Introduction
What is NLP?
Wikipedia: Natural language processing (NLP) is a field of computer science, artificial intelligence, and linguistics concerned with the interactions between computers and human (natural) languages. As such, NLP is related to the area of human–computer interaction.
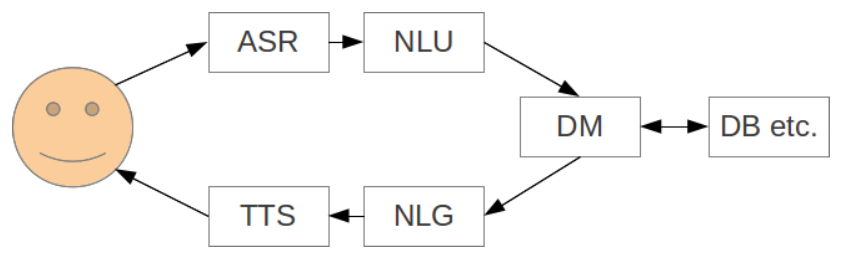
What is Dialog Modeling
Designing/building a spoken dialog system with its goals, user handling etc.
Synonymous to dialog management (DM)
Examples
Goal-oriented dialog
Social dialog / Chat bot
How to do NLP?
- Aim: Understand linguistic structure of communication
- Idea: There are rules to decide if a sentence is correct or not
- A proper sentence needs to have:
- 1 Subject
- 1 Verb
- several objects (depending on the verb’s valence)
- A proper sentence needs to have:
TL;DR
- Task:
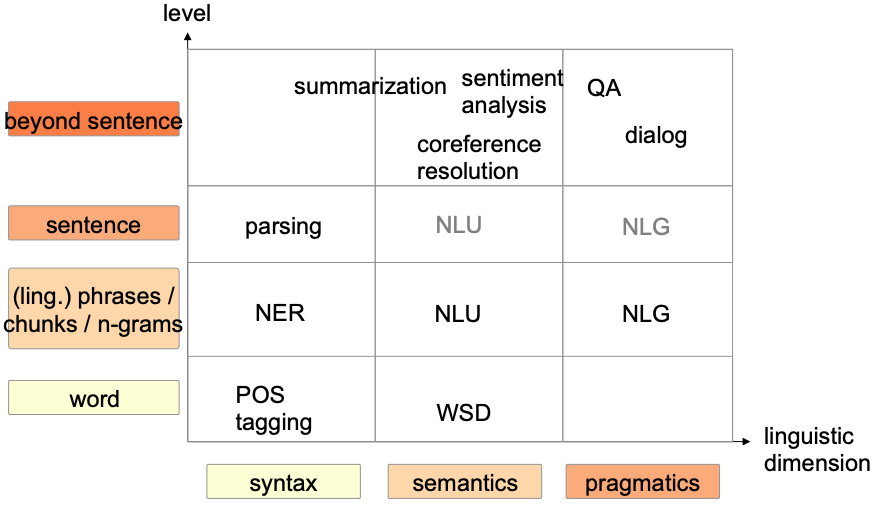
- Linguistic dimension: Syntax, semantics, pragmatics
- Level: Word, word groups, sentence, beyond sentences
- Approaches
- Technique:
- Rule-based,
- Statistical,
- Neural
- Learning scenario:
- Supervised,
- semi-supervised,
- unsupervised,
- reinforcement learning
- Model:
- Classification,
- sequence classification,
- sequence labeling,
- sequence to sequence,
- structure prediction
- Technique:
Technique
Hand-written rules to parse the sentences (Rule-based)
‼️Problems
- There is no fixed set of rules
- Language changes over time
- A(ny?) language is constantly influenced by other languages
- Classification of words into POS tags not always clear
Corpus-based Approaches to NLP (Statistical)
- Corpus = large collection of annotated texts (or speech files)
- 👍 advantages:
- Automatically learn rules from data
- Statistical Models → no hard decision
- Use machine learning approaches
- Possible since larger computation resources
- Corpus will concentrate on most common approaches
- Input:
- Data (Text corpora)
- Machine learning algorithm
- Output: Statistical model

- Problems of simple statistical models: feature engineering
- What features are important to determine the POS tag
- Word ending
- Surrounding words
- Capitalization
- What features are important to determine the POS tag
Deep learning Approaches to NLP (Neural)
- Use neural networks to automatically infer features
- Better generalization
- Successfully applied to many NLP tasks

Learning scenarios
- Supervised learning
- Unsupervised learning
- Semi supervised learning
- Reinforcement learning
Model types
| Model type | Input | Output | Example task |
|---|---|---|---|
| Classification | Fix input size (E.g. word and surrounding k words) | Label | Word sense disambiguation |
| Sequence classification | Sequence with variable length | Label | Sentiment analysis |
| Sequence labelling | Sequence with variable length | Label sequence with same length | Named entity recognition |
| Sequence to Sequence model | Sequence with variable length | Sequence variable length | Summarization |
| Structure prediction | Sequence with variable length | Complex structure | Parsing |
Resources
- Texts
- Brown Corpus
- Penn Treebank
- Europarl
- Google books corpus
- Dictionaries/Ontologies
- WordNet,
- GermaNet,
- EuroWordNet
Approaches to Dialog Modeling
- Many problems of NLP also apply to Dialog Modeling
- Use conversational corpora for learning interaction patterns
- Meeting Corpus (multiparty conversation)
- Switchboard Corpus (telephone speech)
- Problems ‼️
- Very domain dependent
- Need human interaction in training
Why is NLP hard?
Ambiguities! Ambiguities! Ambiguities!
Ambiguities
Examples:

Rare events
Calculate probabilities for events/words
Most words occur only very rarely
- Most words occur one time
- What to do with words that occur not in training data? 🧐
Zipf’s Law
$$ f \propto \frac{1}{r} $$- order list of words by occurrence
- rank: position in the list
The frequency of any word is inversely proportional to its rank in the frequency table.
Thus the most frequent word will occur approximately twice as often as the second most frequent word, three times as often as the third most frequent word
For example, in the Brown Corpus of American English text, the word the is the most frequently occurring word, and by itself accounts for nearly 7% of all word occurrences (69,971 out of slightly over 1 million). True to Zipf’s Law, the second-place word of accounts for slightly over 3.5% of words (36,411 occurrences), followed by and (28,852).