Ub9-Vektorrechner
Kurze Zusammenfassung von Vektorrechner
Definition
Vektorprozessor (Vektorrechner): Rechner mit pipelineartig aufgebautem/n Rechenwerk/en zur Verarbeitung von Arrays aus Gleitpunktzahlen.
Merkmale
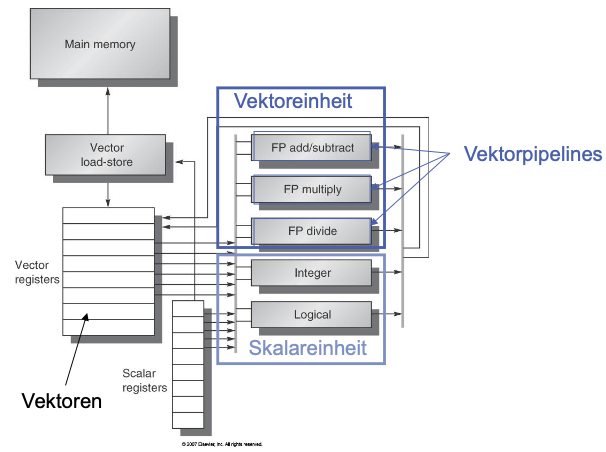
SIMD-Prinzip
Vektor = Array aus Gleitpunktzahlen
Eine oder mehrere Vektorpipelines
- Ein Satz von Vektorpipelines bildet die Vektoreinheit
Bei Vektoroperationen entfällt Adressberechnung
Zusätzlich eine Skalareinheiten (mehrere Funktionseinheiten)
