Facial Expression Recognition
What is facial expression analysis?
What is Facial Expression?
Facial expressions are the facial changes in response to a person‘s internal emotional states, interntions, or social communications.
Role of facial expressions
- Almost the most powerful, natural, and immediate way (for human beings) to communicate emotions and intentions
- Face can express emotion sooner than people verbalize or realize feelings
- Faces and facial expressions are an important aspect in interpersonal communication and man-machine interfaces
Facial Expressions
- Facial expression(s):
nonverbal communication
voluntary / involuntary
results from one or more motions or positions of the muscles of the face
closely associated with our emotions
- The fact: Most people’s success rate at reading emotions from facial expression is only a little over 50 percent.
Facial expression analysis vs. Emotion analysis
Emotion analysis requires higher level knowledge, such as context information.
Besides emotions, facial expressions can also express intention, cognitive processes, physical effort, etc.
Emotions conveyed by Facial Expressions
Six basic emotions (assumed to be innate)

Basic structure of facial expression analysis systems
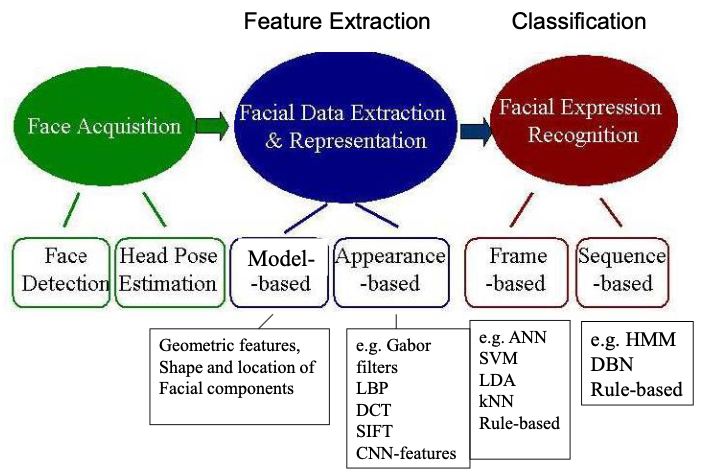
Levels of description
Emotions
Discrete classes
Six basic emotions

Positive, neutral, negative
Continuous valued dimensions
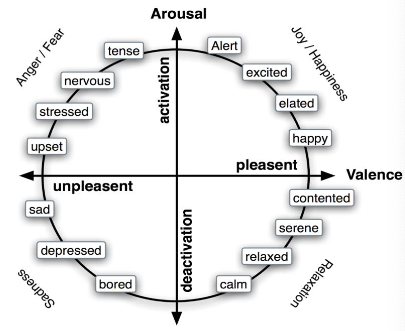
Emotions as a continuum along 2/3 dimension
Circumplex model by Russel
- Valence: unpleasant - pleasant
- Arousal: low – high activation
Facial Action Units (AUs)
Facial Action Coding System (FACS)
- A human-observer based system designed to detect subtle changes in facial features
- Viewing videotaped facial behavior in slow motion, trained observer can manually FACS code all possible facial displays
- These facial displays are referred to as action units (AU) and may occur individually or in combinations.
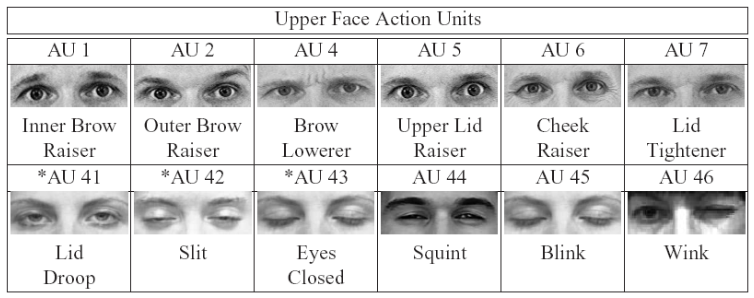
Action Units (AUs)
There are 44 AUs
30 AUs related to contractions of special facial muscles
12 AUs for upper face
18 AUs for lower face

Anatomic basis of the remaining 14 is unspecified $\rightarrow$ referred to in Facial Action Coding System (FACS) as miscellaneous actions
For action units that vary in intensity, a 5-point ordinal scale is used to measure the degree of muscle contraction
Combination of AUs
More than 7000 different AU combinations have been observed.
