Sentiment Analysis
Introduction
Definition
Sentiment analysis / opinion mining
- Determine opinion, sentiment and subjectivity in text
- What is the authors opinion about something?
- What are the pros and cons?
- Important task in natural language processing
Application
- Automatically maintain review and opinion-aggregation websites
- Web search target towards reviews
- generate results with variety of opinions
- Improve customer relationship management
- Automatically analyze customer feedback
- Predict public attitudes towards brand/politics
- Ad placement
- Advertise products near positive text
- Summarization
- Question-answering
Challenges
- Deep undetstanding
- Co-reference resolution
- Negation handling
- Different hints in the text
Tasks of SA
- Polarity classification
- binary classifier if text, sentence, document is positive or negative
- Agreement detection
- Do two text agree on their opinion?
- Rating
- How does the user rate a product (1 to 5 stars)
- Subjectivity detection
- Is a text or sentence subjective or objective?
- Feature/aspect-based sentiment analysis
- Opinions express on different features/aspects
- Viewpoints and perspectives
Polar classification
Task:
- Input: Text (Sentence, Document, Several Documents) (variable length)
- Output: positive or negative opinion
- Sequence classification
Techniques:
Keyword spotting
- Classify based on occurrence of unambiguous affect words
- E.g.: happy, sad, afraid, bored
- ‼️ Problems
- affect-negated words
- E.g.: “today was a happy day” vs “today wasn’t a happy day at all”
- surface features
- Often no obvious affect words are present
Lexical affinity
Increase the number of considered words
Assign “probable” affinity to particular emotions
Example: Accident (75% of indicating a negative affect (car accident))
Train probabilities from linguistic corpora
‼️ Problems
negated sentences (“I avoided an accident”)
Words with different meaning (“I met my girlfriend by accident”)
Bias towards training data –> domain-dependent
Statistical methods
💡 Use machine-learning algorithm to train classifier
- Input:
- Represent input text as features vector
- Feature selection important for classification performance
- Represent input text as features vector
- Classifier:
- Naive Bayes
- Support Vector Machines
- Maximum-entropy-based classification
Features
- Word representation
- Position information
- POS infromation
- Syntax: Tree-based features
Feeatures Negation
Negation should invert the features of the sentence
Approaches:
- Attach NOT to all words near a negation
However
- Not all negation reverse meaning
- “No wonder this is considered one of the best “
- Negation do often not use a key word
- “it avoids all clichés and predictability found in Hollywood movies”
Topic-oriented features
- Opinion of a sentence depend on topic of the article
- Approach: Replace subject of the article by general term
Domain adaptation
- Meaning depends on the domain
- Different approaches to transfer knowledge from one domain to another
- Search domain-independent features
- Structural correspondence learning algorithm
Unsupervised approaches
Unsupervised lexicon induction
Find adjectives using linguistic heuristics
- words that co-occur with “but”
- elegant but over-priced
- words that co-occur with “and”
- clever and informative
- words that co-occur with “but”
Build graph
Cluster or build binary-partition
Assign polarity using some seed words
Relation identification
Sentence relationship
Objective and subjective sentence in a review
No random order
- After subjective sentence most probable also subjective sentence
First cluster sentence into objective and subjective
- Use labels of the surrounding sentences
Then Use only subjective sentence to classify polarity of review
Order of sentence is important
End is more important than beginning
Use trajectory of local sentiments
Dialog structure
Class structure
One-vs.-all multi-class categorization
Model as Metric labeling problem
‼️ Problems of statistical methods
- Need enough text to perform classification
- Good performance on page and paragraph level
- Problems on sentence or clause level
Concept-based approaches
- Perform semantic text analysis
- Resources:
- Web ontologies
- Semantic networks
- try to recognize meaning/features
- heavily rely on depth and breadth of knowledge base
- Resources:
Opinion summarization
Opinion-oriented extraction
Example: “What is the best about the new iPhone?”
Approach
Extract product features
- nouns / frequent nouns
- heuristic pruning
extract opinions associated with these features
- sometimes also extract the opinion holder
What is opinion summarization?