Vektor- und Skalareinheit können parallel laufen
Parallelverarbeitung
Vektor-Pipeline-Parallelität
- Überlappung durch mehrere Stufen in einer Pipeline
Mehrere Vektor-Pipelines in einer Vektoreinheit
- mehrere, meist funktional verschiedene Vektorpipelines ⇒ Verkettung
Vervielfachung der Pipelines
Vervielfachung gleicher Vektorpipelines
Ausführung eines Befehls gleichzeitig auf mehreren Pipelines
vielfach schneller 👏
aber verfielfachter Hardware-Aufwand 😢
Mehrere Vektoreinheiten
- Vektor-Multiprozessor oder Parallel-Vektorrechner
- MIMD-/SIMD-Prinzip
Parallele Speicherzugriffe
(n-fache) Speicherverschränkung / Memory Interleaving
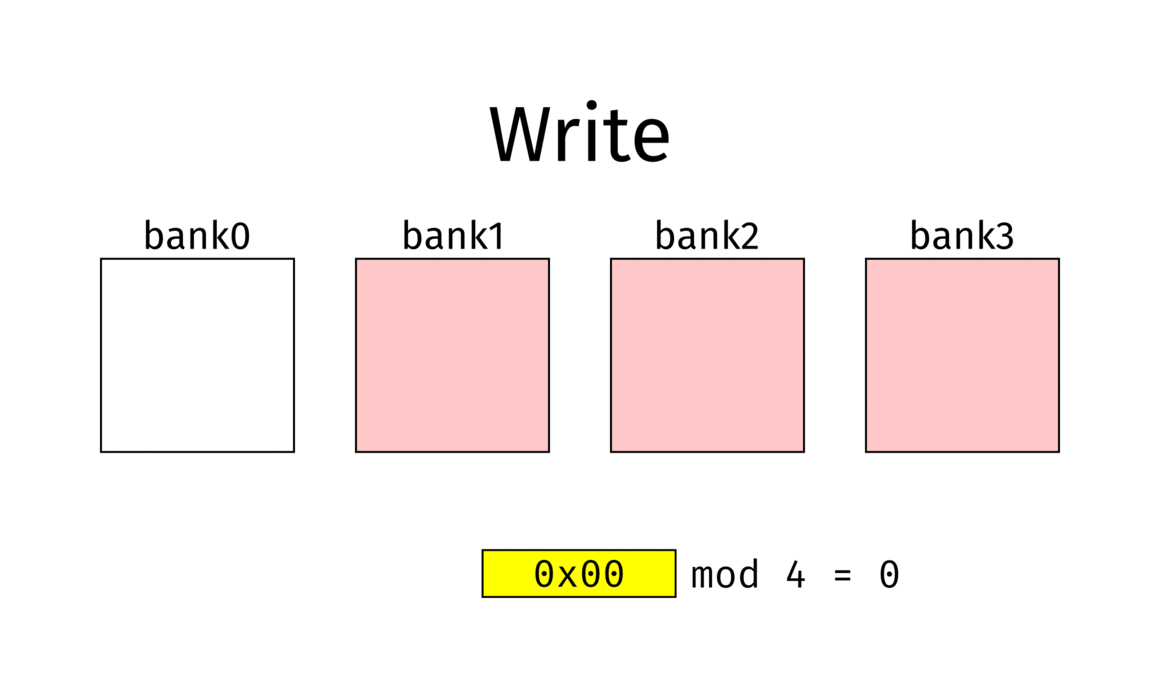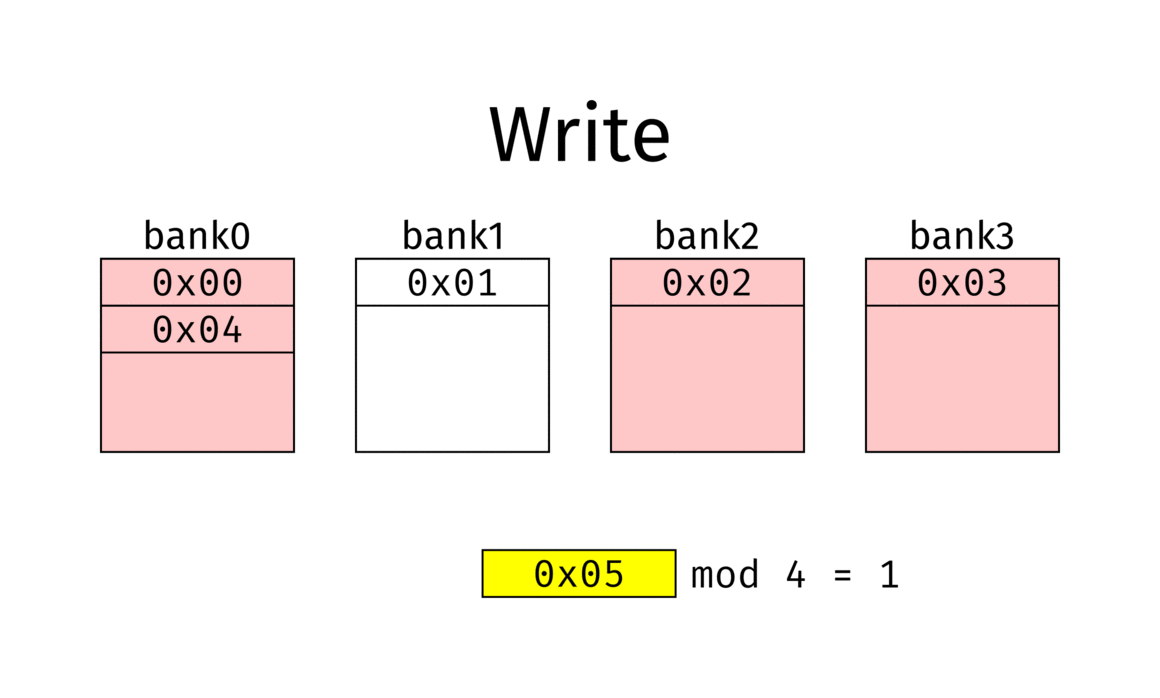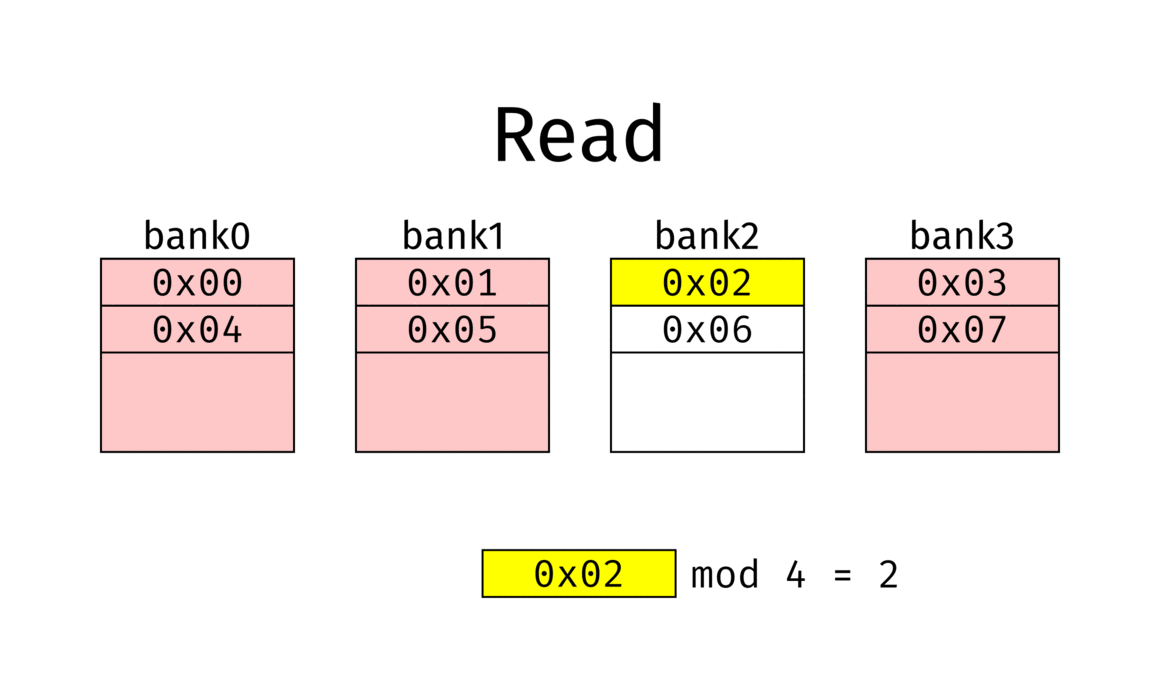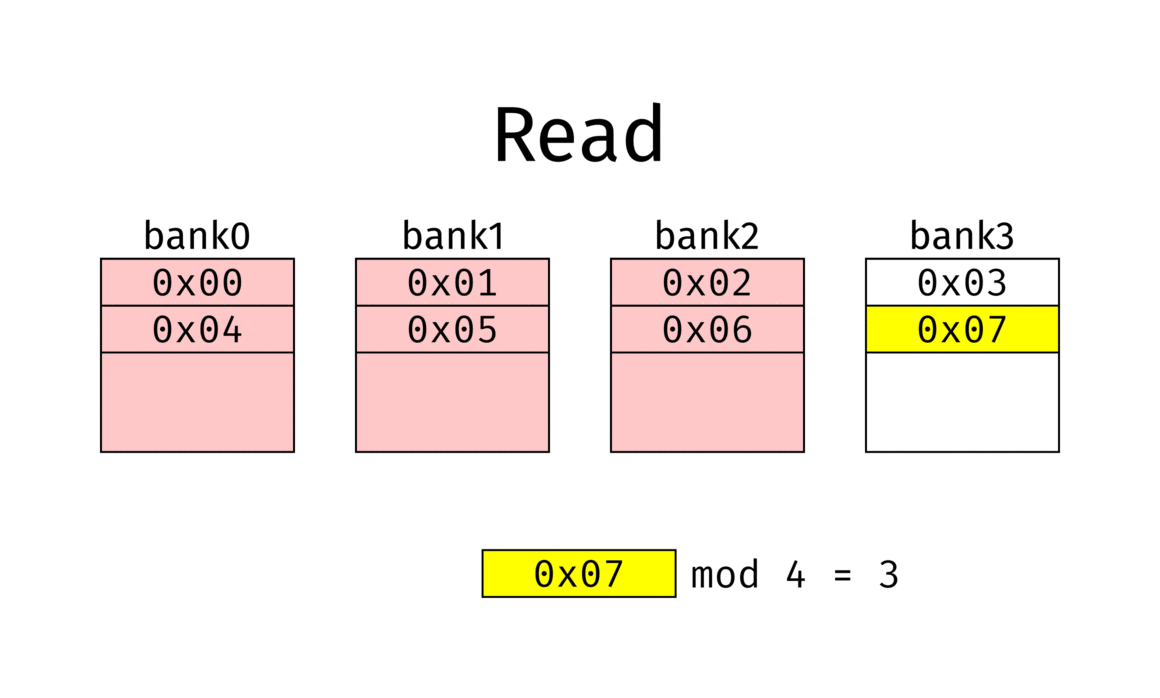
Unterteilung des Speichers in $n$ Speicherbänke
Verteilung von Speicherplatz $A_i$ auf Speicherbank $M_j$ wenn $$ j = i \bmod n $$
Nach einer Anlaufzeit werden in jedem Speicherzyklus $n$ Speicherworte geliefert
Bsp
- Memory interleaving example with 4 banks.
