Linear Discriminant Functions
- No assumption about distributions -> non-parametric
- Linear decision surfaces
- Begin by supervised training (given class of training data)
Linear Discriminant Functions and Decision Surfaces
A discriminant function that is a linear combination of the components of $x$ can be written as
$$ g(\mathbf{x})=\mathbf{w}^{T} \mathbf{x}+w\_{0} $$- $\mathbf{x}$: feature vector
- $\mathbf{w}$: weight vector
- $w\_0$: bias or threshold weight
The two category case
Decision rule:
- Decide $w\_1$ if $g(\mathbf{x}) > 0 \Leftrightarrow \mathbf{w}^{T} \mathbf{x}+w\_{0} > 0 \Leftrightarrow \mathbf{w}^{T} \mathbf{x}> -w\_{0}$
- Decide $w\_{2}$ if $g(\mathbf{x}) < 0 \Leftrightarrow \mathbf{w}^{T} \mathbf{x}+w\_{0} < 0 \Leftrightarrow \mathbf{w}^{T} \mathbf{x}<-w\_{0}$
- $g(\mathbf{x}) = 0$: assign to either class or can be left undefined
The equation $g(\mathbf{x}) = 0$ defines the decision surface that separates points assigned to $w\_{1}$ from points assigned to $w\_{2}$. When $g(\mathbf{x})$ is linear, this decision surface is a hyperplane.
For arbitrary $\mathbf{x}\_1$ and $\mathbf{x}\_2$ on the decision surface, we have:
$$ \mathbf{w}^{\mathrm{T}} \mathbf{x}\_{1}+w\_{0}=\mathbf{w}^{\mathrm{T}} \mathbf{x}\_{2}+w\_{0} $$ $$ \mathbf{w}^{\mathrm{T}}\left(\mathbf{x}\_{1}-\mathbf{x}\_{2}\right)=0 $$$\Rightarrow \mathbf{w}$ is normal to any vector lying in the hyperplane.
In general, the hyperplane $H$ divides the feature space into two half-spaces:
- decision region $R\_1$ for $w\_1$
- decision region $R\_2$ for $w\_2$
Because $g(\mathbf{x}) > 0$ if $\mathbf{x}$ in $R\_1$, it follows that the normal vector $\mathbf{w}$ points into $R\_1$. Therefore, It is sometimes said that any $\mathbf{x}$ in $R\_1$ is on the positive side of $H$, and any $\mathbf{x}$ in $R\_2$ is on the negative side of $H$
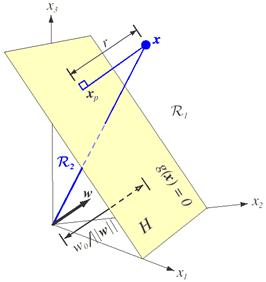
The discriminant function $g(\mathbf{x})$ gives an algebraic measure of the distance from $\mathbf{x}$ to the hyperplane. We can write $\mathbf{x}$ as
$$ \mathbf{x}=\mathbf{x}\_{p}+r \frac{\mathbf{w}}{\|\mathbf{w}\|} $$- $\mathbf{x}\_{p}$: normal projection of $\mathbf{x}$ onto $H$
- $r$: desired algebraic distance which is positive if $\mathbf{x}$ is on the positive side, else negative
As $\mathbf{x}\_p$ is on the hyperplane
$$ \begin{array}{ll} g\left(\mathbf{x}\_{p}\right)=0 \\\\ \mathbf{w}^{\mathrm{T}} \mathbf{x}\_{p}+w\_{0}=0 \\\\ \mathbf{w}^{\mathrm{T}}\left(\mathbf{x}-r \frac{\mathbf{w}}{\|\mathbf{w}\|}\right)+w\_{0}=0 \\\\ \mathbf{w}^{\mathrm{T}} \mathbf{x}-r \frac{\mathbf{w}^{\mathrm{T}} \mathbf{w}}{\|\mathbf{w}\|}+w\_{0}=0 \\\\ \mathbf{w}^{\mathrm{T}} \mathbf{x}-r\|\mathbf{w}\| + w\_0 = 0 \\\\ \underbrace{\mathbf{w}^{\mathrm{T}} \mathbf{x} + w\_0}\_{=g(\mathbf{x})} = r\|\mathbf{w}\| \\\\ \Rightarrow g(\mathbf{x}) = r\|\mathbf{w}\| \\\\ \Rightarrow r = \frac{g(\mathbf{x})}{\|\mathbf{w}\|} \end{array} $$In particular, the distance from the origin to hyperplane $H$ is given by $\frac{w_0}{\|\mathbf{w}\|}$
- $w\_0 > 0$: the origin is on the positive side of $H$
- $w\_0 < 0$: the origin is on the negative side of $H$
- $w\_0 = 0$: $g(\mathbf{x})$ has the homogeneous form $\mathbf{w}^{\mathrm{T}} \mathbf{x}$ and the hyperplane passes through the origin
A linear discriminant function divides the feature space by a hyperplane decision surface:
- orientation: determined by the normal vector $\mathbf{w}$
- location: determined by the bias $w\_0$