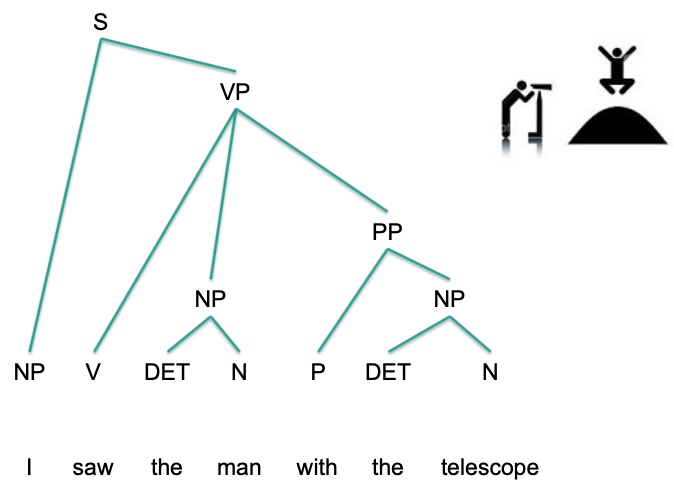
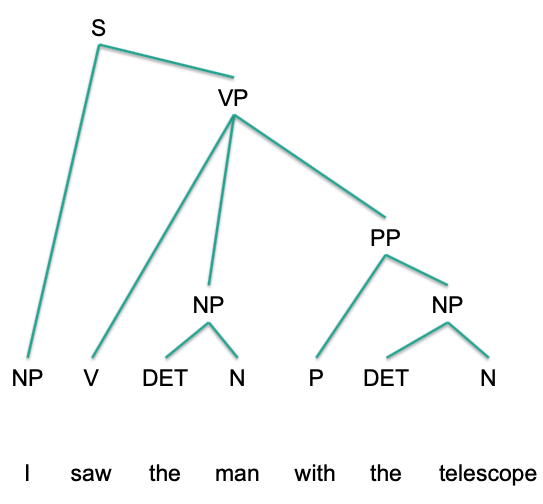
In syntactic analysis, a constituent is a word or a group of words that function as a single unit within a hierarchical structure. The constituent structure of sentences is identified using tests for constituents.
A phrase is a sequence of one or more words (in some theories two or more) built around a head lexical item and working as a unit within a sentence. A word sequence is shown to be a phrase/constituent if it exhibits one or more of the behaviors discussed below.
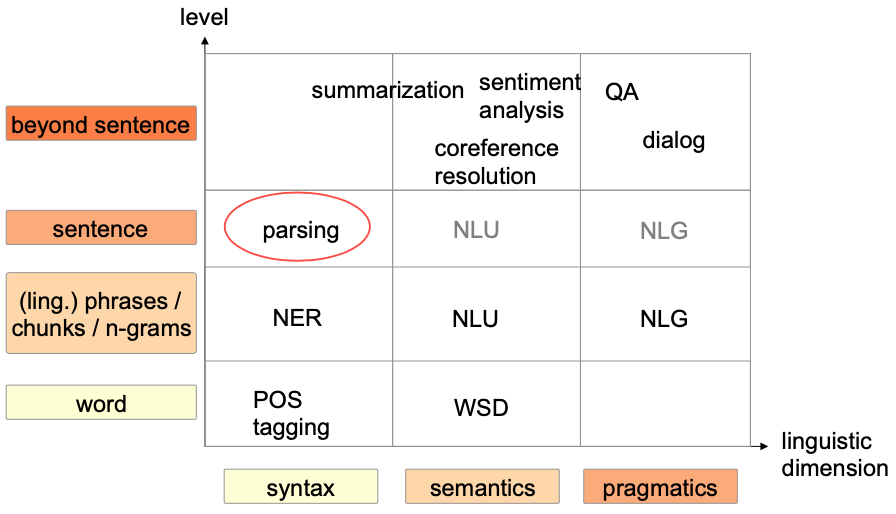
Phrase structure rules
Describe syntax of language
Example
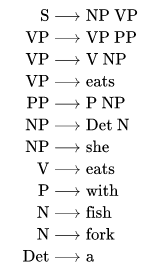
s –>NPVP (Sentence consists of a noun phrase and a verb phrase)
NP –> DetN (A noun phrase consists of a determiner and a noun)
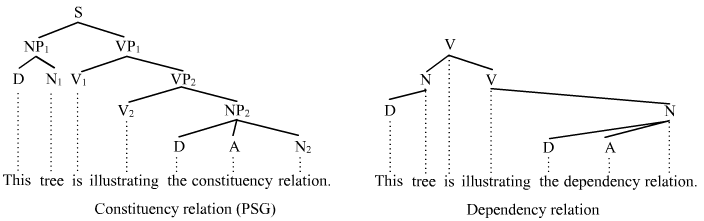
In linguistics, phrase structure grammars are all those grammars that are based on the constituency relation, as opposed to the dependency relation associated with dependency grammars; hence, phrase structure grammars are also known as constituency grammars
The fundamental trait that these frameworks all share is that they view sentence structure in terms of the constituency relation.
