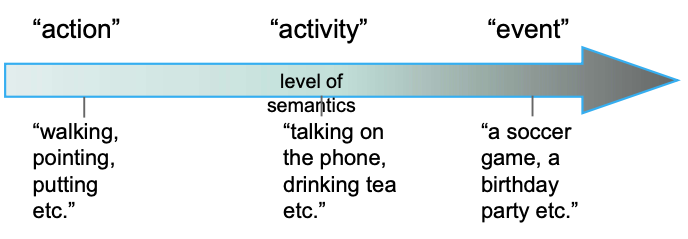
Action & Activity Recognition 2
What is action recognition?
Given an input video/image, perform some appropriate processing, and output the “action label”
CNNs for Action / Activity Recognition 1
Why CNN?
- Convolutional neural networks report the best performance in static image classification.
- They automatically learn to extract generic features that transfer well across data sets.
Strategies for temporal fusion
Single Frame CNN (baseline)
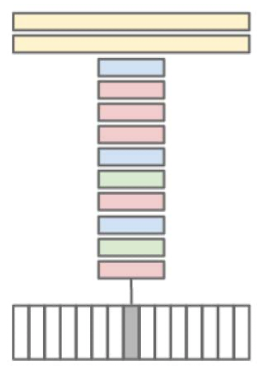
- Network sees one frame at a time
- No temporal information
Late Fusion CNN
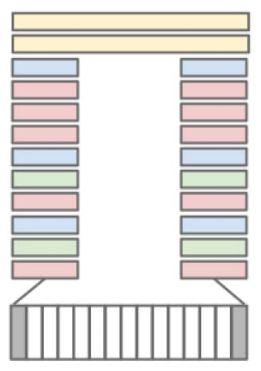
- Network sees two frames separated by F = 15 frames
- Both frames go into separate pathways
- Only the last layers have access to temporal information
Early Fusion CNN
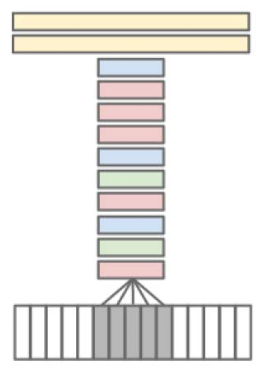
- Modify the convolutional filters in the first layer to incorporate temporal information.
- Filters of $11 \times 11 \times 3 \times T$ , where $T$ is the temporal context ($T=10$)
- Modify the convolutional filters in the first layer to incorporate temporal information.
Slow Fusion CNN
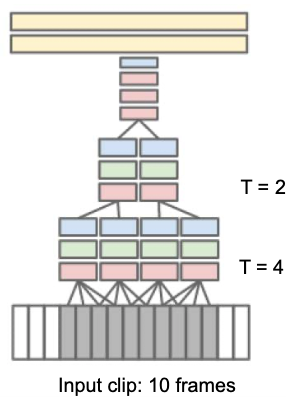
- Layers higher in the hierarchy have access to larger temporal context
- Learn motion patterns at different scales
Multiresolution CNN
Faster training by reducing input size from $170 \times 170$ to $89 \times 89$
💡 Idea: takes advantage of the camera bias present in many online videos, since the object of interest often occupies the center region.
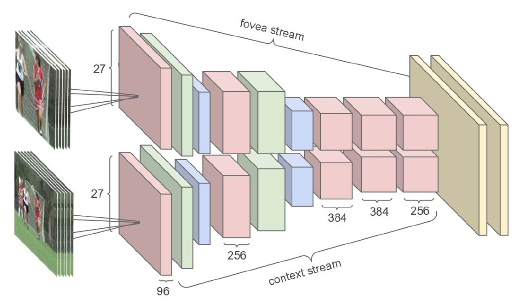
- The context stream receives the downsampled frames at half the original spatial resolution (89 × 89 pixels)
- The fovea stream receives the center 89 × 89 region at the original resolution
$\rightarrow$ The total input dimensionality is halved.
Evaluation
Dataset: Sports-1M (1 Million videos, 487 sport activities classes)
Encoding image and optical flow separately (two-stream CNNs) 2

3D convolutions for action recognition (C3D)

Notations:
video clips $\in c \times l \times h \times w$
- $c$: #channels
- $l$: length in number of frames
- $h, w$: height and width of the frame
3D convolution and pooling $\in d \times k \times k$
- $d$: kernel temporal depth
- $k$: kernel spatial size
C3D: 3 x 3 x 3 convolutions with stride 1 in space and time

Recurrent Convolutional Networks / CNN-RNN 3
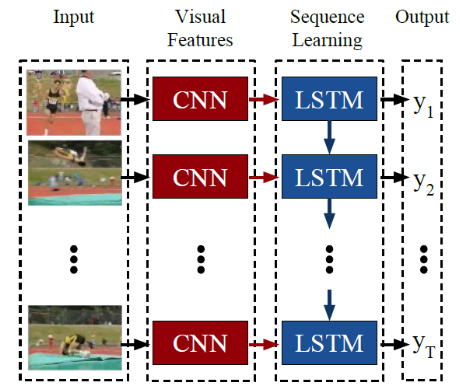
LRCN
- Task-specific instantiation
- Activity recognition (average frame representations)
- Image captioning (feed image info to each RNN)
- Video description (sequence-to-sequence models)
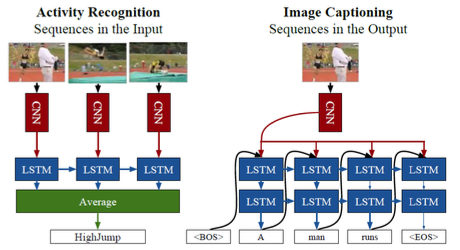
Comparison of architectures
Type of convolutional and layers operators
- 2D kernels (image-based) vs.
- 3D kernels (video-based)
Input streams
- RGB (spatial stream), usually used in single-stream networks
- Precomputed optical flow (temporal stream)
- Further streams possible (e.g. depth, human bounding boxes)
Fusion strategy across multiple frames
- Feature aggregation over time
- Recurrent layers, such as LSTM
$\rightarrow$ Modern architectures are usually a combination of the above!
Fair comparison of the architectures is difficult!
- different pre-training of models, some are trained from scratch
- Activity recognition datasets have been too small for analysis of deep learning approaches $\rightarrow$ pre-training matters even more
Evolution of Activity Recognition Datasets
- Construction of large-scale video datasets much harder then for images 🤪
- Common datasets too tiny for proper research of deep methods
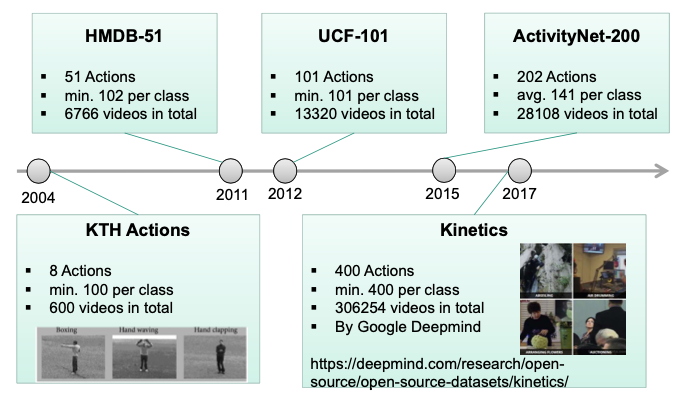
Evaluation of Action Recognition Architectures 4
Contributions
Release of the Kinetics dataset - a first large-scale dataset for Activity Recognition
Benchmarking of three „classic“ architectures for activity recognition
- Note: fair comparison is still quite difficult, since models still differ in their modalities and pre-training basis
New Architecture: I3D
- 3D CNN based Inception-V1 CNN (Google LeNet)
- “Inflation“ of trained 2-D filters in the 3-D Model
Evaluation of 3 “classic” architectures
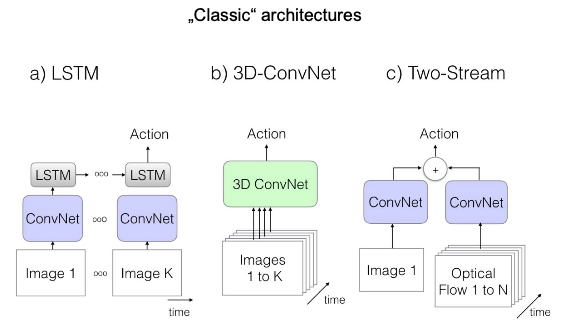
ConvNet + LSTM (9M Parameters)
- Underlying CNN for feature extraction: Inception-V1
- LSTM with 512 hidden units (after the last AvgPool layer) + FC layer
- Estimating the action from the resulting prediction Sequence:
- Training: output at each time-step used for loss calculation
- Testing: output of the last frame used for final prediction
- Pre-trained on ImageNet
- Preprocessing Steps: down-sampling from 25 to 5 fps
3D - ConvNet (79M Parameters)
- Spatio-temporal filters, C3D architecture
- High number of parameters $\rightarrow$ harder to train 🤪
- CNN Input: 16-frame snippets
- Classification: score averaging over each snippet in the video
- Trained from scratch
Two Stream CNN (12 M Parameters)
- Underlying CNN for feature extraction: Inception-V1
- Spatial (RGB) and Temporal (Optical Flow) streams trained separately
- Prediction by score averaging
- CNN Pre-trained on ImageNet
Evaluation
- Two-Stream are still the clear winners
- 3D-CNN show poor performance and very high number of parameters
- Note: this is the only architecture trained from scratch
Inflated 3D CNN (I3D)
💡 Idea: transfer the knowledge from the image recognition tasks in 3-D CNNs
I3-D Architecture
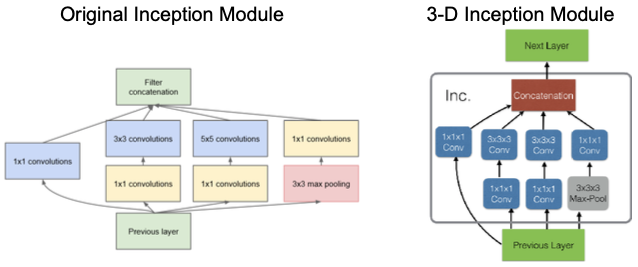
Inception-V1 architecture extended to 3D
Filters and pooling kernels inflated with the time dimension ($N \times N \rightarrow N \times N \times N$)
👍 Advantage: Pre-training on Image-Net possible (Learned weights of 2-D filters repeated N times along the time dimension)
Note: the 3-D extension is not fully symmetric in respect to pooling (Time dimension is different from the space dimensions)
- First two max-pooling layers do not perform temporal pooling
- Late max-pooling layers use symmetric 3x3x3 kernels
Evaluation
- I3D outperforms image-based approaches on each of the streams
- Combination of RGB input and optical flow still very useful
The role of pre-training
Pre-training on a video dataset (additionally to the Image-Net pre-training)
- Pre-training on MiniKinetics
- For 3D ConvNets, using additional data for pre-training is crucial
- For 2D ConvNets, the difference seems to be smaller
$\rightarrow$ Pre-training is crucial
$\rightarrow$ I3D is the new State-of-The art model
Karpathy, Andrej, et al. “Large-scale video classification with convolutional neural networks.” Computer Vision and Pattern Recognition (CVPR), 2014 ↩︎
K. Simonyan, and A. Zisserman. Two-Stream Convolutional Networks for Action Recognition in Videos. In NIPS 2015. ↩︎
J. Donahue, et al. Long-term Recurrent Convolutional Networks for Visual Recognition and Description. In CVPR 2015. ↩︎
Carreira, J., & Zisserman, A. (2017). Quo Vadis, action recognition? A new model and the kinetics dataset. Proceedings - 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, 2017-January, 4724–4733. https://doi.org/10.1109/CVPR.2017.502 ↩︎