Generate summary of large number of opinions
Aggregate results of sentiment prediction
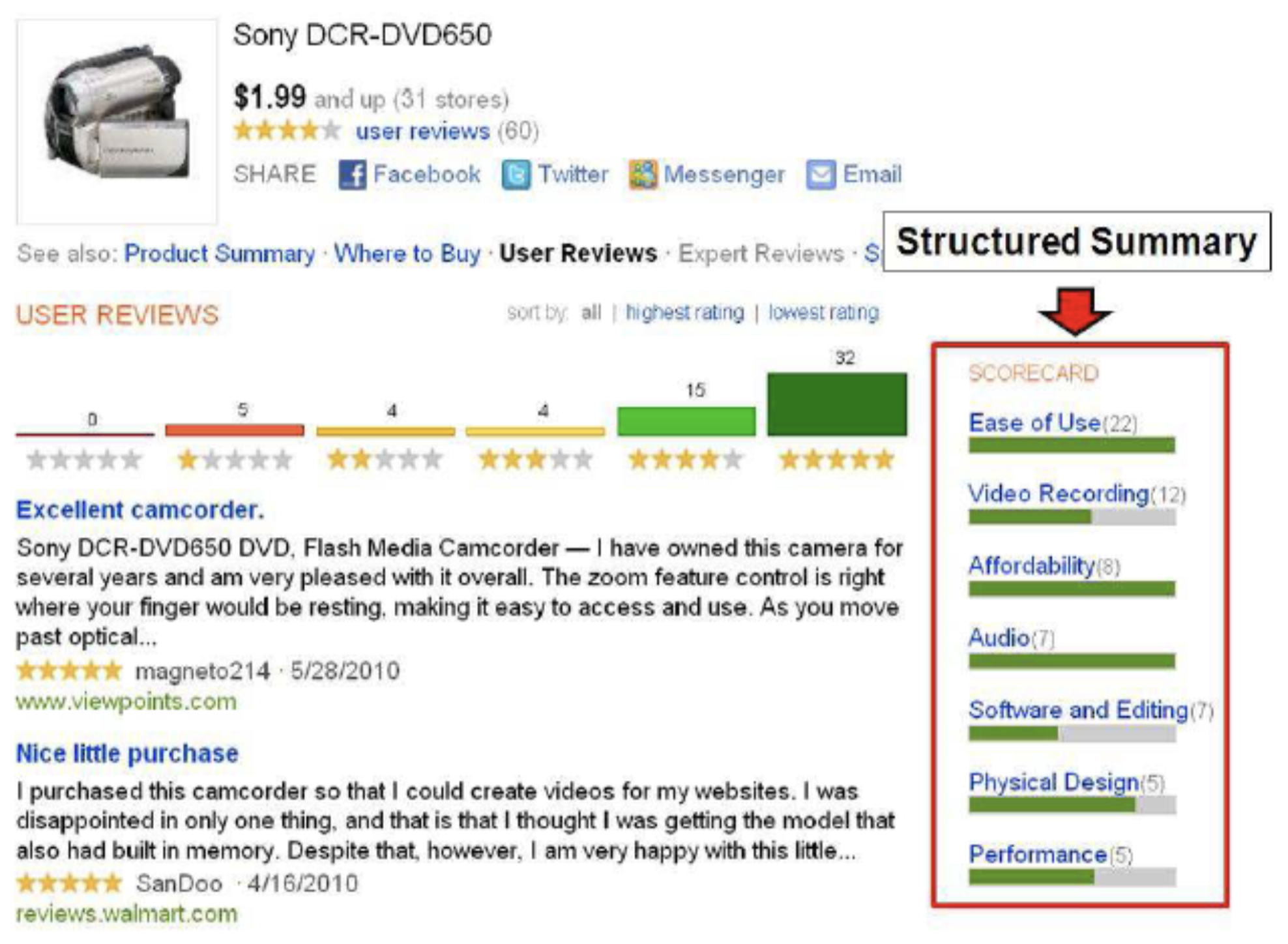
Structured summaries:
- breakdown by aspects/topics
- text or visualization
Conceptual Framework
Aspect-based
💡 Divide input text into aspect/features/subtopics
E.g.: Review on iPod
battery life
design
price
Show structured details
How aspect-based opinion summarization works?
Framework
- find important topics
- determine the sentiment orientation
- is the aspect judged positive/negative?