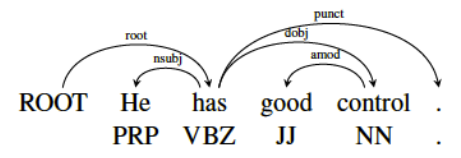
Example: Constituency relation Vs. Dependency relation
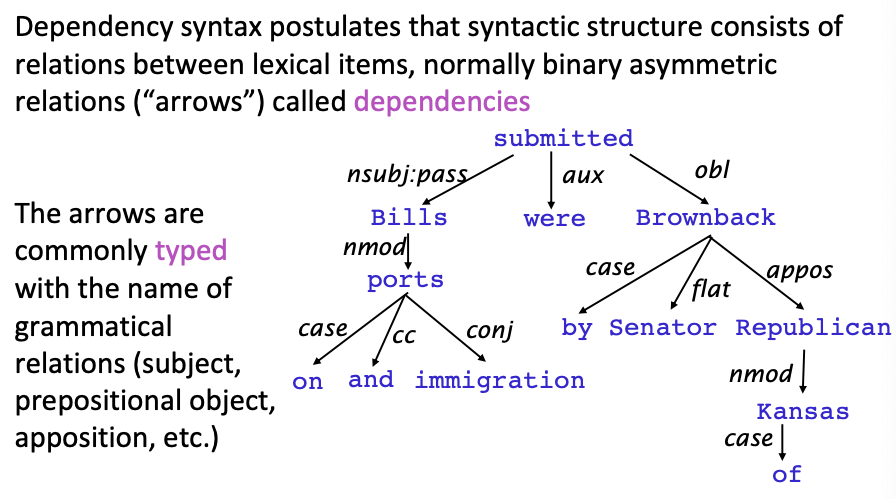
The (finite) verb is taken to be the structural center of clause structure. All other syntactic units (words) are either directly or indirectly connected to the verb in terms of the directed links, which are called dependencies.
A dependency structure is determined by the relation between a word (a head) and its dependents. Dependency structures are flatter than phrase structures in part because they lack a finite verb phrase constituent, and they are thus well suited for the analysis of languages with free word order, such as Czech or Warlpiri.
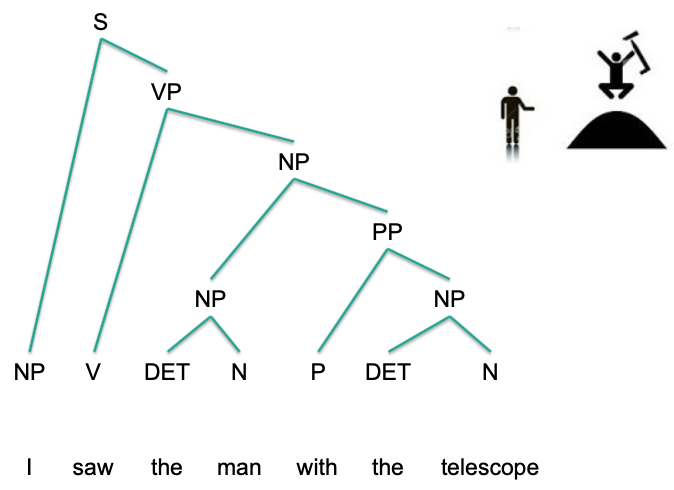
Difficulties
Ambiguities!!!
