CNN History
LeNet (1998)
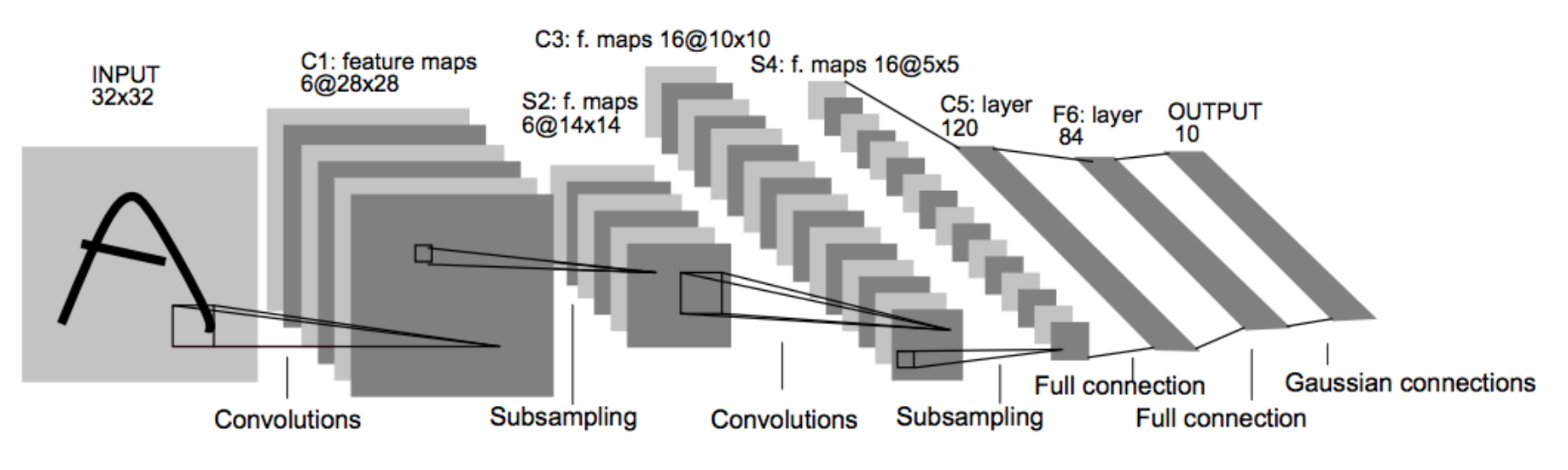
Image followed by multiple convolutional / pooling layers
Build up hierarchical filter structures
Subsampling / pooling increases robustness
Fully connected layers towards the end
- Brings all information together, combines it once more
Output layer of 10 units, one for each digit class
ImageNet Dataset (2009)

Standard benchmark for vision:
- 1.2 M images
- 1000 classes
- > 500 images per class
ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
- ILSVRC Classification Task
- 1000 object classes
- 1.2 million training images (732 – 1300 per class)
- 50 thousand validation images (50 per class)
