Quantitative Maßzahlen
👍 TL;DR
Parallelitätsgrad $PG(t)$: #parallel bearbeitete Tasks
Parallelindex $I$ (Mittlerer Grad) $$ I = \frac{\text{Sum von parallel bearbeitete Tasks}}{\text{Zeit}} =\frac{\displaystyle \sum_{i=1}^m i \cdot t_i}{\displaystyle \sum_{i=1}^m t_i} $$
$P(1)$: #auszuführenden Einheitsoperationen auf 1-Prozessor-System
$P(n)$: #auszuführenden Einheitsoperationen auf n-Prozessor-System
$T(1)$: Ausführungszeit auf einem 1-Prozessor-System (in Takten)
$T(n)$: Ausführungszeit auf einem n-Prozessor-System (in Takten)
Es gilt:
- $T(1) = P(1)$
- $T(n) \leq P(n)$
Quantitative Maßzahlen
Beschleunigung (Speedup) $$ S(n) = \frac{T(1)}{T(n)} \in [1, n] $$
Effizienz $$ E(n) = \frac{S(n)}{n} \in [\frac{1}{n}, 1] $$
Mehraufwand $$ R(n) = \frac{P(n)}{P(1)} \geq 1 $$
Auslastung (Utility) $$ U(n) = \frac{I(n)}{n} = \frac{P(n)}{n \times T(n)} = R(n) \times E(n) $$
Parallelindex $$ I(n) = \frac{P(n)}{T(n)} $$
Es gilt:
$1 \leq S(n) \leq I(n) \leq n$
$\frac{1}{n} \leq E(n) \leq U(n) \leq 1$
Gesetz von Amdahl
Sei $a$ Anteil des Programmteils, der nur sequentiell ausgeführt werden kann $$ T(n) = T(1) \times \frac{1-a}{n} + T(1) \times a $$
$$ S(n) \to \frac{1}{a} $$
Parallelitätsprofil
misst die entstehende Parallelität in einem parallelen Programm bzw. bei der Ausführung auf einem Parallelrechner.
Gibt eine Vorstellung von der inhärenten Parallelität eines Algorithmus/Programms und deren Nutzung auf einem realen oder ideellen Parallelrechner
Grafische Darstellung
- $x$-Achse: Zeit
- $y$-Achse: Anzahl paralleler Aktivitäten
Zeigt an, wie viele Tasks einer Anwendung zu einem Zeitpunkt parallel ausgeführt werden können
Parallelitätsgrad $PG(t)$: Anzahl der Tasks, die zu einem Zeitpunkt parallel bearbeitet werden können
Parallelindex $I$:Mittlerer Grad des Parallelismus, d.h., die Anzahl der parallelen Operationen pro Zeiteinheit.
Kontinuierlich $$ I = \frac{1}{t_2-t_1}\int_{t_1}^{t_2}PG(t)dt $$
Diskret $$ I= \underbrace{\left(\sum_{i=1}^{m} i \cdot t_i\right)}_{\text{PG Bereich}} / \underbrace{\left(\sum_{i=1}^{m} t_{i}\right)}_{\text{Ausführungszeit}} $$
Bsp
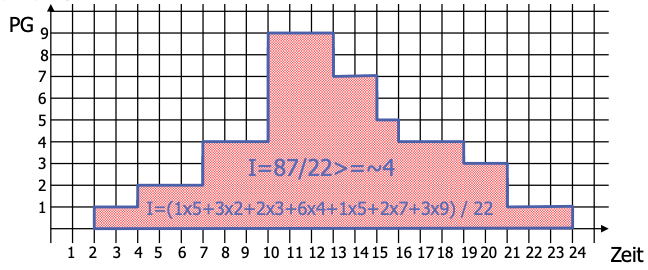
Vergleich von Multiprozessorsystemen zu Einprozessorsystemen
Definitionen
- $P(1)$: Anzahl der auszuführenden Einheitsoperationen (Tasks) des Programms auf einem Einprozessorsystem.
