Ub6-Parallele Programmierung
Parallelisierungsprozess
- 🎯 Ziel:Schnellere Lösung der parallelen Version gegenüber der sequentiellen Version
- Festlegen der Aufgaben, die parallel ausgeführt werden können
- Aufteilen der Aufgaben und der Daten auf Verarbeitungsknoten
- Berechnung
- Datenzugriff
- Ein-/Ausgabe
- Verwalten des Datenzugriffs, der Kommunikation und Synchronisation
- Programmierer oder Automatische Parallelisierung
Definition
Tasks
- Kleinste Parallelisierungseinheit
- grobkörnig vs. feinkörnig
Prozess oder Thread
Paralleles Programm setzt sich aus mehreren kooperierenden Prozessen zusammen, von denen jeder eine Teilmenge der Tasks ausführt
Kommunikation und Synchronisation der Prozesse untereinander
Virtualisierung von einem Multiprozessor, Abstraktion
Prozessor
Ausführung eines oder mehrerer Prozesse
Physikalische Ressource
‼️ Unterscheidung zwischen Prozess und Prozessor!
⇒ Anzahl der Prozesse muss NICHT gleich der Anzahl der Prozessoren eines Multiprozessorsystems sein
Schritte bei der Parallelisierung
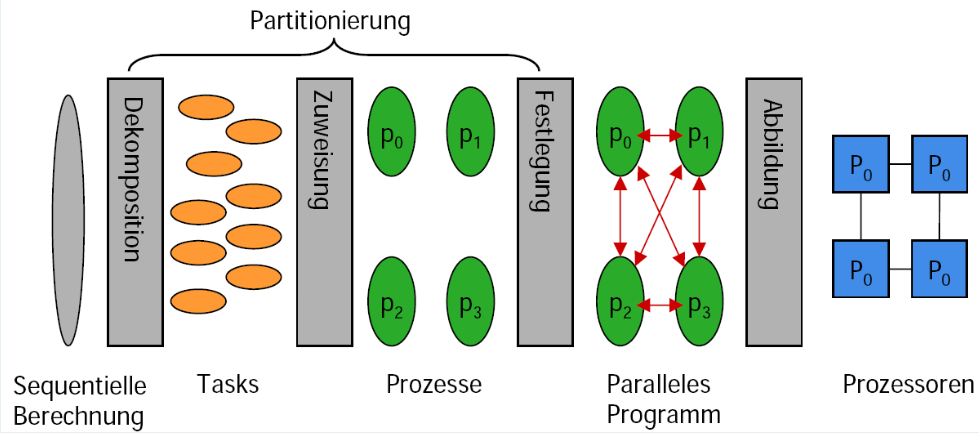
Ausgangspunkt: ein sequentielles Programm
Dekomposition (oder Aufteilung) der Berechnung in Tasks
- Granularität, möglicherweise dynamische Anzahl an Tasks
Zuweisung der Tasks zu Prozessen
- Lastverteilung, geringe Kommunikation
Zusammenführung(Orchestration)
Festlegungdes notwendigen Datenzugriffs, der Kommunikation und der Synchronisation zwischen den Prozessen
Auswahl des passenden Programmiermodells
- Abbildung der Prozesse auf die Prozessoren
- Dekomposition, Zuweisung und Festlegung werden zusammen auch als Partitionierung bezeichnet
- Granularität beachten!
- Verwaltungsaufwand (Overhead) gering halten
- Vgl. Amdahls Gesetz
Programmiermodelle
- Definition einer abstrakten parallelen Maschine
- Spezifikationen
- Parallele Abarbeitung von Teilen des Programms
- Informationsaustausch
- Synchronisationsoperationen zur Koordination
- Anwendungen werden auf der Grundlage eines parallelen Programmiermodells formuliert
Multiprogramming
Menge von unabhängigen sequentiellen Programmen
KEINE Kommunikation oder Koordination
Aber: Mögliche gegenseitige Beeinflussungbeim gleichzeitigen Zugriff auf den Speicher!
Verwendung:
Auf allen Rechnern, die ”gleichzeitig“ verschiedene Programme ausführen können (multitasking-fähiges Betriebssystem)
Gemeinsamer Speicher (Shared Memory)
- Kommunikation und Koordination von Prozessen über gemeinsame Variablen
- Atomare Synchronisationsoperationen
- Semaphoren, Mutex, Monitore, Transactional Memory,. . .
