_{1} \cdot \tilde{x}_{1}+\left(0.5-w_{1}\right) \cdot \tilde{x}_{2}}{0.5} \\
&\hat{x}_{2}=\frac{\left(w_{1}+w_{2}-0.5\right) \tilde{x}_{2}+\left(1-w_{1}-w_{2}\right) \tilde{x}_{3}}{0.5}
\end{aligned}
$$Gesamtverfahren: Progressives Filterverfahren mit laufender Reapproximation