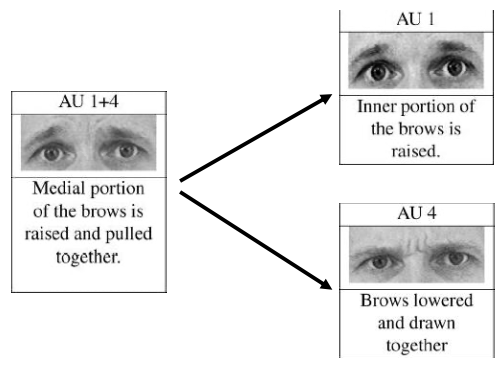
Additive: appearance of single AUs does NOT change. E.g.
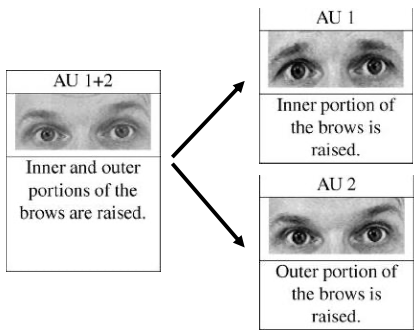
Nonadditive: appearance of single AUs does change. E.g.
Individual Differences in Subjects
Variations in appearance
Face shape,
Texture
Color
Facial and scalp hair
due to sex, ethnic background, and age differences
Variations in expressiveness
Transitions Among Expressions
Simplifying assumption: expressions are singular and begin and end with a neutral position
Transitions from action units or combination of actions to another may involve NO intervening neutral state.
Parsing the stream of behavior is an essential requirement of a robust facial analysis system, and training data are needed that include dynamic combinations of action units, which may be either additive or nonadditive.
Intensity of Facial Expression
Facial actions can vary in intensity
FACS coding uses 5-point intensity scale to describe intensity variation of action units
Some related action units function as sets to represent intensity variation.
E.g. in the eye region, action units 41, 42, and 43 or 45 can represent intensity variation from slightly drooped to closed eyes.

Relation to other Facial Behavior or Nonfacial Behavior
Facial expression is one of several channels of nonverbal communication.
The message values of various modes may differ depending on context.
For robustness, should be integrated with
Gesture
Prosody
Speech
Different datasets and systems
Using geometric features + ANN (2001 / early work)
Recognizing Action Units for Facial Expression Analysis1
An Automatic Facial Analysis (AFA) system to analyze facial expressions based on both permanent facial features (brows, eyes, mouth) and transient facial features (depending of facial furrows) in a nearly frontal-view image sequences.
A group of action units (neutral expression, six upper face AUs and 10 lower face AUs) are recognized whether they occur alone or in combinations.
Cohn-Kanade AU-Coded Facial Expression Database
100 subjects from varying ethnic backgrounds.
23 different facial expressions (single action units and combinations of action units)
Frontal faces, small head motion
Variations in lighting
- ambient lighting