E.g.: Prepositional phrase attachment ambiguity
Parsing
Automatically generate parse tree for sentence
Given:
Grammar
Sentence
Find: hidden structure
Idea: Search for different parses
Applications
Question – Answering
Named Entity extraction
Sentiment analysis
Sentence Compression
Traditional approaches
Hand-defined rules: restrict rules by hand to have at best only one possible parse tree
🔴 Problems
Many parses for the same sentence
Coverage Problem (Many sentences could not be parsed)
Time and cost intensive
Statistical parsing
Use machine learning techniques to distinguish probable and less probable trees
Automatically learn rules from training data
Hand-annotated text with parse trees
still many parse trees for one sentence 🤪
But weights define most probable
Tasks
Training: learn possible rules and their probabilities
Search: find most probable parse tree for sentence
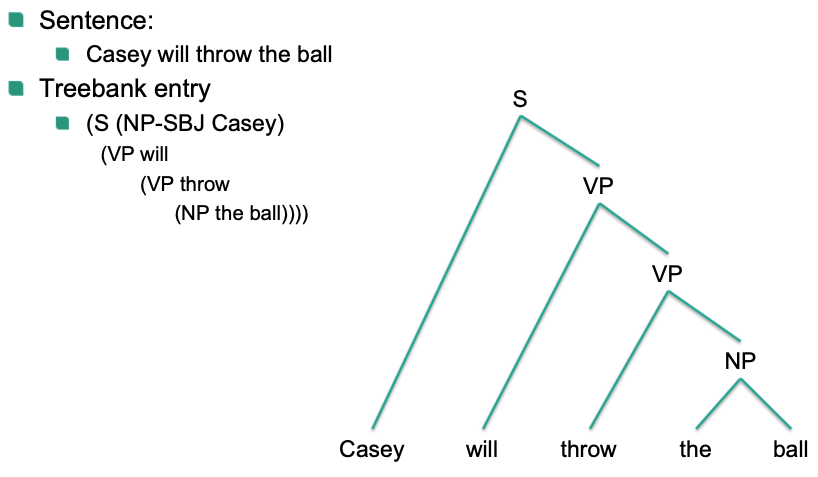
Annotated Data
Treebank:
human annotated sentence with structure
Words
POS Tags
Phrase structure
👍 Advantages:
Reusable
High coverage
Evaluation
Example
Probabilistic Context Free Grammar
Extension to Context Free Grammar
Formel definition: 5 tuple
$$
G = (V, \Sigma, R, S, P)
$$
