Action & Activity Recognition
Introduction
Motivation
Gain a higher level understanding of the scene, e.g.
- What are these persons doing (walking, sitting, working, hiding)?
- How are they doing it?
- What is going on in the scene (meeting, party, telephone conversation, etc…)?
Applications
- video indexing/analysis,
- smart-rooms,
- patient monitoring,
- surveillance,
- robots etc.
Actions, Activities
Event
- “a thing that happens or takes place”
- Examples
- Gestures
- Actions (running, drinking, standing up, etc.)
- Activities (preparing a meal, playing a game, etc.)
- Nature event (fire, storm, earthquake, etc.)
- …
Human actions
Def 1: Physical body motion
- E.g.: Walking, boxing, clapping, bending, …
Def 2: Interaction with environment on specific purpose
E.g.

Activities
- Complex sequence of action,
- Possibly performed by multiple humans,
- Typically longer temporal duration
- Examples
- Preparing a meal
- Having a meeting
- Shaking hands
- Football team scoring a goal
Actions / Activity Hierarchy
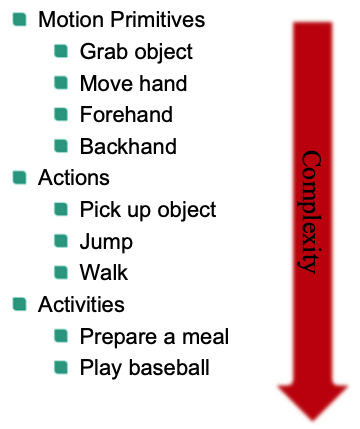
Example: Small groups (meetings)
- Individual actions: Speaking, writing, listening, walking, standing up, sitting down, “fidgeting”,…
- Group activities: Meeting start, end, discussion, presentation, monologue, dialogue, white board, note-taking
- Often audio-visual cues
Approaches
Time series classification problem similar to speech/gesture recognition
- Typical classifiers:
- HMMs and variants (e.g. Coupled HMMs, Layered HMMs) Dynamic
- Bayesian Networks (DBN)
- Recurrent neural networks
- Typical classifiers:
Classification problem similar to object recognition/detection
- Typical classifiers:
- Template matching
- Boosting
- Bag-of-Words SVMs
- Deep Learning approaches:
- 2D CNN (e.g. Two-Stream CNN, Temporal Segment Network)
- 3D CNN (e.g. C3D, I3D)
- LSTM on top of 2D/3D CNN
- Typical classifiers:
Recognition with local feature descriptors
- Try to model both Space and Time