- $P(n)$: Anzahl der auszuführenden Einheitsoperationen (Tasks) des Programms auf einem Multiprozessorsystem mit $n$ Prozessoren.
- $T(1)$: Ausführungszeit auf einem Einprozessorsystem in Schritten (oder Takten).
- $T(n)$: Ausführungszeit auf einem Multiprozessorsystem mit $n$ Prozessoren in Schritten (oder Takten).
Vereinfachende Voraussetzungen:
$T(1) = P(1)$
“da in einem Einprozessorsystem (Annahme: einfacher Prozessor) jede (Einheits-) Operation in genau einem Schritt ausgeführt werden kann.”
$T(n) \leq P(n)$
“da in einem Multiprozessorsystem mit n Prozessoren ($n \geq 2$) in einem Schritt
mehr als eine (Einheits-)Operation ausgeführt werden kann.”
Beschleunigung (Speedup)
$$ S(n) = \frac{T(1)}{T(n)} $$
Gibt die Verbesserung in der Verarbeitungsgeschwindigkeit an
Üblicherweise: $$ 1 \leq S(n) \leq n $$
Effizienz
$$ E(n) = \frac{S(n)}{n} $$
Gibt die relative Verbesserung in der Verarbeitungsgeschwindigkeit an
Leistungssteigerung wird mit der Anzahl der Prozessoren $n$ normiert
Üblicherweise: $$ \frac{1}{n} \leq E(n) \leq 1 $$
Mehraufwand für die Parallelisierung
$$ R(n) = \frac{P(n)}{P(1)} $$
Beschreibt den bei einem Multiprozessorsystem erforderlichen Mehraufwand für die Organisation, Synchronisation und Kommunikation der Prozessoren
Es gilt: $$ 1 \leq R(n) $$ “Anzahl der auszuführenden Operationen eines parallelen Programms ist größer als diejenige des vergleichbaren sequentiellen Programms”
Parallelindex
$$ I(n) = \frac{P(n)}{T(n)} $$
Mittlerer Grad der Parallelität (Anzahl der parallelen Operationen pro
Zeiteinheit)
Auslastung
$$ \begin{aligned} U(n) &:= \frac{I(n)}{n} \\ &= \frac{P(n)}{n \times T(n)} \\ &= \frac{P(n)}{P(1)} \cdot \frac{P(1)}{n \times T(n)}\\ &\overset{P(1)=T(1)}{=} \underbrace{\frac{P(n)}{P(1)}}_{=R(n)} \cdot \underbrace{\frac{\frac{T(1)}{ T(n)}}{n}}_{=E(n)}\\ &= R(n) \times E(n) \\ \end{aligned} $$
- Entspricht dem normierten Parallelindex
- Gibt an, wie viele Operationen (Tasks) jeder Prozessor im Durchschnitt pro Zeiteinheit ausgeführt hat
Folgerungen:
Alle definierten Ausdrücke haben für $n = 1$ den Wert $1$.
Der Parallelindex gibt eine obere Schranke für die Leistungssteigerung: $$ 1 \leq S(n) \leq I(n) \leq n $$
Die Auslastung ist eine obere Schranke für die Effizienz: $$ \frac{1}{n} \leq E(n) \leq U(n) \leq 1 $$
Bsp
Ein Einprozessorsystem benötige für die Ausführung von 1000 Operationen 1000 Schritte.
