Human Pose Estimation Datasets
COCO Keypoints Detection

17 Keypoints:
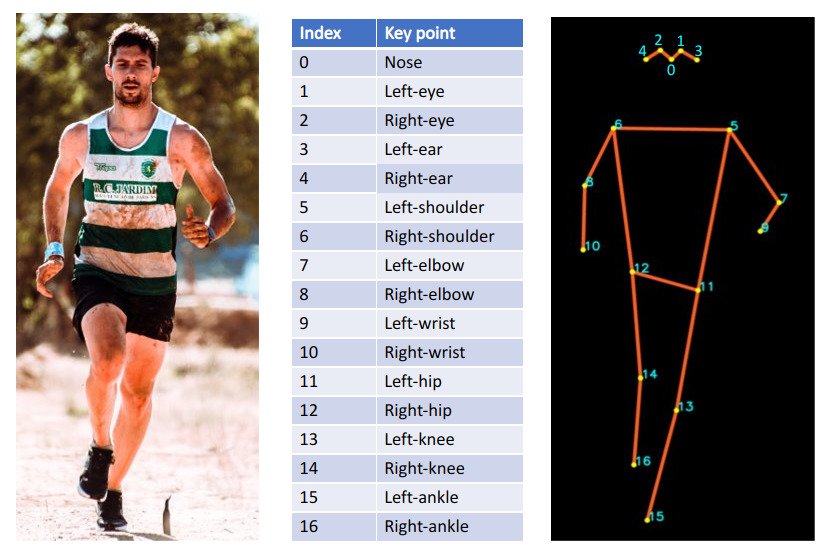
Keypoint detection format:

Annotations
Annotations for keypoints are just like in Object Detection (Segmentation), except a number of keypoints is specified in sets of 3, (x, y, v).
annotation{
"keypoints": [x1,y1,v1,...],
"num_keypoints": int,
"id": int,
"image_id": int,
"category_id": int,
"segmentation": RLE or [polygon],
"area": float,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1,
}
“keypoints”: a length
3karray wherekis the total number of keypoints defined for the category.Each keypoint has
a 0-indexed location
x, yvisible flag
vv=0: not labeled (in which casex=y=0)v=1: labeled but not visiblev=2: labeled and visibleA keypoint is considered visible if it falls inside the object segment.
For example,
(229, 256, 2)means there’s a keypoint at pixelx=229,y=256andv=2indicates that it is a visible keypoint
“num_keypoints”: indicates the number of labeled keypoints (
v>0) for a given object (many objects, e.g. crowds and small objects, will have num_keypoints=0).
Example
"annotations": [
{
"segmentation": [[204.01,306.23,...206.53,307.95]],
"num_keypoints": 15,
"area": 5463.6864,
"iscrowd": 0,
"keypoints": [229,256,2,...,223,369,2],
"image_id": 289343,
"bbox": [204.01,235.08,60.84,177.36],
"category_id": 1,
"id": 201376
}
]
Categories
Currently keypoints are only labeled for the person category (for most medium/large non-crowd person instances).
{
"id": int,
"name": str,
"supercategory": str,
"keypoints": [str],
"skeleton": [edge]
}
Compared to Object Detection, categories of keypoint detection has two additional fields
- “keypoints”: a length
karray of keypoint names - “skeleton”: defines connectivity via a list of keypoint edge pairs and is used for visualization.
- E.g.
[16, 14]means “left_ankle” connects to “left_knee”
- E.g.
Example
"categories": [
{
"supercategory": "person",
"id": 1,
"name": "person",
"keypoints": [
"nose","left_eye","right_eye","left_ear","right_ear",
"left_shoulder","right_shoulder","left_elbow","right_elbow",
"left_wrist","right_wrist","left_hip","right_hip",
"left_knee","right_knee","left_ankle","right_ankle"
],
"skeleton": [
[16,14],[14,12],[17,15],[15,13],[12,13],[6,12],[7,13],[6,7],
[6,8],[7,9],[8,10],[9,11],[2,3],[1,2],[1,3],[2,4],[3,5],[4,6],[5,7]
]
}
]
Visualization: see pycocoDemo.ipynb
MPII
- State of the art benchmark for evaluation of articulated human pose estimation.
- Includes around 25K images containing over 40K people with annotated body joints. The images were systematically collected using an established taxonomy of every day human activities.
- Overall the dataset covers 410 human activities and each image is provided with an activity label. Each image was extracted from a YouTube video and provided with preceding and following un-annotated frames.
Keypoints
| Id | Name |
|---|---|
| 0 | r ankle |
| 1 | r knee |
| 2 | r hip |
| 3 | l hip |
| 4 | l knee |
| 5 | l ankle |
| 6 | pelvis |
| 7 | thorax |
| 8 | upper neck |
| 9 | head top |
| 10 | r wrist |
| 11 | r elbow |
| 12 | r shoulder |
| 13 | l shoulder |
| 14 | l elbow |
| 15 | l wrist |

