Named-Entity Recognition
What is NER?
Named entity
- anything that can be referred to with a proper name: a person, a location, an organization.
- commonly extended to include things that aren’t entities per se, including dates, times, and other kinds of temporal expressions, and even numerical expressions like prices.
Sample text with the named entities marked:

The text contains 13 mentions of named entities including
- 5 organizations
- 4 locations
- 2 times
- 1 person
- 1 mention of money.
Typical generic named entity types

Named Entity Recognition
Named Entity Recognition: find spans of text that constitute proper names and then classifying the type of the entity
Difficulty:
Ambiguity of segmentation: we need to decide what’s an entity and what isn’t, and where the boundaries are.
Type ambiguity: Some named entity can have many types (cross-type confusion)
Example

NER as Sequence Labeling
The standard algorithm for named entity recognition is as a word-by-word sequence labeling task
- The assigned tags capture both the boundary and the type.
A sequence classifier like an MEMM/CRF, a bi-LSTM, or a transformer is trained to label the tokens in a text with tags that indicate the presence of particular kinds of named entities.
Consider the following simplified excerpt:
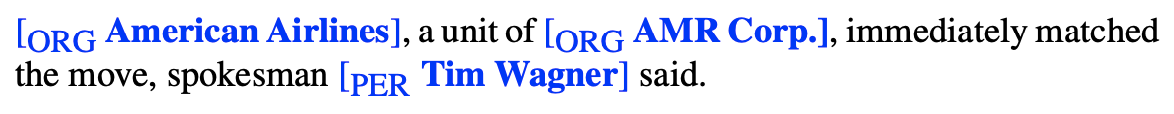
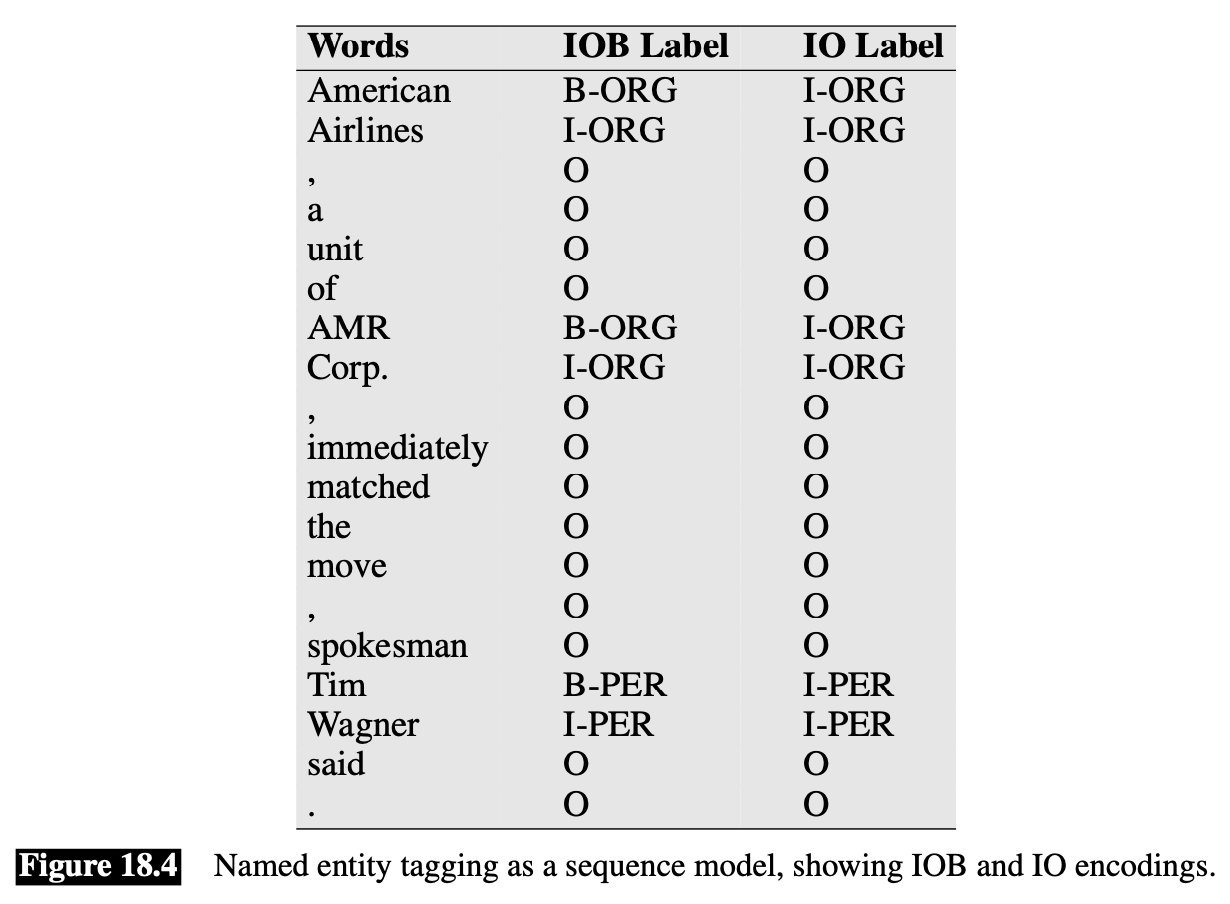
We represent the excerpt with IOB tagging
In IOB tagging we introduce a tag for the beginning (B) and inside (I) of each entity type, and one for tokens outside (O) any entity. The number of tags is thus 2n + 1 tags, where n is the number of entity types.
In IO tagging it loses some information by eliminating the B tag. Without the B tag IO tagging is unable to distinguish between two entities of the same type that are right next to each other. Since this situation doesn’t arise very often (usually there is at least some punctuation or other deliminator), IO tagging may be sufficient, and has the advantage of using only n + 1 tags.
Feature-based Algorithm for NER
💡 Extract features and train an MEMM or CRF sequence model of the type like in POS.
Standard features:

Word shape features are particularly important in the context of NER.
Word shape:
represent the abstract letter pattern of the word by mapping
- lower-case letters to ‘x’,
- upper-case to ‘X’,
- numbers to ’d’,