Ein Multiprozessorsystem mit 4 Prozessoren benötige dafür 1200 Operationen, die aber in 400 Schritten ausgeführt werden können.
| System | #Operationen | #Schritte |
|---|---|---|
| Einprozessorsystem | 1000 | 1000 |
| 4-Prozessor-System | 1200 | 400 |
Damit gilt: $$ P(1) = T(1) = 1000 $$
$$ P(4) = 1200, \quad T(4) = 400 $$
Daraus ergibt sich:
Beschleunigung (Speedup) $$ S(4) = \frac{T(1)}{T(4)} = \frac{1000}{400} = 2.5 $$
Effizienz $$ E(4) = \frac{S(4)}{4} = \frac{2.5}{4} = 0.625 $$ “Die Leistungssteigerung verteilt sich als im Mittel zu 62,5% auf alle Prozessoren”
Parallelindex $$ I(4) = \frac{\text{#Operationen}}{\text{#Schritte}} = \frac{1200}{400} = 3 $$ “Es sind im Mittel drei Prozessoren gleichzeitig tätig”
Auslastung $$ U(4) = \frac{I(4)}{4} = \frac{3}{4}=0.75 $$ “Jeder Prozessor ist nur zu 75% der Zeit aktiv.”
Mehraufwand $$ R(4) = \frac{P(4)}{P(1)} = \frac{1200}{1000} = 1.2 $$ “Bei Ausführung auf dem Multiprozessorsystem sind 20% mehr Operationen als bei Ausführung auf einem Einprozessorsystem notwendig.”
Skalierbarkeit eines Parallelrechners
Das Hinzufügen von weiteren Verarbeitungselementen führt zu einer kürzeren Gesamtausführungszeit, ohne dass das Programm geändert werden muss. 👏
$\Rightarrow$ eine lineare Steigerung der Beschleunigung mit einer Effizienz nahe bei Eins.
Wichtig für die Skalierbarkeit: angemessene Problemgröße
Bei fester Problemgröße und steigender Prozessorzahl wird ab einer bestimmten Prozessorzahl eine Sättigung eintreten.
$\Rightarrow$ Die Skalierbarkeit ist in jedem Fall beschränkt.
Skaliert man mit der Anzahl der Prozessoren auch die Problemgröße (scaled problem analysis), so tritt dieser Effekt bei gut skalierenden Hardware- oder Software-Systemen NICHT auf.
Gesetz von Amdahl
Amdahl’s law is often used in parallel computing to predict the theoretical speedup when using multiple processors.
More see: Amdahl’s law
Gesamtausführungszeit $T(n)$ $$ T(n) = \overbrace{T(1) \times \frac{1-a}{n}}^{\text{Ausführungszeit} \ \text{des parallel} \ \text{ausführbaren} \ \text{Programmteils } 1 - a} + \underbrace{T(1) \times a}_{\text{Ausführungszeit des sequentiell ausführbaren Programmteils } a} $$
$a$: Anteil des Programmteils, der nur sequentiell ausgeführt werden kann
$n$: Beschleunigungsfaktor (bspw. die Anzahl der Prozessoren)
Beschleunigung $$ \begin{aligned} S(n) &= \frac{T(1)}{T(n)} \\ & = \frac{T(1)}{T(1) \times \frac{1-a}{n} + T(1) \times a} \\ & = \frac{1}{\frac{1-a}{n} + a} \overset{n \to \infty}{\longrightarrow} \frac{1}{a} \end{aligned} $$
Diskussion
Amdahls Gesetz zufolge kann eine kleine Anzahl von sequentiellen Operationen die mit einem Parallelrechner erreichbare Beschleunigung signifikant begrenzen.
- Bsp: a = 1/10 des parallelen Programms kann nur sequenziell ausgeführt werden, $\rightarrow$ das gesamte Programm kann maximal zehnmal schneller als ein vergleichbares, rein sequenzielles Programm sein.
ABER: viele parallele Programme haben einen sehr geringen sequenziellen Anteil ($a \ll 1$) 🤪
🔴 Grundsätzliche Probleme bei Multiprozessoren
- Verwaltungsaufwand (Overhead)
- Steigt mit der Zahl der zu verwaltenden Prozessoren
- Möglichkeit von Systemverklemmungen (deadlocks)
- Möglichkeit von Sättigungserscheinungen
- können durch Systemengpässe (bottlenecks) verursacht werden.