- single-high-intensity lamp
- dual high-intensity lamps with reflective umbrellas
Coded with FACS and assigned emotion-specified labels (happy, surprise, anger, disgust, fear, sadness)
Example

Feature-based Automatic Facial Action Analysis (AFA) System
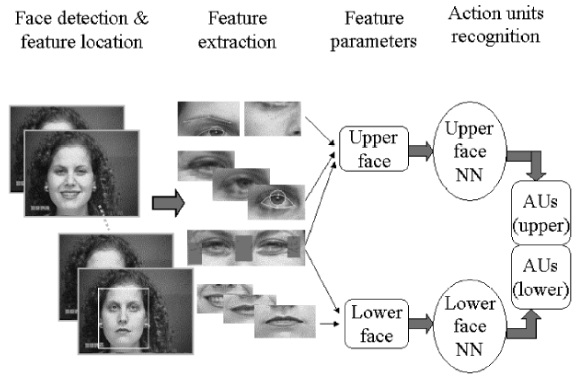
Feature detection & feature location
- Region of the face and location of individual face features detected automatically in the initial frame using neural network based approach
- Contours of face features and components adjusted manually in the initial frame
- Face features are then tracked automatically
- permanent features (e.g., brows, eyes, lips)
- transient features (lines and furrows)
Feature extraction: Group facial features into separate collections of feature parameters
- 15 normalized upper face parameters
- 9 normalized lower face parameters
Parameters fed to two neural-network-based classifiers
Facial Feature Extraction
Multistate Facial Component Models of a Frontal Face
- Permanent components/features
- Lip
- Eye
- Brow
- Cheek
- Transient component/features
- Furrows and wrinkles appear perpendicular to the direction of the motion of the activated muscles
- Classification
- present (appear, deepen or lengthen)
- absent
- Detection
- Canny edge detector
- Nasal root / crow’s-feet wrinkles
- Nasolabial furrows
Facial Feature Representation
Face coordinate system
- $x = $ line between inner corners of eyes
- $y = $ perpendicular to x
Group facial features
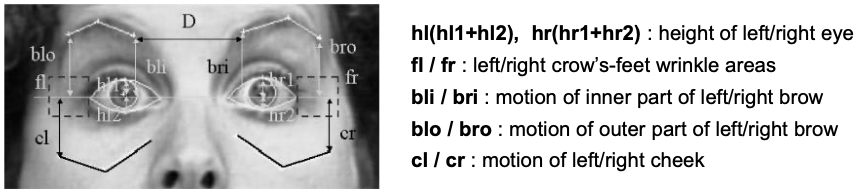
upper face features: 15 parameters
Example
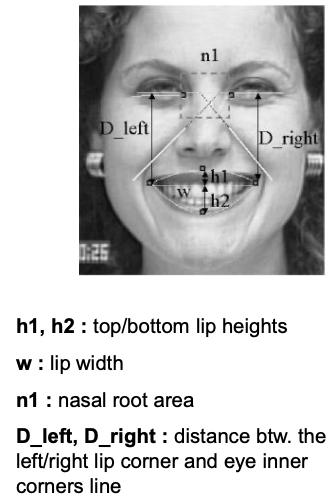
lower face features: 9 parameters
Example
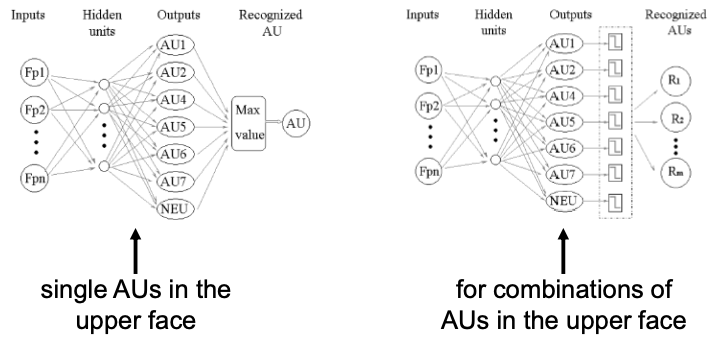
AU Recognition by Neural Networks
- Three layer neural networks (one hidden layer)
- Standard back-propagation method
- Separate networks for upper- / lower face
Using appearance-based features + SVM (2006)
Automatic Recognition of Facial Actions in Spontaneous Expression2
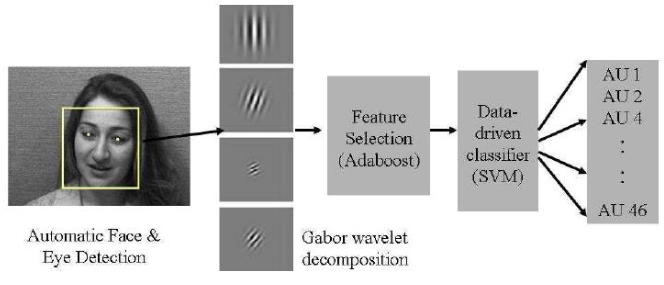
RU-FACS data set
- Containts spontaneous expressions
- 100 subjects

Using Deep features (CNN) + fusion (2013)
Emotion Recognition in the Wild Challenge (EmotiW)
🎯 Goal: Move to more realistic out of the lab data
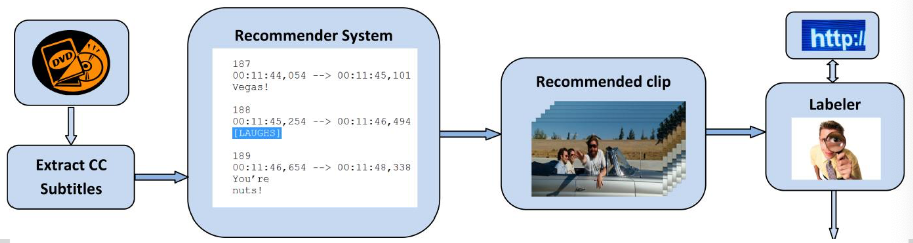