PoseTrack
PoseTrack is a large-scale benchmark for human pose estimation and tracking in image sequences. It provides a publicly available training and validation set as well as an evaluation server for benchmarking on a held-out test set.
Tasks
Single-frame Pose Estimation
- The aim of this task is to perform multi-person human pose estimation in single frames.
- It is similar to the ones covered by existing datasets like “MPII Human Pose” and MS COCO Keypoints Challenge.
- Note that this scenario assumes that body poses are estimated independently in each frame.
- Evaluation: The evaluation is performed using standard mean Average Precision (mAP) metric
Articulated People Tracking
- This task requires to provide temporally consistent poses for all people visible in the video. This means that in addition to pose estimation of each person, it is also required to track body joints of people.
- Evaluation: The evaluation will include both pose estimation accuracy as well as pose tracking accuracy.
- The pose estimation accuracy is evaluated using the stand mAP metric
- The evaluation of pose tracking is according to the CLEAR MOT metrics, the de-facto standard for evaluation of multi-target tracking.
- Trajectory-based measures are also evaluated that count the number of mostly tracked (MT), mostly lost (ML) tracks and the number of times a ground-truth trajectory is fragmented (FM).
Annotations
- Each person is labeled with a head bounding box and positions of the body joints.
- Omit annotations of people in dense crowds and in some cases also choose to skip annotating people in upright standing poses.
- Ignore regions to specify which people in the image where ignored during annotation.
- Each sequence included in the PoseTrack benchmark correspond to about 5 seconds of video. The number of frames in each sequence might vary as different videos were recorded with different number of frames per second (FPS).
- Training sequences: annotations for 30 consecutive frames centered in the middle of the sequence
- Validation and test sequences: annotate 30 consecutive frames and in addition annotate every 4-th frame of the sequence
Annotation Format
File format of PoseTrack 2018 is based on the Microsoft COCO dataset annotation format
.json Dictionary Structure
At top level, each .json file stores a dictionary with three elements:
images
A list of described images. The list must contain the information for all images referenced by a person description in the file.
Each list element is a dictionary and must contain only two fields
file_name: must refer to the original posetrack imageid(unique int)Example
has_no_densepose:true is_labeled:true file_name:"images/val/000342_mpii_test/000000.jpg" nframes:100 frame_id:10003420000 vid_id:"000342" id:10003420000
annotations
Another list of dictionaries
Each item of the list describes one detected person and is itself a dictionary. It must have at least the following fields:
image_id: int, an image with a corresponding id must be inimages,track_id- int, the track this person is performing
- unique per frame
keypoints: list of floats, length three times number of estimated keypoints in orderx, y, ?for every point. (The third value per keypoint is only there for COCO format consistency and not used.)Example
bbox_head: [] # 4 items keypoints: [] # 51 items track_id: 0 image_id: 10003420000 bbox: [] # 4 items scores: [] category_id: 1 id: 1000342000000
scores- list of float, length number of estimated keypoints
- each value between 0. and 1. providing a prediction confidence for each keypoint
categories
Must be a list containing precisely one item, describing the person structure
The dictionary must contain
name: personkeypoints: a list of strings which must be a superset of [nose,upper_neck,head_top,left_shoulder,right_shoulder,left_elbow,right_elbow,left_wrist,right_wrist,left_hip,right_hip,left_knee,right_knee,left_ankle,right_ankle]. (The order may be arbitrary.)Example
supercategory: "person" id: 1 name: "person" keypoints: [] # 17 items skeleton: [] # 19 items
Keypoints Annotations
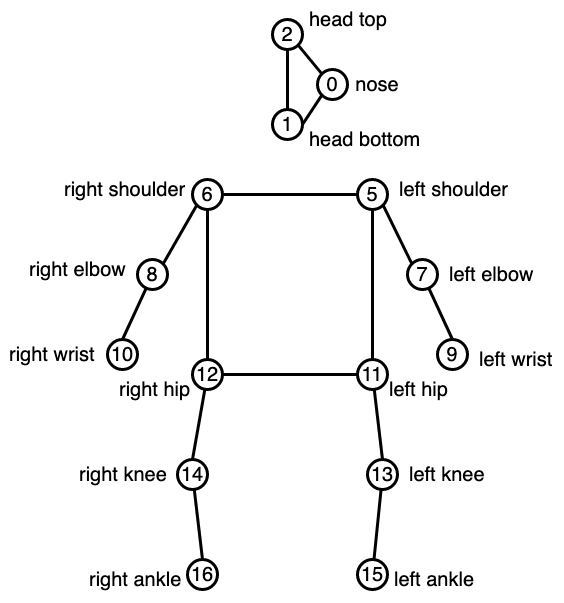
Keypoints annotations by PoseTrack are similar to COCO keypoints, except
left_eyeandright_eyeare changed tohead_bottomandhead_top, respectivelyAnnotations for ears are excluded. (I.e., only 15 keypoints are annotated)
Note: If you look at the annotation closely, there’re 51 elements in
keypointsdictionary (3 elements(x, y, v)for each keypoint). In other words, there’re still 17 annotated keypoints.
To (manually) exclude
left_earandright_ear, elements 9 to 14, which correpond to(x, y, v)ofleft_earandright_ear, are all set to 0.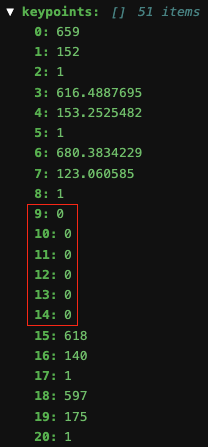
| id | COCO Keypoints | PoseTrack |
|---|---|---|
| 0 | nose | nose |
| 1 | left_eye | head_bottom |
| 2 | right_eye | head_top |
| 3 | left_ear | |
| 4 | right_ear | |
| 5 | left_shoulder | left_shoulder |
| 6 | right_shoulder | right_shoulder |
| 7 | left_elbow | left_elbow |
| 8 | right_elbow | right_elbow |
| 9 | left_wrist | left_wrist |
| 10 | right_wrist | right_wrist |
| 11 | left_hip | left_hip |
| 12 | right_hip | right_hip |
| 13 | left_knee | left_knee |
| 14 | right_knee | right_knee |
| 15 | left_ankle | left_ankle |
| 16 | right_ankle | right_ankle |
Visualization:
 |  |
|---|