- Verwendung
- Symmetrischer Multiprozessor (SMP)
- Distributed-shared-memory Multiprozessor (DSM)
- Speicherzugriff
Uniform Memory Access (UMA)
Non-Uniform Memory Access (NUMA), CC-NUMA
Thread-Programmierung
Parallele Programme für Shared-Memory-Systeme bestehen aus mehreren Threads
Alle Threads eines Prozesses teilen sich
- Adressraum,
- Daten,
- Filehandler, . . .
Threads werden meist vom Betriebsystem verwaltet
Unterstützung vom Betriebsystem notwendig
Explizite Synchronisation notwendig!
👍 Vorteile: durch die Thread-Bibliothek erhält man eine detailierte Kontrolle über die Threads
👎 Nachteil: die Thread-Bibliothek erzwingt, dass man die Kontrolle über die Threads übernimmt
Bsp: OpenMP
Verwendet das Join-Fork-Modell
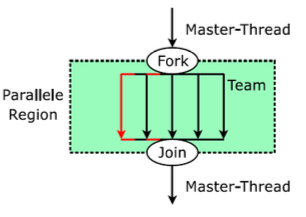
Einsatz insbesondere im Bereich der UMA-Architekturen
Message Passing
- Nachrichtenorientiertes Programmiermodell
- KEIN gemeinsamer Adressraum
- Kommunikation der Prozesse mit Hilfe von Nachrichten
- Verwendung von korrespondierenden
Send- undReceive-Operationen - Verwendung:
- Cluster
- Nachrichtengekoppelter (shared-nothing-) Multiprozessor
- Speicherzugriff:
- No Remote Memory Access (NORMA)
Message Passing Interface (MPI)
- Ein Standard für die nachrichtenbasierte Kommunikation in einem Multiprozessorsystem
- Nachrichtenbasierter Ansatz gewährleistet eine gute Skalierbarkeit
- Bibliotheksfunktionen koordinieren die Ausführung von mehreren Prozessen, sowie Verteilung von Daten, per Default keine gemeinsamen Daten
- Single Program Multiple Data (SPMD) Ansatz
- Einsatz insbesondere im Bereich der NORMA-Architekturen
- Bsp:
<mpi.h>
Shared Memory + Message Passing
- Mischung der Programmiermodelle
- Cluster mit SMP-/DSM-Knoten (Multicore-CPUs oder Multiprozessor-System mit gemeinsamem Speicher)
- Innerhalb eines Knotens: Shared-Memory-Programmiermodell
- Zwischen den Knoten: Nachrichtenorientiertes Programmiermodell
Datenparallelismus
- Gleichzeitige Ausführung von Operationen auf getrennten Elementen einer Datenmenge (Feld, Vektor, Matrix)
- Verwendung: Typischerweise in Vektorrechnern
Aufgabe 2
Eine Methode aus der Numerischen Mathematik arbeitet auf einem 2D-Torus mit $n \times n$ Kno- ten. Dabei werden die Zustände der Knoten, basierend auf ihrem aktuellen Zustand und den Zuständen ihrer vier Nachbarknoten, aktualisiert. In jeder Iteration werden drei Schritte durch- geführt:
- Im ersten Schritt müssen zuerst die Zustände aus dem Speicher gelesen werden.
- Im zweiten Schritt wird die Berechnung ausgeführt.
- Im dritten Schritt werden die neuen Zustände zurück in den Speicher geschrieben.
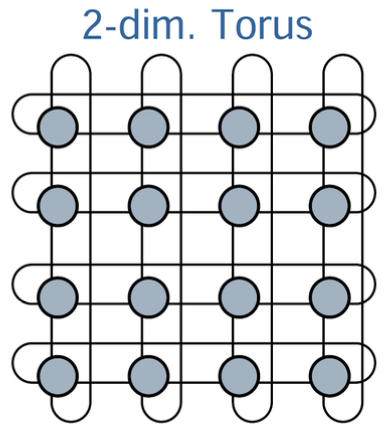
Teilaufgabe (a)
SMP-Knoten mit $p$ Prozessoren
In diesem System kann immer nur ein Lese- oder Schreibzugriff ausgeführt werden.