- Combine spatial and motion descriptors to model an action
- Action == Space-time objects
- Transfer object detectors to action recognition
Space-Time Features + Boosting
💡 Idea
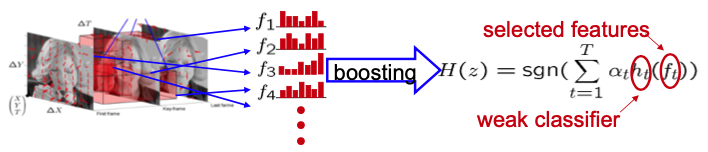
- Extract many features describing the relevant content of an image sequence
- Histogram of oriented gradients (HOG) to describe appearance
- Histogram of oriented flow (HOF) to describe motion in video
- Use Boosting to select and combine good features for classification
Action features
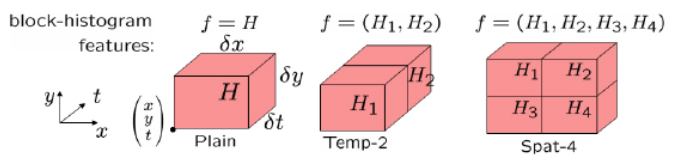
Action volume = space-time cuboid region around the head (duration of action)
Encoded with block-histogram features $f\_{\theta}(\cdot)$
$$ \theta=(x, y, t, d x, d y, d t, \beta, \varphi) $$- Location: $(x, y, t)$
- Space-time extent: $(d x, d y, d t)$
- Type of block: $\beta \in \\{\text{Plain, Temp-2, Spat-4}\\}$
- Type of histogram: $\varphi$
- Histogram of optical flow (HOF)
- Histogram of oriented gradient (HOG)
Example
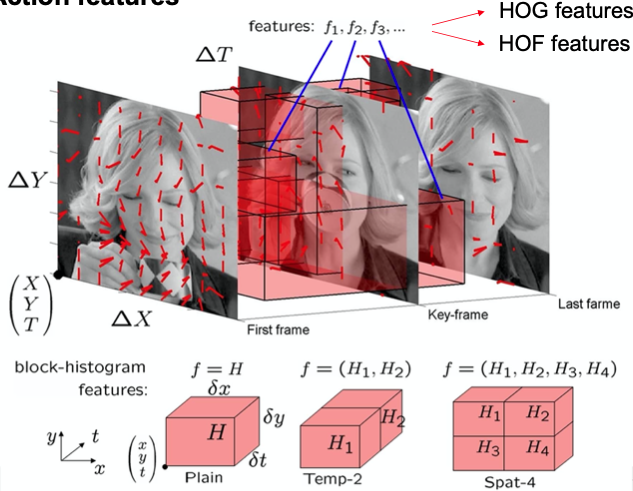
Histogram features
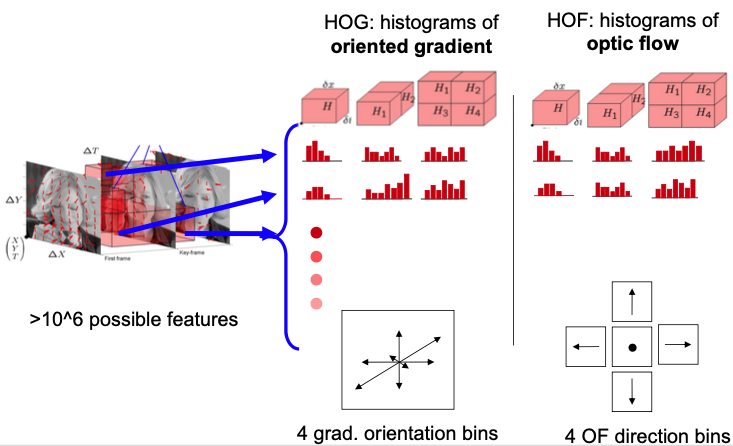
- (simplified) Histogram of oriented gradient (HOG)
- Apply gradient operator to each frame within sequence (eg. Sobel)
- Bin gradients discretized in 4 orientations to block-histogram
- Histogram of optical flow (HOF)
- Calculate optical flow (OF) between frames
- Bin OF vectors discretized in 4 direction bins (+1 bin for no motion) to block-histogram
- Normalized action cuboid has size 14x14x8 with units corresponding to 5x5x5 pixels
Action Learning
- Use boosting method (eg. AdaBoost) to classify features within an action volume
- Features: Block-histogram features
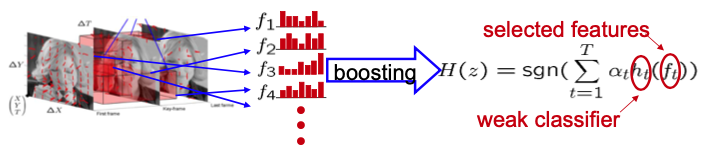
Boosting
A weak classifier h is a classifier with accuracy only slightly better than chance
Boosting combines a number of weak classifiers so that the ensemble is arbitrarily accurate

- Allows the use of simple (weak) classifiers without the loss if accuracy