- 100 thousand test images (100 per class)
AlexNet (2012)
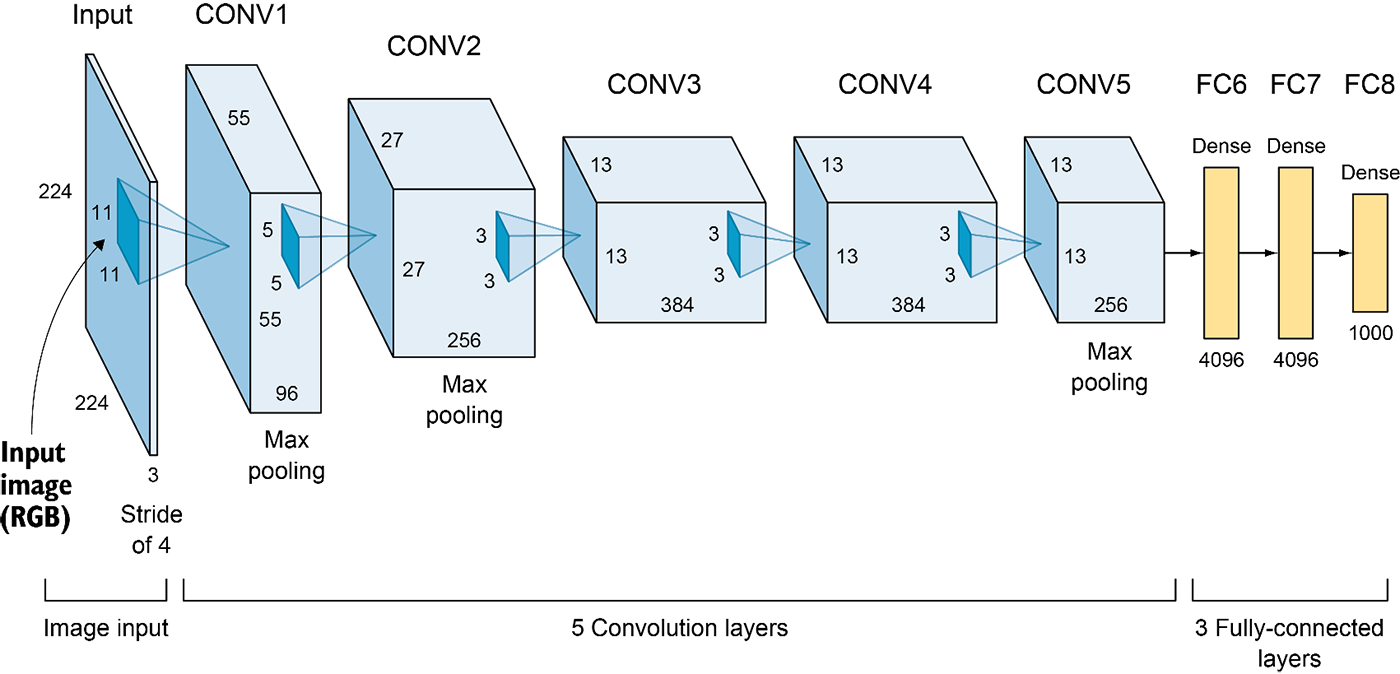
Multiple convolutional layers
Couple fully connected (dense) layers
Final classification using a “soft-max” layer
Train end-to-end via back propagation
Details
- first use of ReLU
- used Norm layers (not common anymore)
- heavy data augmentation
- dropout 0.5
- batch size 128
- SGD Momentum 0.9
- Learning rate 1e-2, reduced by a factor of 10 manually when val accuracy plateaus
- L2 weight decay 5e-4
VGG Net (2014)
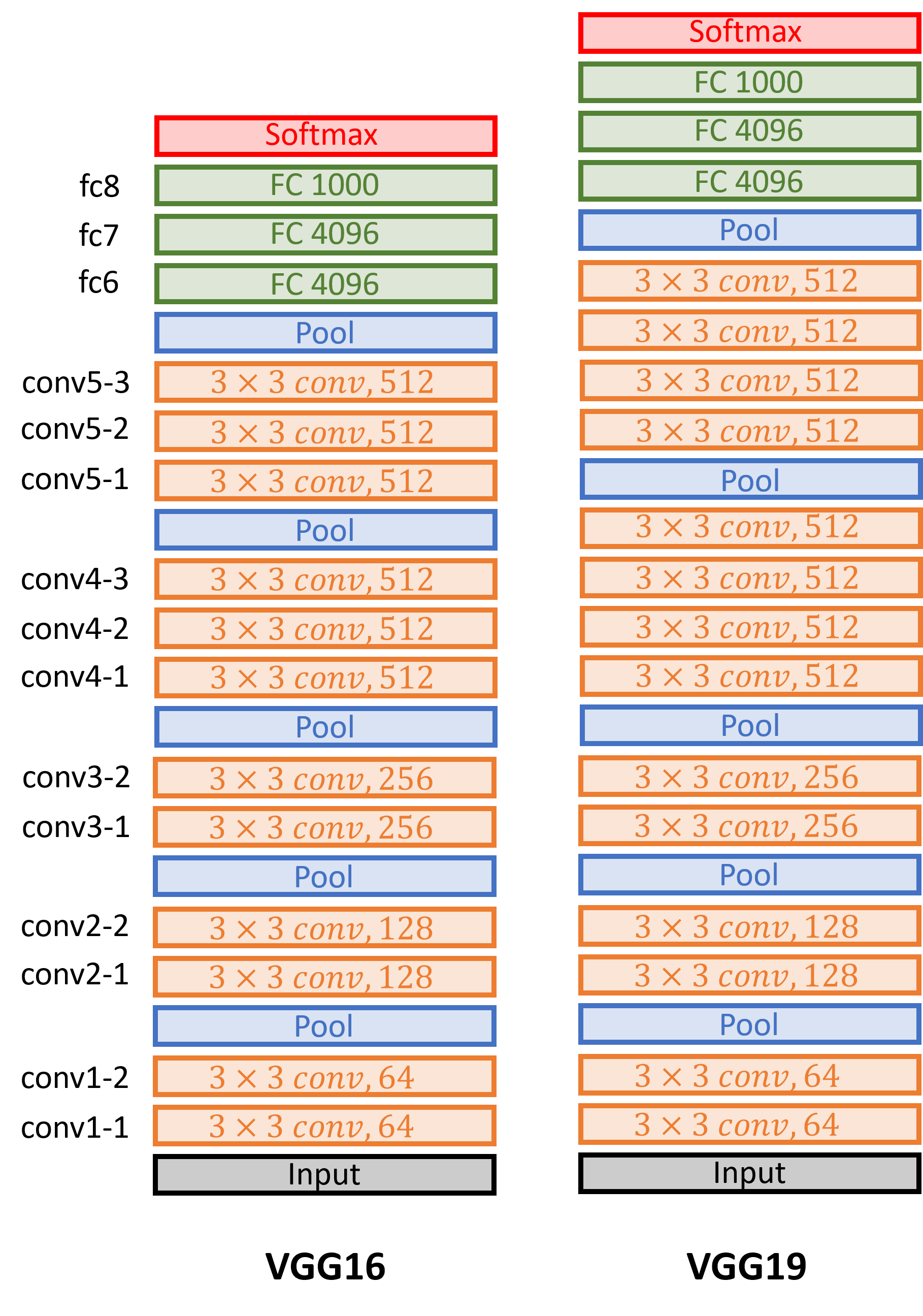
Small filters, Deeper networks
- 8 layers (AlexNet) -> 16 - 19 layers (VGG16Net)
- Only 3x3 CONV stride 1, pad 1