- and retaining punctuation
Example
I.M.F–>X.X.XDC10-30–>XXdd-dd
Second class of shorter word shape:
- Consecutive character types are removed
- Example
I.M.F–>X.X.XDC10-30–>Xd-d
For example the named entity token L’Occitane would generate the following non-zero valued feature values:

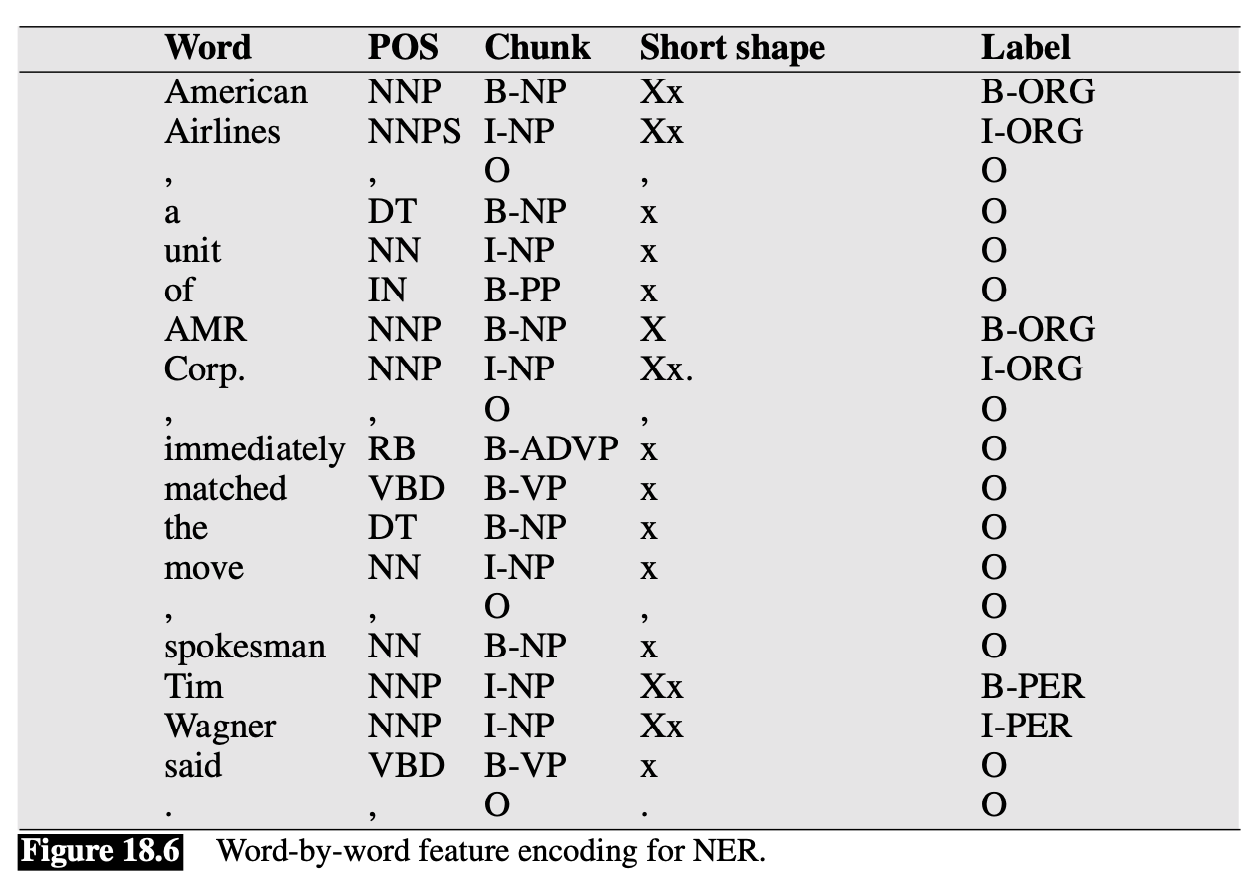
The following figure illustrates the result of adding part-of-speech tags, syntactic base- phrase chunk tags, and some shape information to our earlier example.
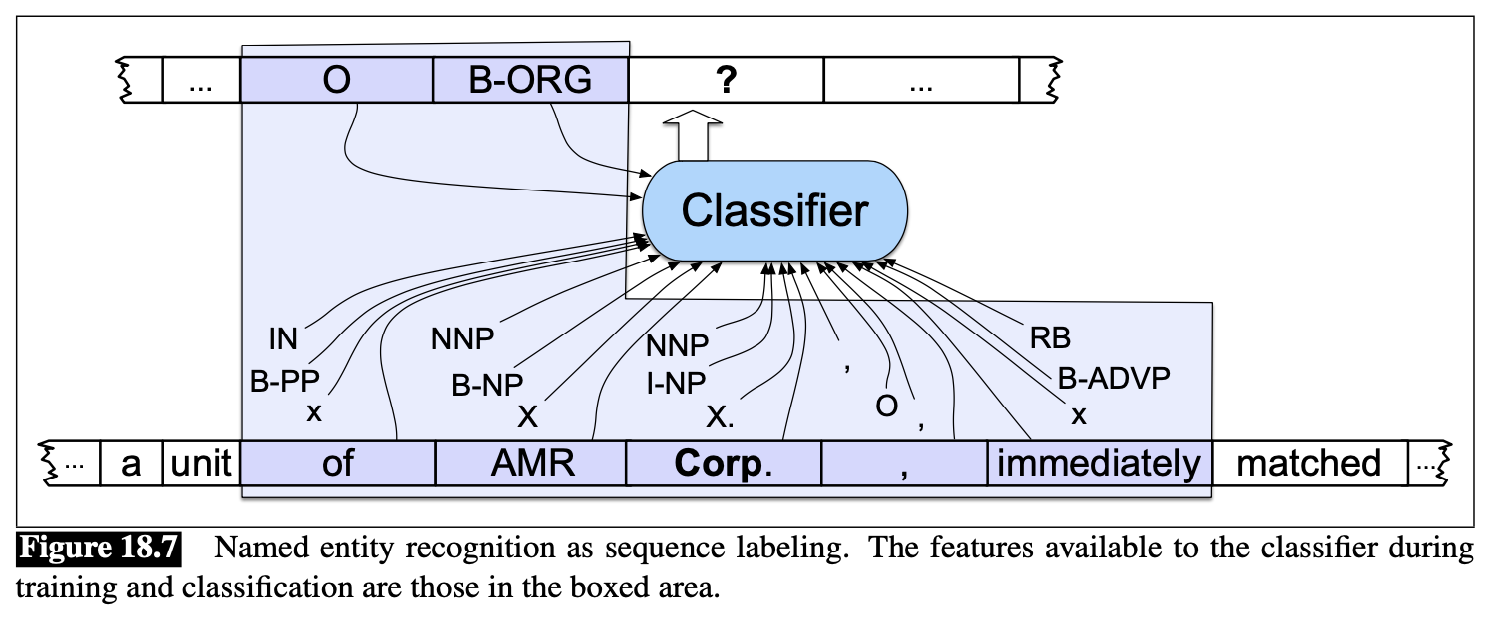
The following figure illustrates the operation of such a sequence labeler at the point where the token Corp. is next to be labeled. If we assume a context window that includes the two preceding and following words, then the features available to the classifier are those shown in the boxed area.
Neural Algorithm for NER
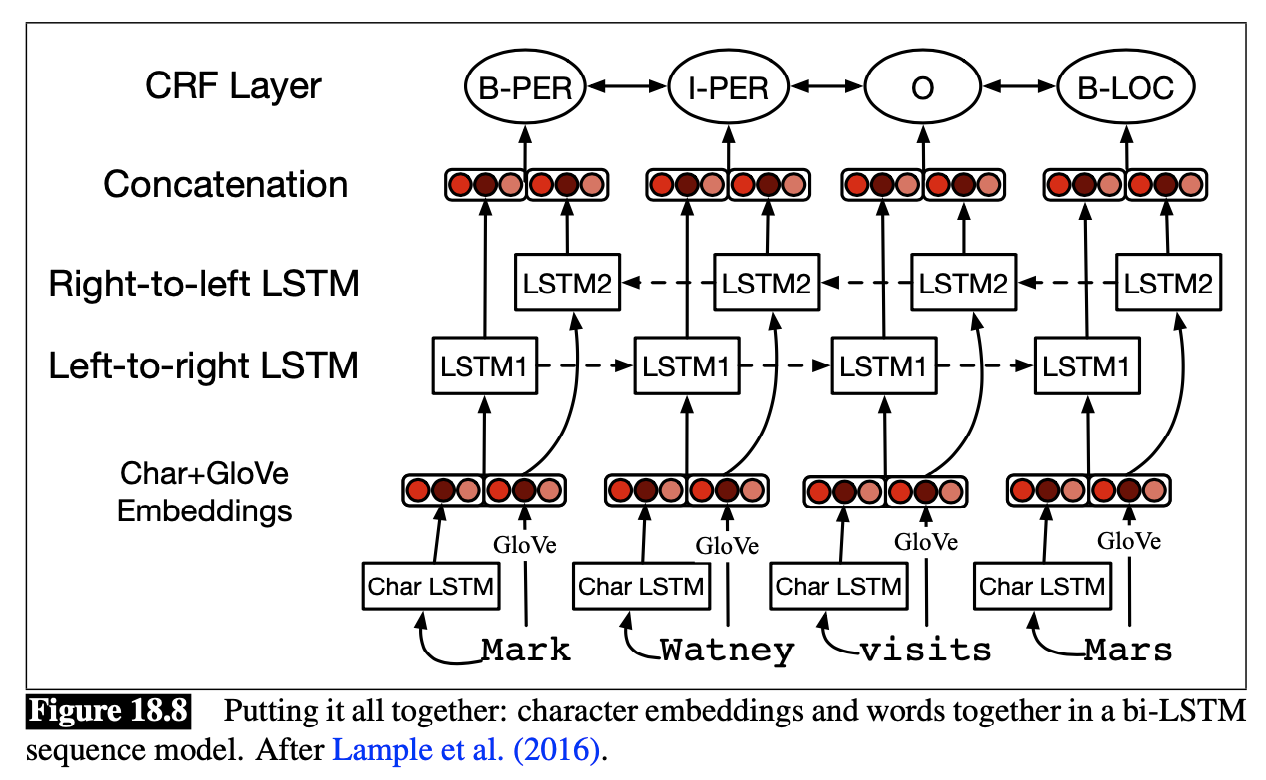
The standard neural algorithm for NER is based on the bi-LSTM:
- Word and character embeddings are computed for input word $w\_i$
- These are passed through a left-to-right LSTM and a right-to-left LSTM, whose outputs are concatenated (or otherwise combined) to produce a sin- gle output layer at position $i$.