- present results
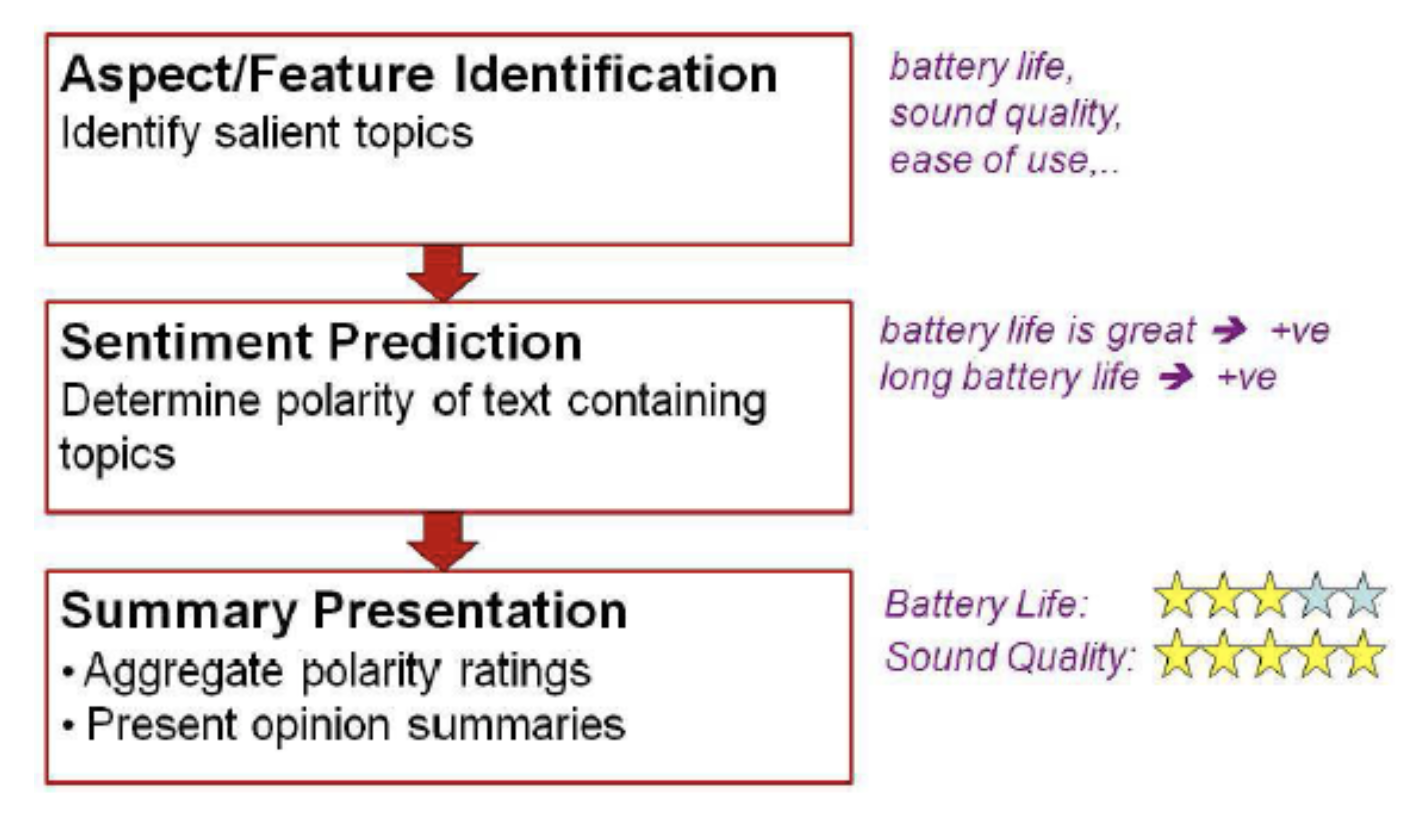
Aspect/Feature Identification
- Find subtopics (In some cases already known)
- Techniques
- NLP-based approaches using POS-tagging /parse trees
- Shallow parsing
- use additional knowledge
Sentiment prediction
Predict sentiment for the different aspects
Learning approach:
- Learn aspect level ratings using the global rating
- Naive Bayes classifier
- ‼️ Problem: label examples is expensive
Most approaches use lexicon/rule-based methods