- and 2x2 MAX POOL stride 2
ResNet (2015)
Residual blocks
How can we train such deep networks?
Solution: Use network layers to fit a residual mapping instead of directly trying to fit a
desired underlying mapping
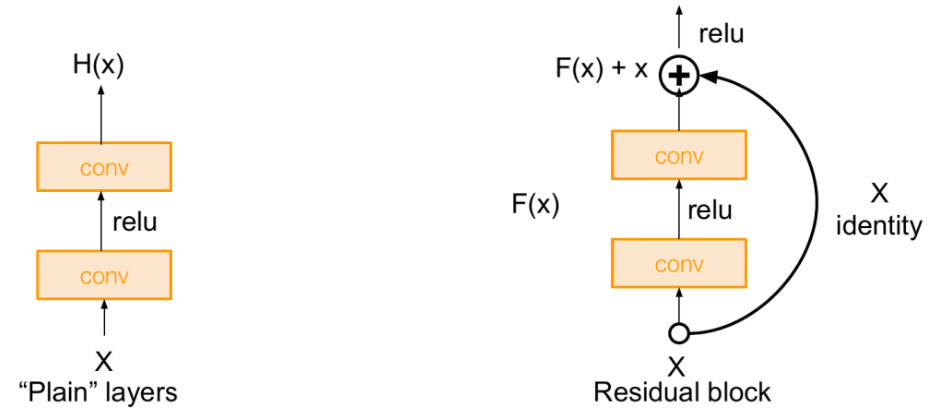
- Use layers to fit residual $F(x) = H(x) – x$ instead of $H(x)$ directly
- Initially, $F(x)$ is set to 0, so the layer just computes the identity
- I.e. adding more layers does not harm 👏
ResNet Architecture
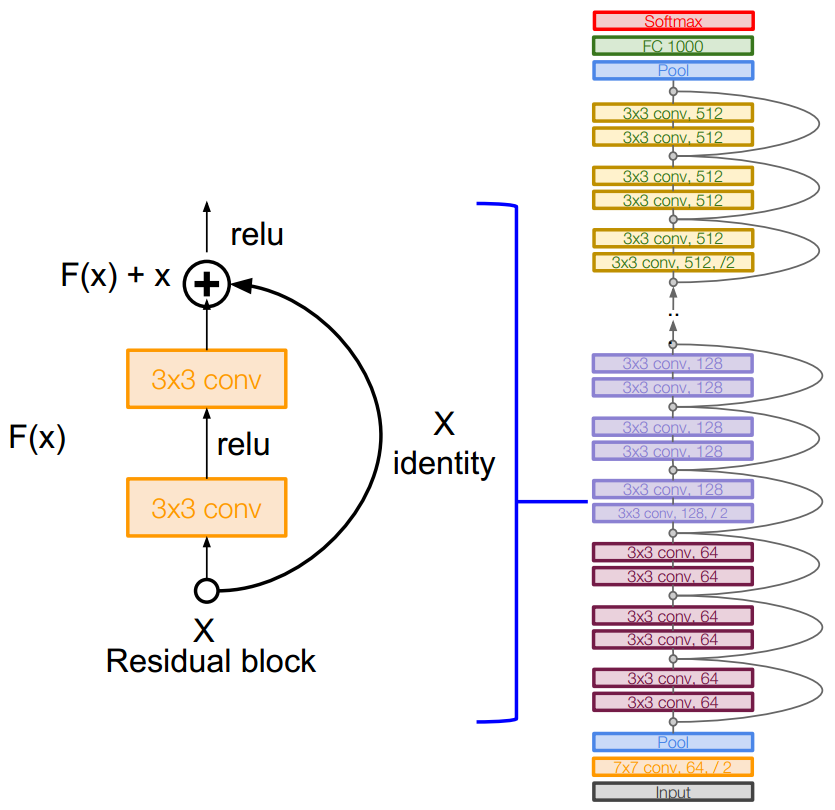
- Stack residual blocks
- Every residual block has two 3x3 conv layers
- Periodically, double # of filters and downsample spatially using stride 2 (/2 in each dimension)