- Red banks are refreshing and can’t be used.
Vektor Stride
- Vektor Stride wird verwendet, wenn Daten nicht fortlaufend im Speicher liegen (z.B. bei Standard Matrix-Matrix-Multiplikation).
- Vektor Stride gibt Abstand zwischen Elementen an, die in einem Register verwendet werden
Verkettung
- Verkettung mehrere verschiedener Vektorpipelines zur Ausführung einer Folge von Vektoroperationen.
- Die Ergebnisse einer Pipeline werden SOFORT der nächsten Pipeline zur Verfügung gestellt 👏
Vektor-Maskierungssteuerung / Vektor-Mask-Register
Jede Vektorinstruktion arbeitet NUR auf den Vektorelementen, deren Einträge eine 1 haben.
z.B. zur Auflösung/Umgehung von nicht vektorisierbaren IF-Anweisungen
Aufgabe
(a)Vektorbefehlen
Implementieren Sie mit den Vektorbefehlen aus dem Foliensatz der Vorlesung die DAXPY-Operation:
Y = a * X + Y
wobei X und Y Vektoren sind und a ein Skalar.
Lösung
Tabelle von Vektorbefehlen:
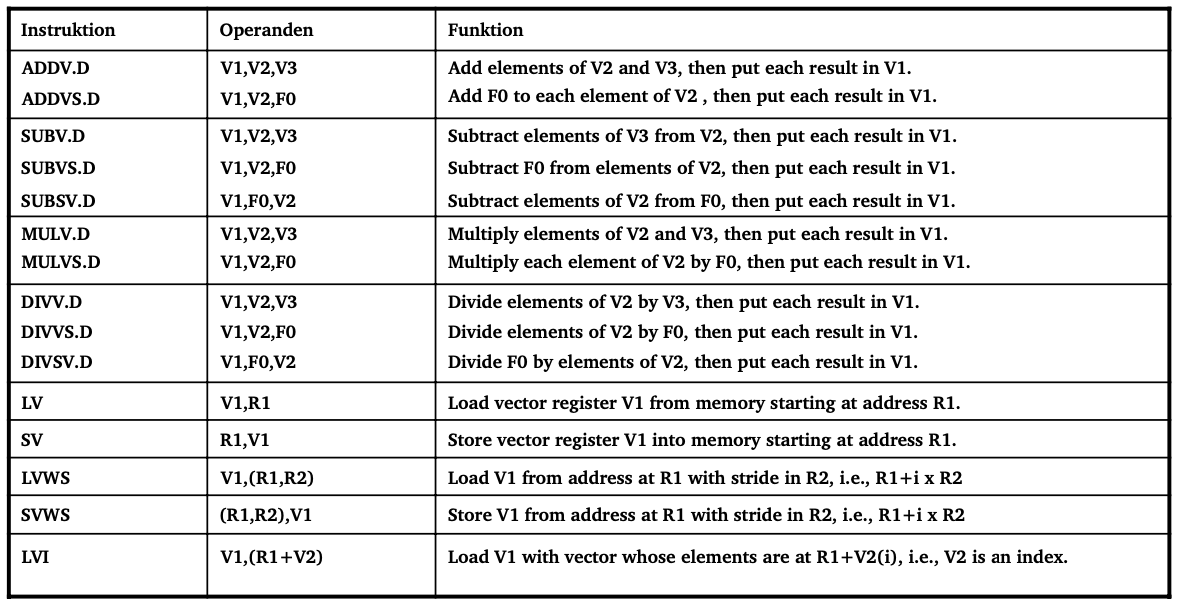
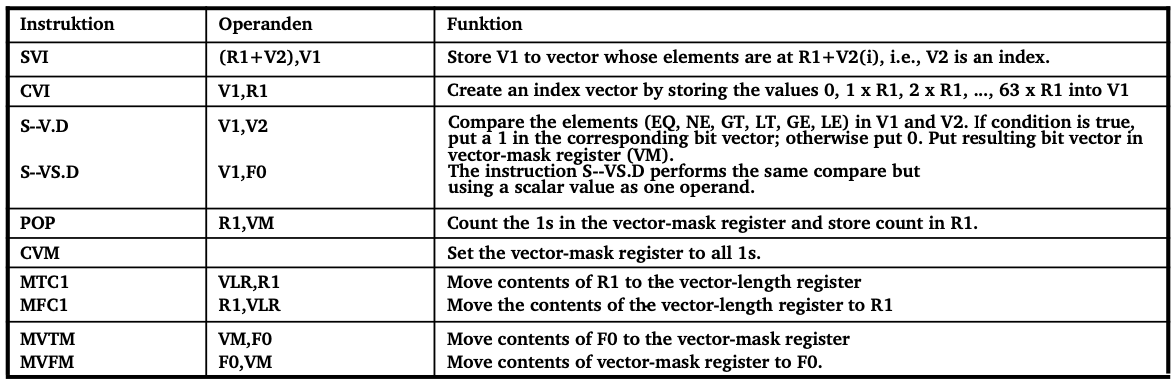
L.D F0, a ; load scalar a
LV V1, Rx ; load vector X
MULVS.D V2, V1, F0 ; vector-scalar multiplication
LV V3, Ry ; load vector Y
ADDV.D V4, V2, V3 ; vector add
SV Ry, V4 ; store result vector
(b)Convoys und chimes
- GruppierenSievoneinanderunabhängigeVektorbefehlederDAXPY-Berechnunginso- genannte Convoys und stellen Sie eine Ausführungsreihenfolge dieser Gruppen auf.
- Gehen Sie davon aus, dass jede Vektorfunktionseinheit nur einmal existiert.
- Die Vektorinstruktionen der jeweiligen Gruppe werden parallel zur Ausführung gebracht und benötigen zur Ausführung jeweils ein sogenanntes chime.
Wie viele chimes pro FLOP werden insgesamt benötigt?
Lösung
- convoy