AFEW Dataset (Acted Facial Expressions in the Wild)
Extracted from movies
Annotated with six basic emotions
Movie clips from 330 subjects, age range: 1-70
Semi-automatic annotation pipeline
- Recommender sytem + manual annotation
2013 Winner
Combining Modality Specific Deep Neural Networks for Emotion Recognition in Video3
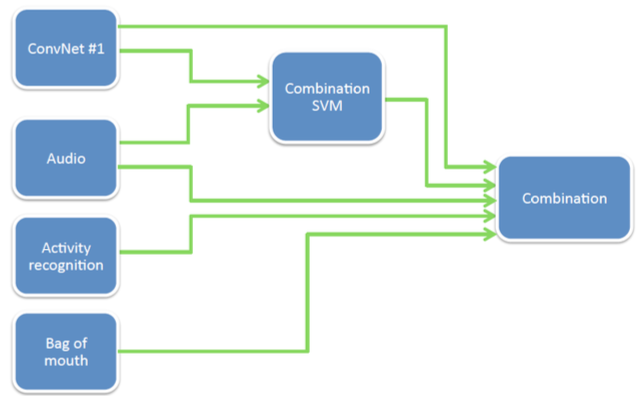
Convolutional Network
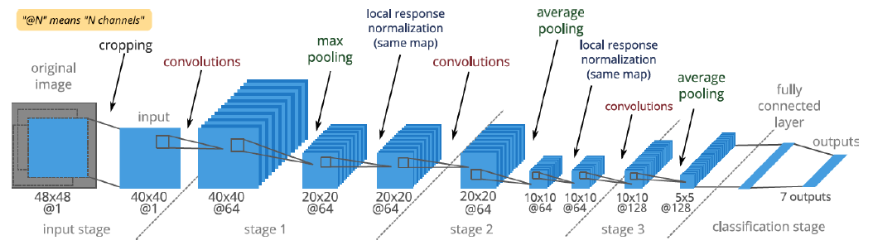
- Inputs are images of size 40x40, cropped randomly
- Four layers, 3 convolutions followed by max or average pooling and a fully-connected layer
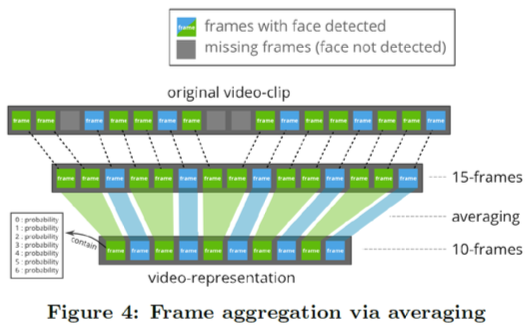
Representing video sequence
- CNN gives 7-dim output per frame
- Multiple frames are averaged into 10 vectors describing the sequence
- For shorter sequences, frames / vectors get expanded (duplicated)
- Results in 70-dim feature vector (10*7)
- Classification with SVM
Other Features
- „Bag of Mouth“
- Audio-features
Typical Pipline
Face detection and alignment
Extract various features and different representations
Build multiple classifiers
Fusion of results
Other Applications
- Pain Analysis
- Analysis of psychological disorders
- Workload / stress analysis
- Adaptive user interfaces
- Advertisment
Y. . -I. Tian, T. Kanade and J. F. Cohn, “Recognizing action units for facial expression analysis,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 23, no. 2, pp. 97-115, Feb. 2001, doi: 10.1109/34.908962. ↩︎
Littlewort, Gwen & Frank, Mark & Lainscsek, Claudia & Fasel, Ian & Movellan, Javier. (2006). Automatic Recognition of Facial Actions in Spontaneous Expressions. Journal of Multimedia. 1. 10.4304/jmm.1.6.22-35. ↩︎
Kahou, Samira Ebrahimi & Pal, Christopher & Bouthillier, Xavier & Froumenty, Pierre & Gulcehre, Caglar & Memisevic, Roland & Vincent, Pascal & Courville, Aaron & Bengio, Y. & Ferrari, Raul & Mirza, Mehdi & Jean, Sébastien & Carrier, Pierre-Luc & Dauphin, Yann & Boulanger-Lewandowski, Nicolas & Aggarwal, Abhishek & Zumer, Jeremie & Lamblin, Pascal & Raymond, Jean-Philippe & Wu, Zhenzhou. (2013). Combining modality specific deep neural networks for emotion recognition in video. ICMI 2013 - Proceedings of the 2013 ACM International Conference on Multimodal Interaction. 543-550. 10.1145/2522848.2531745. ↩︎