- Additional conv layer at the beginning
- No FC layers at the end (only FC 1000 to output classes)
Training ResNet in practice
- Batch Normalization after every CONV layer (not covered)
- Xavier 2/ initialization from He et al.
- SGD + Momentum (0.9)
- Learning rate: 0.1, divided by 10 when validation error plateaus
- Mini-batch size 256
- Weight decay of 1e-5
- No dropout used
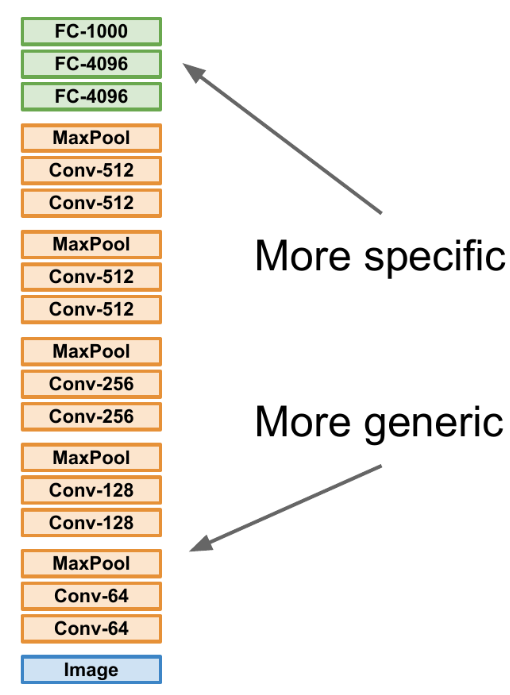
Transfer Learning
ImageNet has 1.2 million images! Typically, we do not have that many! Can we also use these methods with less images?
Yes! With transfer learning!
- Features (conv layers) are generic and can be reused!
How?