- Selects features and trains the classifier
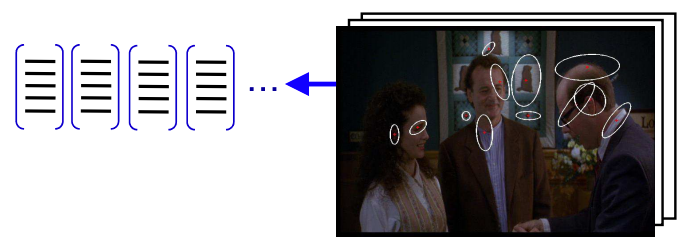
Space-Time Interest Points (STIP) + Bag-of-Words (BoW)
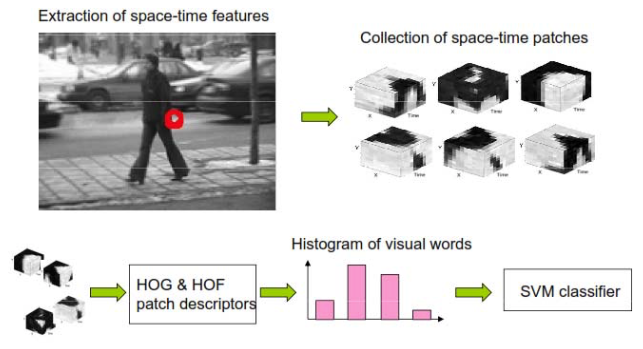
Inspired by Bag-of-Words (BoW) model for object classification
Bag-of-Words (BoW) model
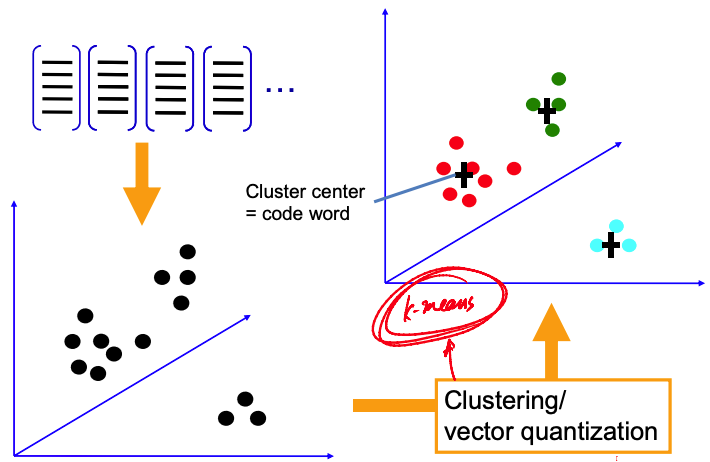
“Visual Word“ vocabulary learning
Cluster local features
Visual Words = Cluster Means
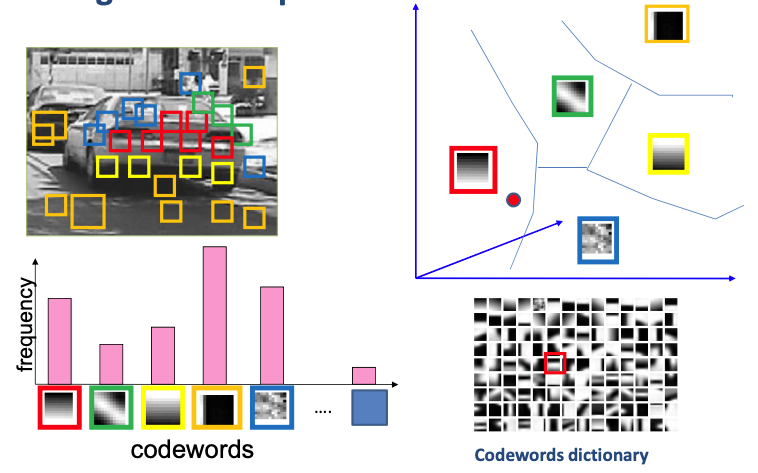
BoW feature calculation
Assign each local feature most similar visual word
BoW feature = Histogram of visual word occurances within a region
Histogram can be used to classify objects (wth. SVM)
Bag of Visual Words (Stanford CS231 slides)
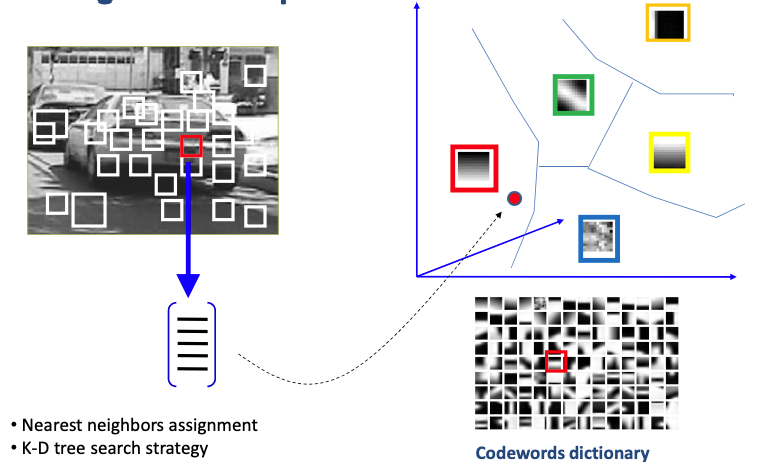
Feature detection and representation
Codewords dictionary formation
Bag of word representation
Space-Time Features: Detector
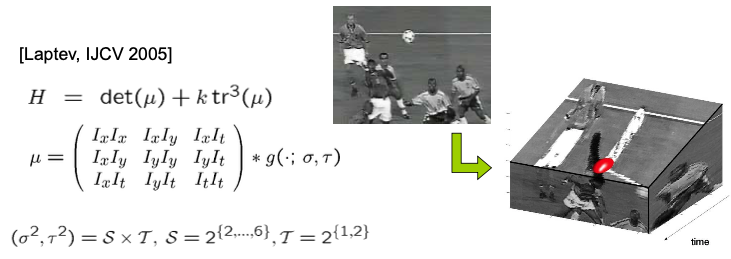
Space-Time Interest Points (STIP)
Space-Time Extension of Harris Operator
- Space-Time Extension of Harris Operator
- Add dimensionality of time to the second moment matrix
- Look for maxima in extended Harris corner function H
- Detection depends on spatio-temporal scale
- Extract features at multiple levels of spatio-temporal scales (dense scale sampling)
Space-Time Features: Descriptor
Compute histogram descriptors of space-time volumes in neighborhood of detected points
- Compute a 4-bin HOG for each cube in 3x3x2 space-time grid
- Compute a 5-bin HOF for each cube in 3x3x2 space-time grid
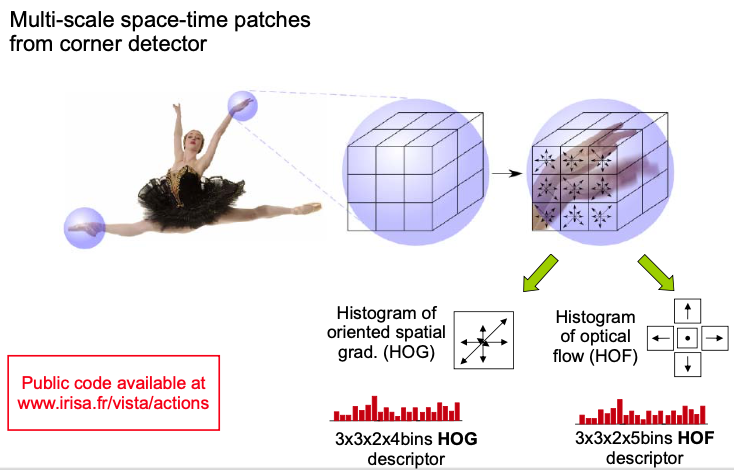
Action classification
Spatio-temporal Bag-of-Words (BoW)
Build Visual vocabulary of local feature representations using k-means clustering
Assign each feature in a video to nearest vocabulary word
Compute histogram of visual word occurrences over space time volume of a video squence
SVM classification
- Combine different feature types using multichannel $\chi^{2}$ Kernel