Die Lese- und Schreibzugriffe überlappen sich nicht mit den Berechnungen (z.B. wegen einer vorherigen Synchronisation).
Berechnen Sie die Beschleunigung der Anwendung bei der Ausführung auf dem SMP- Knoten.
Welches Problem tritt in dem SMP-System auf?
Lösung:
SMP: gemeinsamer Adressraum, globaler Speicher
$\Rightarrow$ Meist UMA (Unifrom Memory Access), also gleiche Zugriffszeit von allen Knoten
Sequentielle Zeit $T(1)$: $$ \underbrace{5 n^{2}}_{\text {Daten aus Speicher holen }}+\underbrace{n^{2}}_{\text {Berechnung }}+\underbrace{n^{2}}_{\text {Zurückschreiben }}=7 n^{2} $$
Parallele Zeit $T(p)$: $$ \underbrace{5 n^{2}}_{\text {Daten aus Speicher holen }}+\underbrace{\frac{n^{2}}{P}}_{\text {par. Berechnung }}+\underbrace{n^{2}}_{\text {Zurückschreiben }}=6 n^{2}+\frac{n^{2}}{P} $$
$\Rightarrow$ Beschleunigung: $$ S(P)=\frac{T(1)}{T(P)}=\frac{7 n^{2}}{6 n^{2}+\frac{n^{2}}{P}}=\frac{7}{6+\frac{1}{P}}<\frac{7}{6} $$ Das Problem ist hierbei, dass der Speicher als limitierender Faktor wirkt und damit die Beschleunigung stark beschränkt ist.
Teilaufgabe (b)
Was ändert sich, wenn auf eine Synchronisation vor der Berechnung verzichtet wird?
Lösung:
Verzicht auf die Synchronisation
$\Rightarrow$ Die Berechnung auf den Prozessoren kann mit den Datenzugriffen überlappend erfolgen.
$\Rightarrow$ Bei der parallelen Ausführungszeit spart man sich dadurch die Zeit für die Berechnung $\frac{n^2}{p}$ ein. (Dies gilt aber nur, wenn die Berechnungszeit kürzer ist, als die Zeit für die Datenzugriffe.) $$ T(p) = 5n^2 + n^2 = 6n^2 $$
$$ S(P)=\frac{T(1)}{T(P)}=\frac{7 n^{2}}{6 n^{2}}=\frac{7}{6} $$
Insgesamt überwiegt auch hier die Zeit für die nicht parallelisierbaren Lese- und Schreibzugriffe. Der gemeinsame Speicher des SMP-Systems ist der limitierende Faktor.
Teilaufgabe (c)
Ersetze SMP-Knoten durch eine NUMA Architektur mit $p$ Prozessoren und $P$ Speichern.
Vereinfachende Annahmen:
- Erfolgt ein Speicherzugriff auf einen entfernten Speicher, so benötigt ein Speicher-zugriff drei Zeiteinheiten.
- Wird nur ein Prozessor verwendet, so befinden alle zur Berechnung notwendigen Daten im lokal zum Prozessor gehörenden Speicher.
Welche Beschleunigung lässt sich erzielen, wenn die Zustände der Nachbarknoten im- mer aus entfernten Speichern abgerufen werden müssen?
Lösung: $$ T(1) = 5n^2 + n^2 + n^2 = 7n^2 $$
$$ T(p) = \overbrace{\frac{3n^2 \cdot 4}{p}}^{\text{4 Werte der Nachbarknoten aus entferntem Speicher}} + \underbrace{\frac{n^2}{p}}_{\text{eigener Wert im lokalen Speicher}} + \overbrace{\frac{n^2}{p}}^{\text{parallele Berechnung}} + \underbrace{\frac{n^2}{p}}_{\text{Zurückschreiben in lokalen Speicher}} = \frac{15n^2}{p} $$
Beschleunigung: $$ S(p) = \frac{T(1)}{T(p)} = \frac{7n^2}{\frac{15n^2}{p}} = \frac{7}{15}p $$ Also Die Beschleunigung skaliert mit $\frac{7}{15}$ der Prozessorenzahl (linear).