- Train on huge data-set (e.g. Imagenet)
- Freeze layers and adapt only last (FC) layers

Pratical Advice
Very little data, very similar dataset:
- Use Linear classifier on top layer
Very little data, very different dataset:
- You’re in trouble… Try linear classifier from different stages and pray 🤪
A lot of data, very similar dataset:
- Finetune a few layers
A lot of data, very different dataset:
- Finetune a larger number of layers
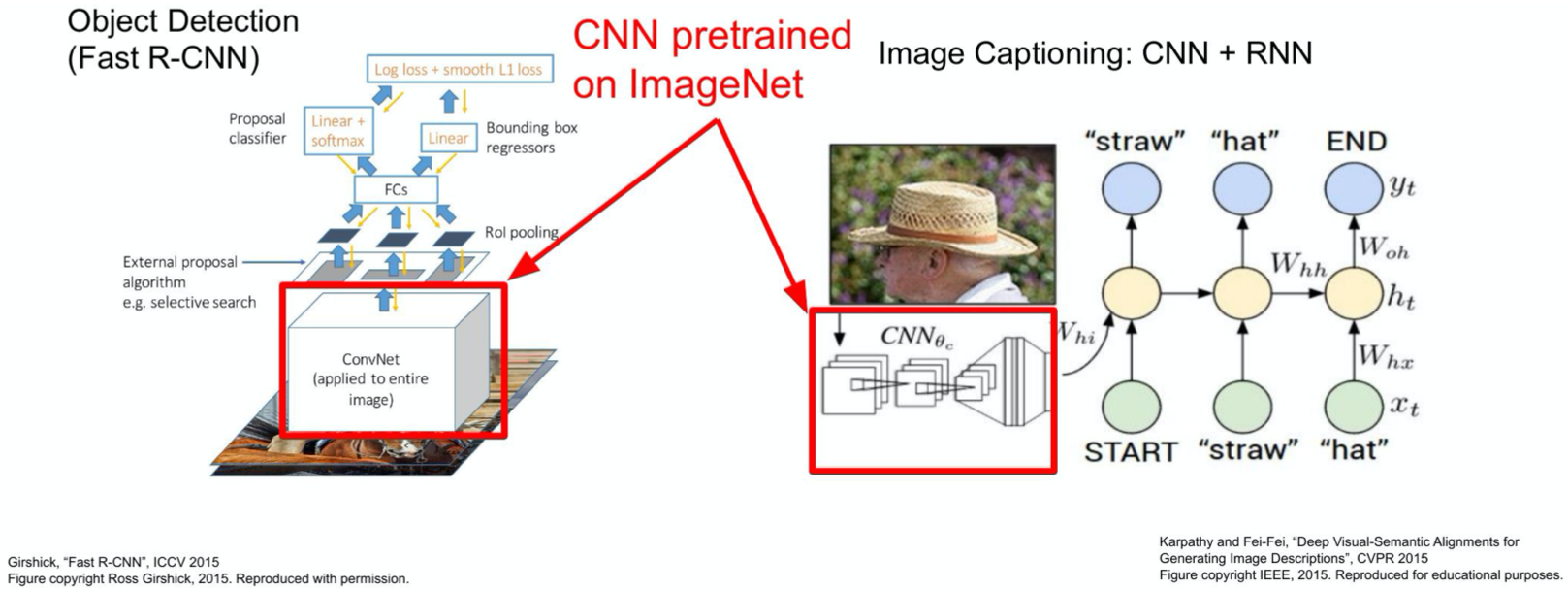
Example: Image Captioning
Example: Face Recognition
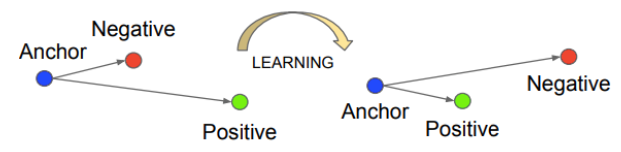
Siamese Networks (FaceNet)
Distance
$$ d\left(x\_{1}, x\_{2}\right)=\left\|f\left(x\_{1}\right)-f\left(x\_{2}\right)\right\|\_{2}^{2} $$- If $d(x\_1, x\_2)$ small: same person
- Otherwise different person
Training: Triplet loss
$$ L(A, P, N)=\max \left(\|f(A)-f(P)\|^{2}-\|f(A)-f(N)\|^{2}+\alpha, 0\right) $$