- The set of vector instructions that could potentially begin execution together in one clock period
- The instructions in a convoy must NOT contain any structural or data hazards
- chime
- A chime is the unit of time taken to execute one convoy. (1 convoy, 1 chime)
- A chime is an approximate measure of execution time for a vector sequence
- A chime measurement is independent of vector length.
Convoys:

MULVS.D V2, V1, F0undLV V3, Rykönnen zusammen (parallel) ausgeführt werden, da keine Datenabhängigkeit existiert.
$\Rightarrow$ 4 Convoys werden benötigt.
Jeder dieser Convoys benötigt nach der Aufgabenstellung ein chime zur Ausführung
$\Rightarrow$ 4 chimes werden benötigt.
Es gibt insgesamt 2 FLOP (MULVS.D V2, V1, F0 und ADDV.D V4, V2, V3)
$\Rightarrow$ Es ergibt sich eine Rate von $\frac{\text{chimes}}{\text{FLOP}} = \frac{4}{2} =2$
(c)Overhead und Latenz
**Die Ausführungszeit einer Folge von Vektoroperationen hängt auch von der Zeit für das Aufsetzen der Operationen ab. Dieser Overhead ist in der nebenstehenden Tabelle gegeben. **
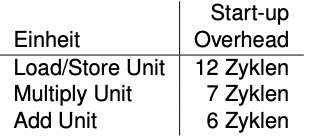
Geben Sie für jeden der Convoys aus Teilaufgabe (b) und einer Vektorlänge $n$ die folgenden Zeitpunkte an:
den Startzeitpunkt,
den Zeitpunkt an dem das erste Ergebnis des jeweiligen Convoys geliefert wird,
den Zeitpunkt des letzten Ergebnisses.
Wie verhält sich für $n=64$ diese Betrachtung zur Abschätzung mittels chimes aus Aufgabe?
Lösung

Erklärung für den Eintrag $11 + n$ in der 1.Zeile:
Das erste Ergebnis kommt am Zeitpunkt 12 an. D.h. es gibt noch $n-1$ Ergebnisse zu liefern.
Pro Takt wird ein Ergebnis geliefert
$\Rightarrow$ $n-1$ Takte sind nötig.
$\Rightarrow$ Das letzte Ergebnis wird am Zeitpunkt $12 + (n-1) = 11 + n$ ankommen.