- A CRF layer is normally used on top of the bi-LSTM output, and the Viterbi decoding algorithm is used to decode
The following figure shows a sketch of the algorithm:
Rule-based NER
Commercial approaches to NER are often based on pragmatic combinations of lists and rules, with some smaller amount of supervised machine learning.
One common approach is to make repeated rule-based passes over a text, allowing the results of one pass to influence the next. The stages typically first involve the use of rules that have extremely high precision but low recall. Subsequent stages employ more error-prone statistical methods that take the output of the first pass into account.
- First, use high-precision rules to tag unambiguous entity mentions.
- Then, search for substring matches of the previously detected names.
- Consult application-specific name lists to identify likely name entity mentions from the given domain.
- Finally, apply probabilistic sequence labeling techniques that make use of the tags from previous stages as additional features.
The intuition behind this staged approach is two fold.
- First, some of the entity mentions in a text will be more clearly indicative of a given entity’s class than others.
- Second, once an unambiguous entity mention is introduced into a text, it is likely that subsequent shortened versions will refer to the same entity (and thus the same type of entity).
Evaluation of NER
The familiar metrics of recall, precision, and $F\_1$ measure are used to evaluate NER systems.
- Recall: the ratio of the number of correctly labeled responses to the total that should have been labeled
- Precision: ratio of the number of correctly labeled responses to the total labeled
- F-measure: the harmonic mean of the two.
For named entities, the entity rather than the word is the unit of response.
Example:
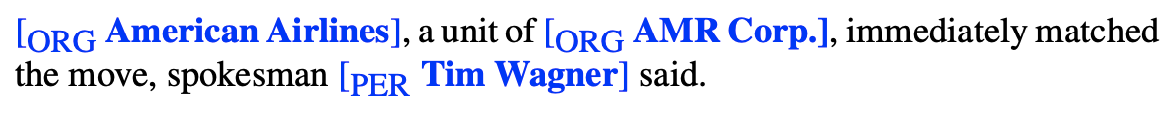
The two entities
Tim WagnerandAMR Corp.and the non-entitysaidwould each count as a single response.
Problem of Evaluation
- For example, a system that labeled
Americanbut notAmerican Airlinesas an organization would cause two errors, a false positive for O and a false negative for I-ORG - Using entities as the unit of response but words as the unit of training means that there is a mismatch between the training and test conditions.