- e.g. list of positive and negative words (extend by wordNet)
Summary Generation
Generate and present the opinion summaries
Statistical Summary
- show statistics about opinion on different aspect
- directly use sentiment prediction output
- easy to understand
Text selection
- show small pieces of text as the summary
- show strongest opinion words for every aspect
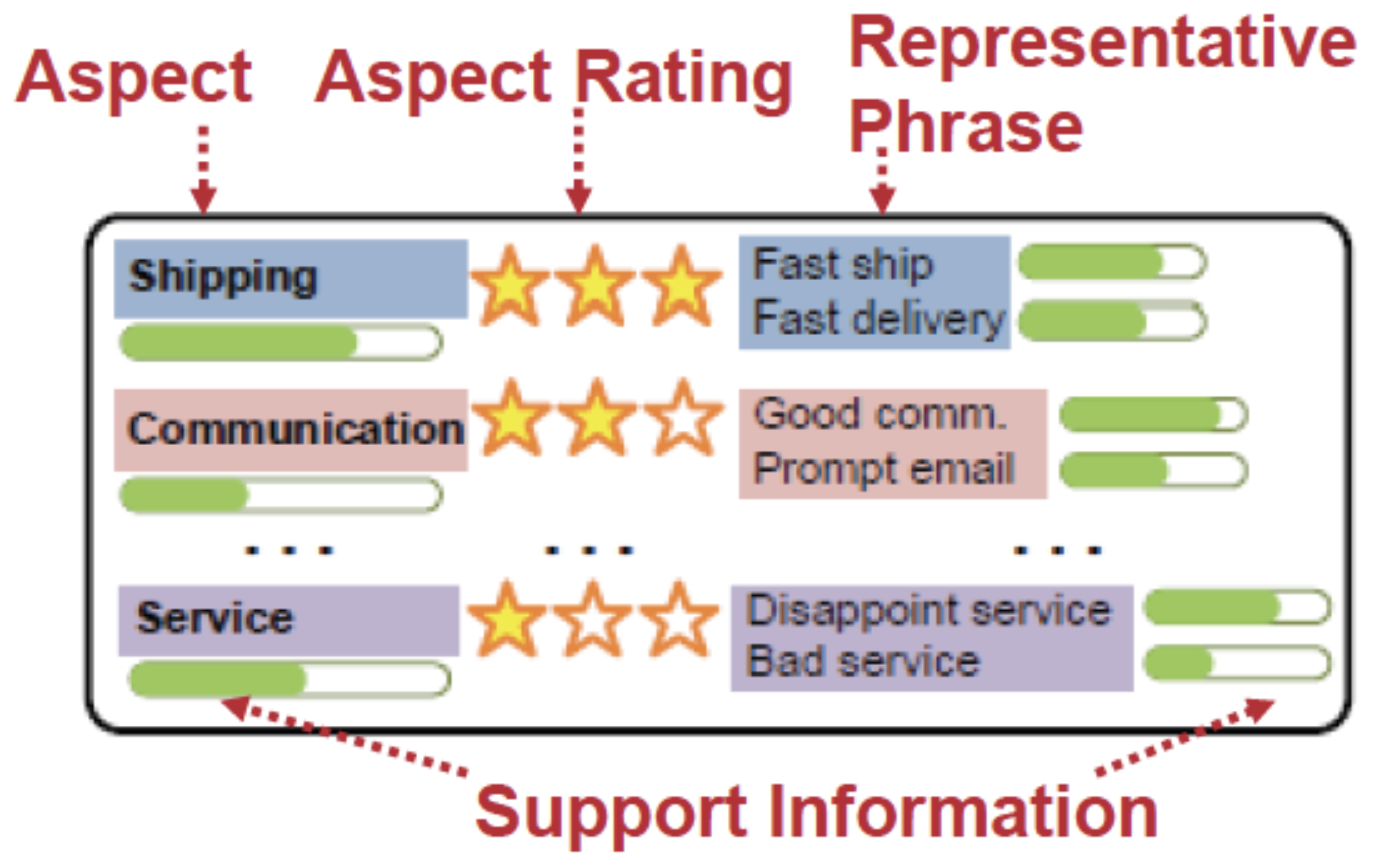
Aggregate Ratings
- Show statistics and text selection
Summary with timeline
Show opinion trends over a timeline
Example:
Integrated Approaches