Die Zeit pro Ergebnis ist für einen Vektor der Länge 64 ist: $$ \frac{41 + 4 \cdot 64}{64} = 4.64 \text{ Zyklen} $$ Verglichen mit der Schätzung von 4 chimes ergibt sich, dass die genauere Rechnung aufgrund des Overheads für das Aufsetzen der jeweiligen Operationen um $\frac{4,64}{4} = 1.16$ mal höher ausfällt.
(d)Parallele Speicherzugriffe
Vektorbefehle werden oft durch ein spezielles Speichersystem mit Verschränkung (memory interleaving) und mehreren Speicherbänken unterstützt.
Wie lange dauert ein Ladebefehl eines 64-elementigen Vektors bei 16 Speicherbänken und einer Latenz von 12 Zyklen
mit einem Stride von 1?
bei einem Stride von 32?
Lösung
Stride = 1
Latenz von 12 Zyklen für erstes Element
Latenz von 63 Zyklen für alle weiteren zu holenden Elemente
da bei 16 Speicherbänken jeder nächste Zugriff auf die jeweils nächste Bank geht
und somit die Latenz von 12 Takten versteckt werden kann.
$\Rightarrow$ Insgesamt $12 + 63 = 75$ Zyklen
Stride = 32
Da 32 ein Vielfaches von 16 (der Anzahl der Bänke) ist, handelt es sich hier um den schlechtesten Fall. 😢
- Jeder Zugriff des Strides geht auf die gleiche Speicherbank und kollidiert mit dem vorhergehenden.
Damit benötigt jeder Speicherzugriff die Latenz von 12 Takten
$\Rightarrow$ Insgesamt $12 \cdot 64 = 768$ Takte
(e)Verkettung
Vergleichen Sie die Ausfu ̈hrungmitundohneVerkettungderfolgenden Instruktionssequenz miteinander:
MULTV V1, V2, V3
ADDV V4, V1, V5
- Die Vektoren haben 64 Elemente
- Die Verzögerung des Additionseinheit - und der Multiplikationseinheit sind 6 und 7 Zyklen.
Wie groß ist der erzielte Speedup?
Lösung
| Verzögerung (Zyklen) | |
|---|---|
| Multiplikationseinheit | 7 |
| Additionseinheit | 6 |
Ohne Verkettung:

Gesamt 139 Takte
Mit Verkettung
Verkettung: Die Ergebnisse einer Pipeline werden SOFORT der nächsten Pipeline zur Verfügung gestellt

Gesamt 76 Takte
Speedup $$ \text{Speedup}_{\text{Verkettung}} = \frac{139}{76} \approx 1.83 $$
(f)Maskierungssteuerung
Gegeben Sei folgendes Fragment eines C-Programmes:

Realisieren Sie dieses Code-Fragment mittels Vektorbefehlen. Gehen Sie bei Ihren Uberlegungen davon aus, dass ein Vektorregister je alle $n$ Werte der Arrays $a$ oder $b$ aufnehmen kann.
Lösung
# Initialisierung
MTC1 VLR, R1 # vector-length register := n
# wobei R1 den Wert n enthaelt
LV V1, Ra # int a[n] in V1 laden
LV V2, Rb # int b[n] in V2 laden
MOV R1, 1 # R1 mit 1 initialisieren
CVI V3, R1 # Create Vektor Index
# 0, R1 * 1, R1 * 2
# entspricht: for (i=0;i<n,i++)
# Berechnung
SLTV.D V1, V2 # compare elements with ’Less Than’
# if true 1 in Vektor Mask Register
# else 0 in Vektor Mask Register
# entpricht: if (a[i] < b[i])
# Note:
# Bei Vektor-Mask-Register (VMR):
# - Jede ausgeführte Vektorinstruktion arbeitet NUR auf den Vektorelementen,
# deren Einträge eine 1 haben.
# - Die Einträge im Zielvektorregister, die eine 0 im entsprechenden Feld des VM Registers haben,
# werden NICHT verändert
SUBV.D V2, V2, V2 # Komponenten von V2 mit 1
# im VMR werden auf 0 gesetzt
ADDV.D V2, V2, V3 # diese Komponenten werden mit
# den Werten aus V3 aufgefuellt
# entspricht: B[i] = i;
# Abschluss
CVM # Clear Vektor Mask
# alle Eintraege im VMR auf 1 setzen
SV Rb, V2 # alle Komponent von V2
# an Adresse in Rb speichern
# entspricht Schreiben von b[i]
Bsp: