YOLOv4: Training Tips
Model zoo
Pretrained models
Proper configuration based on GPU
We do NOT suggest you train the model with subdivisions equal or larger than 32, it will takes very long training time.
FAQ
Low accuracy 1
The most common problem - you do NOT follow strictly the manual.
- You must use
default anchorslearning_rate=0.001batch=64max_batches = max(6000, number_of_training_images, 2000*classes)
- You can only change
subdivisions - Do not do anything that is not written in the manual. 🙅♂️
Your datasets are wrong.
check the AP50 (average precision) for validation and training dataset by using
./darknet detector map obj.data yolo.cfg yolo.weightsIf you get high mAP for both Training and Validation datasets, but the network detects objects poorly in real life, then your training dataset is not representative –> add more images from real life to it
If you get high mAP for Training dataset, but low for Validation dataset, then your Training dataset isn’t suitable for Validation dataset.
For example
- Training dataset contains: cars (rear view) from distance 100m
- Test dataset contains: cars (side view) from distance 5m
if you get low mAP for both Training and Validation datasets, then labels in your Training dataset are wrong
- Run training with flag
-show_imgs, i.e../darknet detector train ... -show_imgs, do you see correct bounded boxes? - Or check your dataset by using Yolo_mark tool
- Run training with flag
Darknet training/detection crashes with an error 2
- If
CUDA Out of memoryerror occurs, then increasesubdivisions=2 times in cfg-file, but not higher thanbatch=(don’t change batch)!- If it doesn’t help - set
random=0andwidth=416 height=416in cfg-file.
- If it doesn’t help - set
- Check content of files
bad.listandbad_label.listif they exist near with./darknetexecutable file. - Do not move some files from Darknet folder - you may forget the necessary files.
- Download libraries CUDA, cuDNN, OpenCV, … only from official sources. Don’t download libs from other sites.
- Make sure that you do everything in accordance with the manual, and do not do anything that is not written in the manual.
Train with multiple GPUs 3
Train it first on 1 GPU for like 1000 iterations:
./darknet detector train cfg/coco.data cfg/yolov4.cfg yolov4.conv.137Then stop and by using partially-trained model
/backup/yolov4_1000.weights. Run training with multigpu (up to 4 GPUs):./darknet detector train cfg/coco.data cfg/yolov4.cfg /backup/yolov4_1000.weights -gpus 0,1,2,3If you get a Nan, then for some datasets better to decrease learning rate, for 4 GPUs set
learning_rate = 0,00065(i.e. learning_rate = 0.00261 / GPUs). In this case also increase 4x timesburn_in =in your cfg-file. I.e. useburn_in = 4000instead of1000.
Train custom datasets
Configuration setup see: Train YOLO v4 on Custom Dataset
Start training:
./darknet detector train data/obj.data <custom-cfg> yolov4.conv.137
File
<custom-cfg>_last.weightswill be saved tobackup/for each 100 iterationsFile
<custom-cfg>_xxxx.weightswill be saved tobackup/for each 1000 iterationsif you train on server without monitor, disable Loss-window by using argument
--dont_show. I.e../darknet detector train data/obj.data <custom-cfg> yolov4.conv.137 -dont_showTo see the mAP & Loss-chart during training on remote server without GUI, use
./darknet detector train data/obj.data <custom-cfg> yolov4.conv.137 -dont_show -mjpeg_port 8090 -mapThen open URL
http://ip-address:8090in browserFor training with mAP calculation for each 4 Epochs, you need to
set
valid=valid.txtortrain.txtinobj.datafilerun training with
-mapargument./darknet detector train data/obj.data <custom-cfg> yolov4.conv.137 -map
After training is complete - get result
yolo-obj_final.weightsfrombackup/After each 100 iterations you can stop and later start training from this point. For example, after 2000 iterations you can stop training, and later just start training using:
./darknet detector train data/obj.data <custom-cfg> backup/yolo-obj_2000.weightsYou can get result earlier than all 45000 iterations.
Notes 📝
If during training you see
nanvalues foravg(loss) field, then training goes wrong. 😭But if
nanis in some other lines, then training goes well. 🙏If you changed
width=orheight=in your cfg-file, then new width and height must be divisible by 32.If error
Out of memoryoccurs then in.cfg-file you should increasesubdivisions=16, 32 or 64
When should I stop training 4
Usually sufficient 2000 iterations for each class(object),
- but NOT less than number of training images and
- NOT less than 6000 iterations in total.
During training, you will see varying indicators of error, and you should stop when no longer decreases 0.XXXXXXX avg
For example
9002: 0.211667, 0.60730 avg, 0.001000 rate, 3.868000 seconds, 576128 images Loaded: 0.000000 seconds
- 9002 - iteration number (number of batch)
- 0.60730 avg - average loss (error) - the lower, the better
he final avgerage loss can be from
0.05(for a small model and easy dataset) to3.0(for a big model and a difficult dataset).if you train with flag
-mapthen you will see mAP indicator likeLast accuracy mAP@0.5 = 18.50%in the console. This indicator is better than Loss, so keep training while mAP increases.
Choose the best weights
Once training is stopped, you should take some of last .weights-files from backup/ and choose the best of them.
For example, you stopped training after 9000 iterations, but the best result can give one of previous weights (7000, 8000, 9000). It can happen due to overfitting.
In order to choose best weight, just train with -map flag
./darknet detector train data/obj.data <custom-cfg> yolov4.conv.137 -dont_show -map
So you will see mAP-chart (red-line) in the Loss-chart Window looks like the following figure. mAP will be calculated for each 4 Epochs using valid=valid.txt file that is specified in obj.data file (1 Epoch = images_in_train_txt / batch iterations)
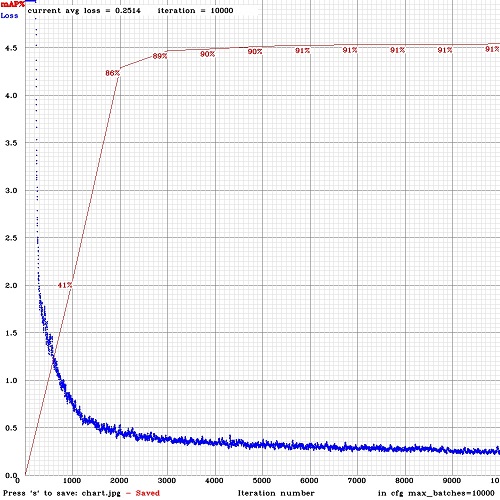
How to improve object detection5
Before training
Set flag
random=1in your.cfg-file - it will increase precision by training Yolo for different resolutionsincrease network resolution in your
.cfg-file (height=608,width=608or any value multiple of 32) - it will increase precisionCheck that each object that you want to detect is mandatory labeled in your dataset - no one object in your data set should not be without label.
- In the most training issues, there are wrong labels in your dataset. Always check your dataset by using: https://github.com/AlexeyAB/Yolo_mark
My Loss is very high and mAP is very low, is training wrong?
–> Run training with
-show_imgsflag at the end of training command, do you see correct bounded boxes of objects? If no, your training dataset is wrong.For each object which you want to detect - there must be at least 1 similar object in the Training dataset with about the same: shape, side of object, relative size, angle of rotation, tilt, illumination.
- So desirable that your training dataset include images with objects at diffrent: scales, rotations, lightings, from different sides, on different backgrounds
- You should preferably have 2000 different images for each class or more, and you should train
2000*classesiterations or more
Desirable that your training dataset include images with non-labeled objects that you do not want to detect, i.e. negative samples without bounded box (empty
.txtfiles). Use as many images of negative samples as there are images with objects.More see: https://github.com/AlexeyAB/darknet#how-to-improve-object-detection
After training, for detection:
Increase network-resolution by set in your
.cfg-file (height=608andwidth=608) or (height=832andwidth=832) or (any value multiple of 32). This increases the precision and makes it possible to detect small objects.It is not necessary to train the network again, just use
.weights-file already trained for 416x416 resolutionTo get even greater accuracy you should train with higher resolution 608x608 or 832x832.
- Note: if error
Out of memoryoccurs then in.cfg-file you should increasesubdivisions=16, 32 or 64
- Note: if error
Other questions
Will darknet automaticly resize the image size?
Yes (see: https://github.com/AlexeyAB/darknet/issues/5842)
Does the network have to be perfectly square?
No.
The default network sizes in the common template configuration files is defined as 416x416 or 608x608, but those are only examples!
Choose a size that works for you and your images. The only restrictions are:
- the width has to be evenly divisible by 32
- the height has to be evenly divisible by 32
- you must have enough video memory to train a network of that size
Whatever size you choose, Darknet will stretch (without preserving the aspect ratio!) your images to be exactly that size prior to processing the image. This includes both training and inference. So use a size that makes sense for you and the images you need to process, but remember that there are important speed and memory limitations. The larger the size, the slower it will be to train and run, and the more GPU memory will be required.
See:
https://www.ccoderun.ca/programming/2020-09-25_Darknet_FAQ/#square_network
Detection with aspect ratio change
- First of all, the high network resolution is important (the higher - the better). I.e. 800 x 800 will be better than 736 x 416, even if your input image 1600 x 900.
- And only In second place in importance is the aspect ratio.
See: https://github.com/AlexeyAB/darknet/issues/131
Useful resources
- Tips from Roboflow: YOLOv4 - Ten Tactics to Build a Better Model
- Articles from Aleksey Bochkovskiy (author of YOLOv4)
- DARKNET FAQ