No clear separation of the different steps
Topic Sentiment Mixture Model
- unsupervised approach
- sentiment prediction and aspect identification in one step
- Model: Probabilistic latent semantic analysis (PLSA)
Multi-task learning
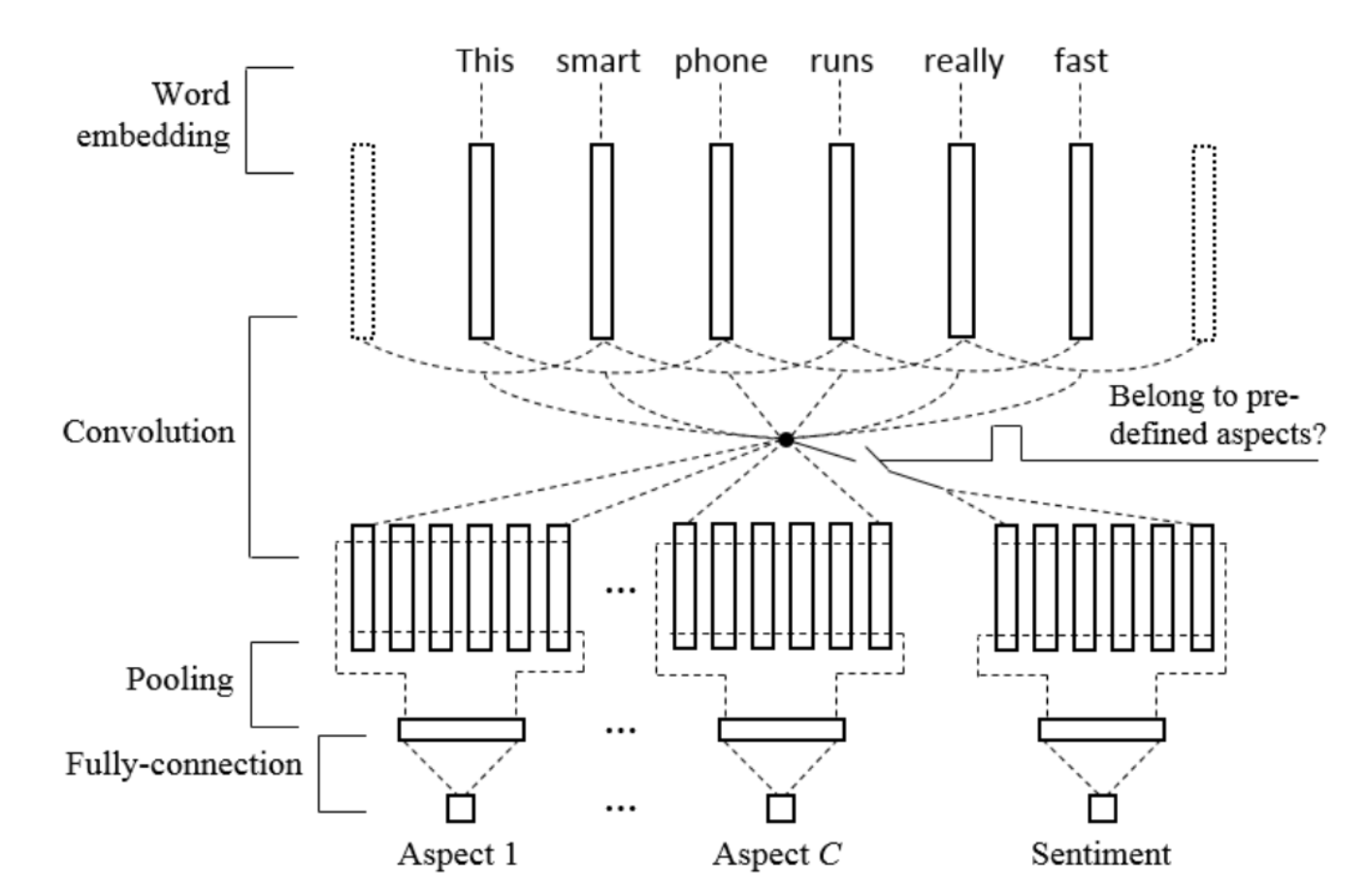
CNN-based approach
C predefined aspect mappers
Sentiment classfiers
shared word embedding layer
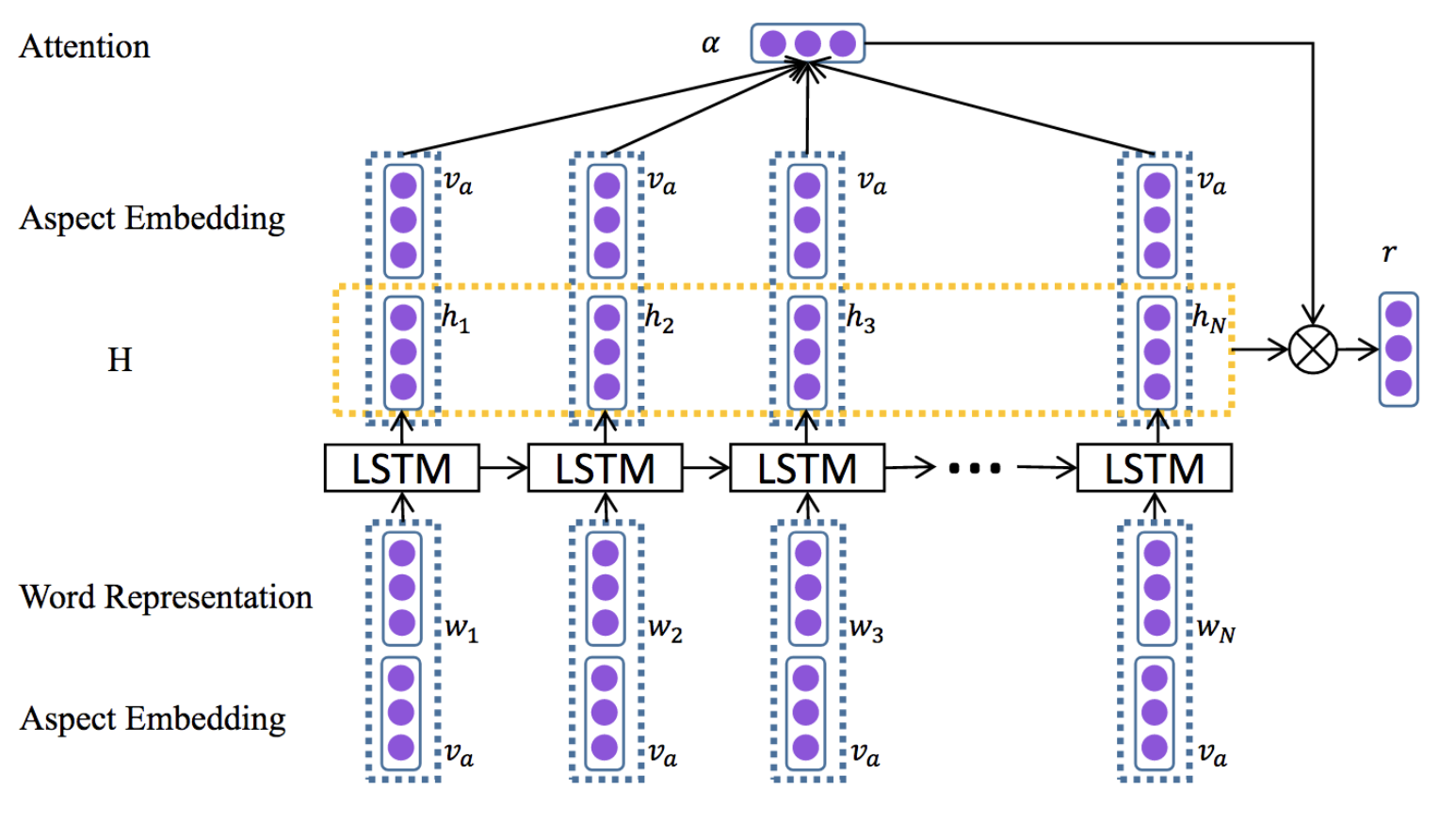
LSTM with attention
- Input: word embedding and aspect embedding
- Relevant parts of the sentence identified through attention mechanism
Non-aspect-based opinion summarization
Basic Sentiment Summarization
- Classify each input text separately
- Count number of positive and negative opinions
Text Summarization
Opinion Integration:
- Expert opinions: complete, but rarely updated
- Ordinary opinions: unstructured, but updated more often
- Combine both by first extracting information from expert opinions
- Add information from the ordinary opinions
Contrastive Opinion Summarization
- Show positive and negative aspects
Abstractive Text summarization