- One-against-all approach in case of multi-class classification
Dense Trajectories 1
- Dense sampling improves results over sparse interest points for image classification
- The 2D space domain and 1D time domain in videos have very different characteristics $\rightarrow$ use them both
Feature trajectories
- Efficient for representing videos
- Extracted using KLT tracker or matching SIFT descriptors between frames
- However, the quantity and quality is generally not enough 🤪
- State-of-the-art: The state of the art now describe videos by dense trajectories
Dense Trajectories
Obtain trajectories by optical flow tracking on densely sampled points
- Sampling
- Sample features points every 5th pixel
- Remove untrackable points (structure / Eigenvalue analysis)
- Sample points on eight different scales
- Tracking
- Tracking by median filtering in the OF-Field
- Trajectory length is fixed (e.g. 15 frames)
- Sampling
Feature tracking
Points of subsequent frames are concatenated to form a trajectory
Trajectories are limited to $L$ frames in order to avoid drift from their initial location
The shape of a trajectory of length $L$ is described by the sequence
$$ S=\left(\Delta P\_{t}, \ldots, \Delta P\_{t+L-1}\right) $$The resulting vector is normalized by
$$ \begin{array}{c} \Delta P\_{t}=\left(P\_{t+1}-P\_{t}\right)=\left(x\_{t+1}-x\_{t}, y\_{t+1}-y\_{t}\right) \\\\ S^{\prime}=\frac{\left(\Delta P\_{t}, \ldots, \Delta P\_{t+L-1}\right)}{\sum\_{j=t}^{t+L-1}\left\|\Delta P\_{j}\right\|} \end{array} $$
Trajectory descriptors
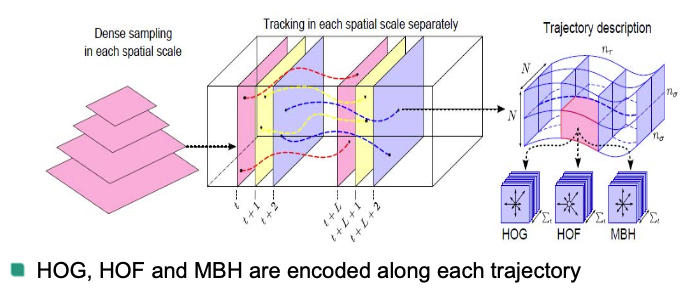
Histogram of Oriented Gradient (HOG)
Histogram of Optical Flow (HOF)
HOGHOF
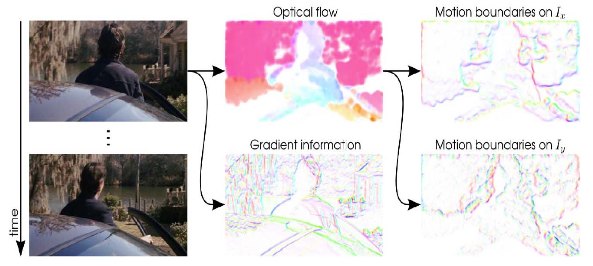
Motion Boundary Histogram (MBH)
- Take local gradients of x-y flow components and compute HOG as in static images
Wang, Heng, et al. “Dense trajectories and motion boundary descriptors for action recognition.” International journal of computer vision 103.1 (2013): 60-79. ↩︎