$V, \Sigma, R, S$: same as Context Free Grammar
$P$: set of Probabilities on production rules
E.g.: s –>NPVP 0.5
Properties
Probability of derivation is product over all rules
$$
P(D)=\prod_{r \in D} P(r)
$$
Sum over all probabilities of rules replacing one non-terminal is one
$$
\sum_{A} P(S \rightarrow A)=1
$$
Sum over all derivations is one
$$
\sum_{D \in S} P(D)=1
$$
Training
Input: Annotated training data (E.g.: Treebank)
Training
Rule extraction: Extract possible rules from the trees of the training data
Probability estimation
Assign probabilities of the rules
Maximum-likelihood estimation
Example:
Search
Find possible parses of the sentence
Statistical approach: Find all/many possible parse trees
Return most probable one
Strategies:
Top-Down
Bottom up
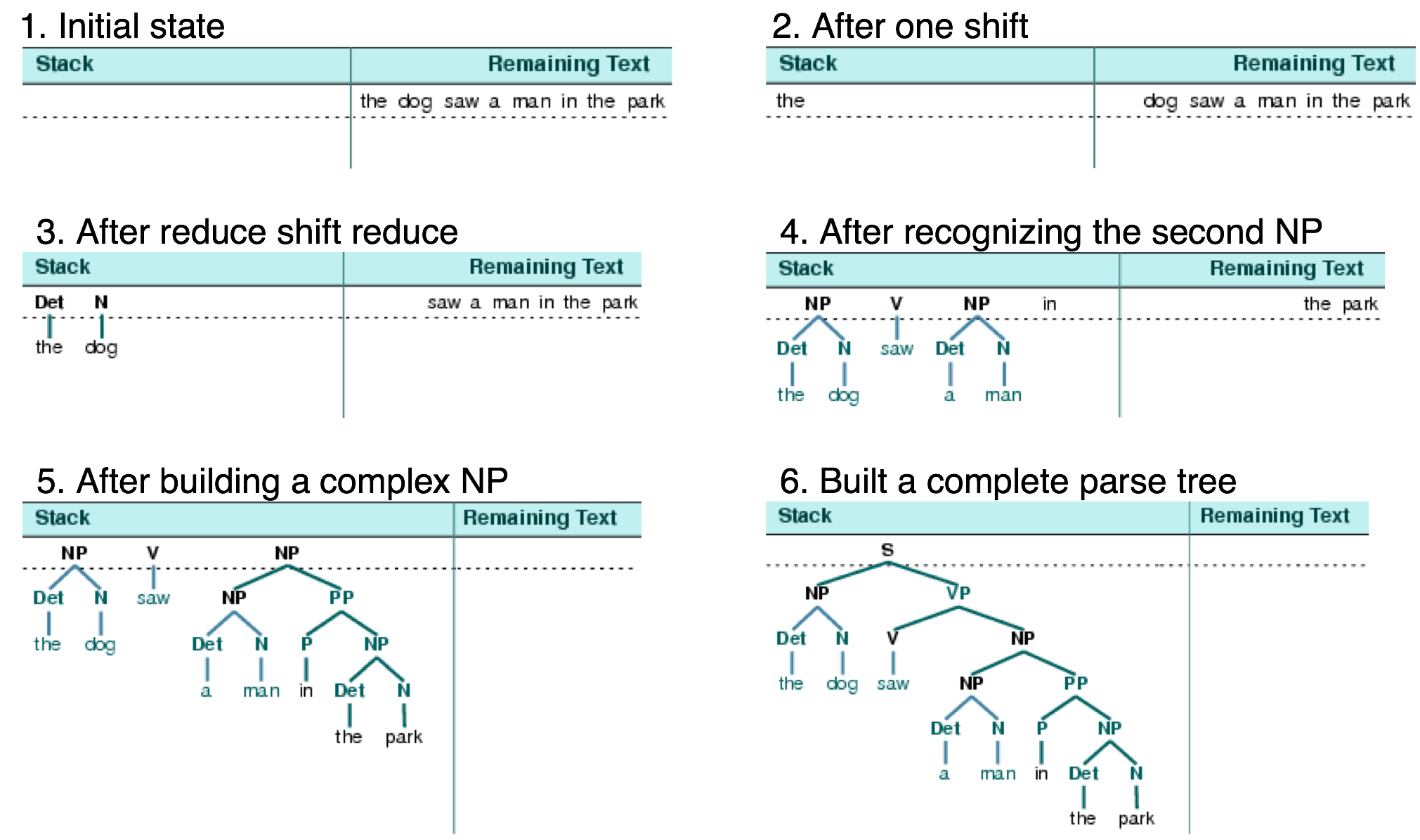
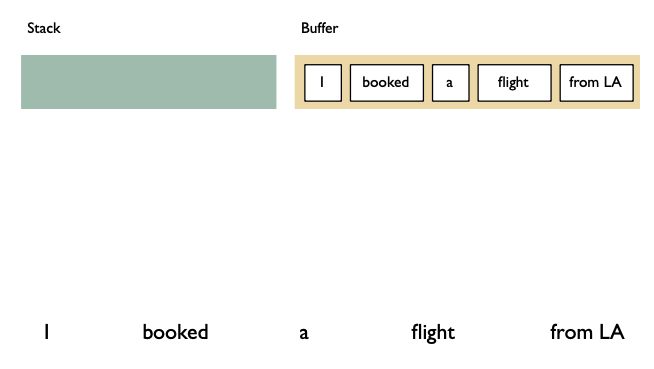
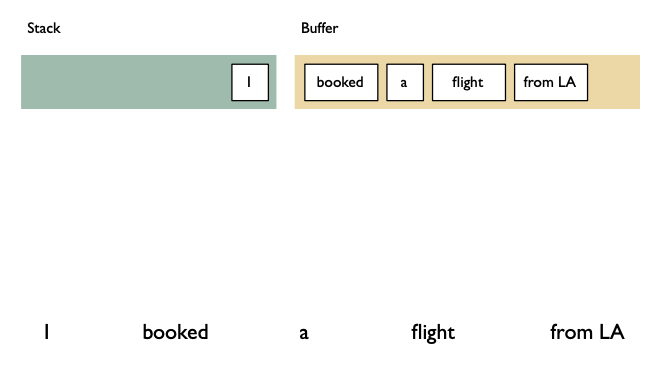
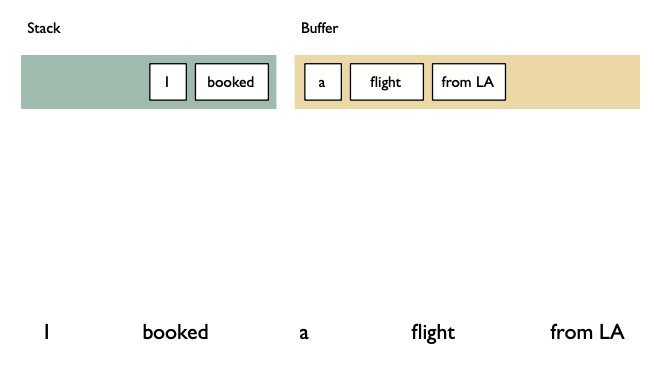
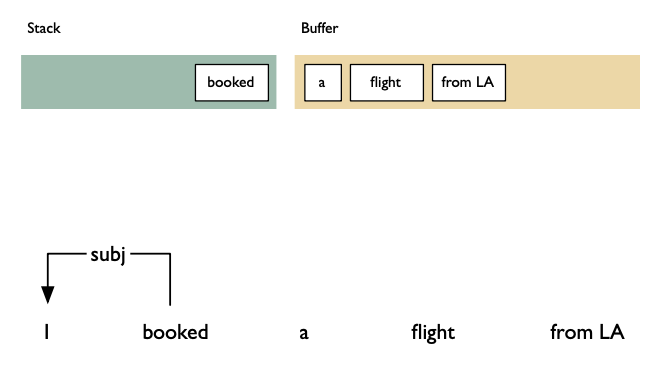
Shift reduce algorithm
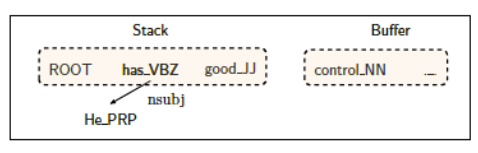
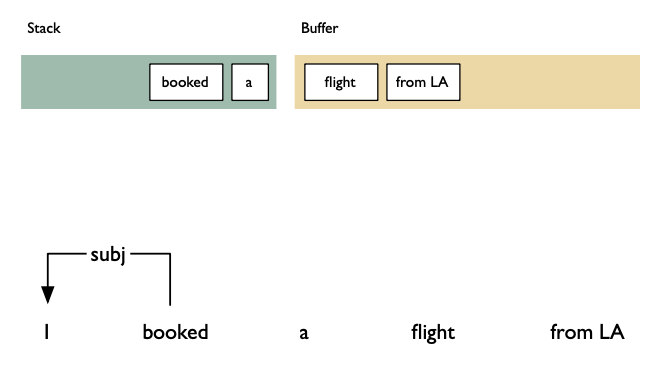
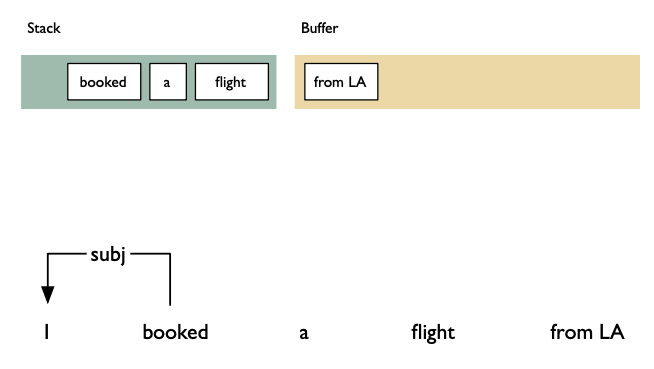
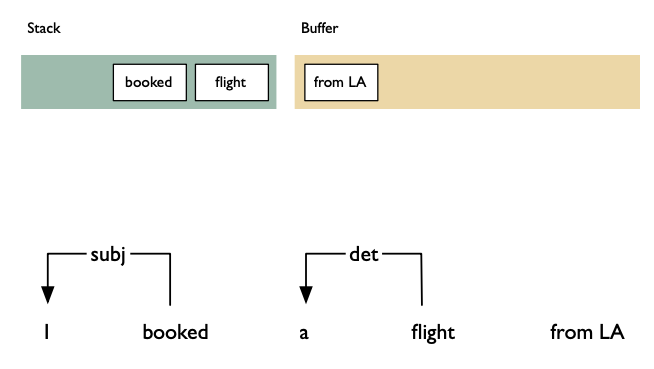
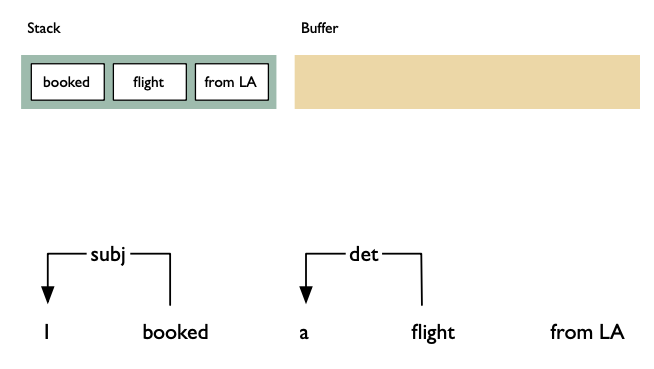
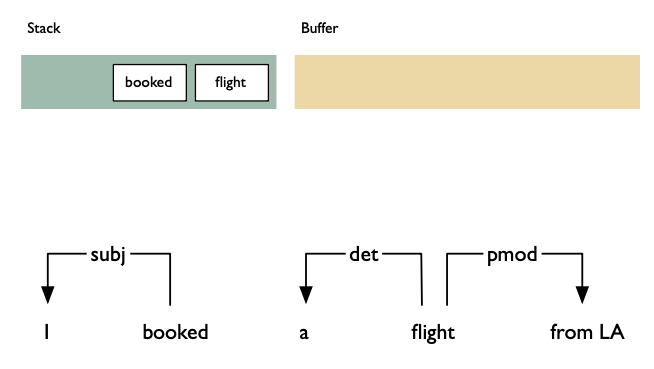
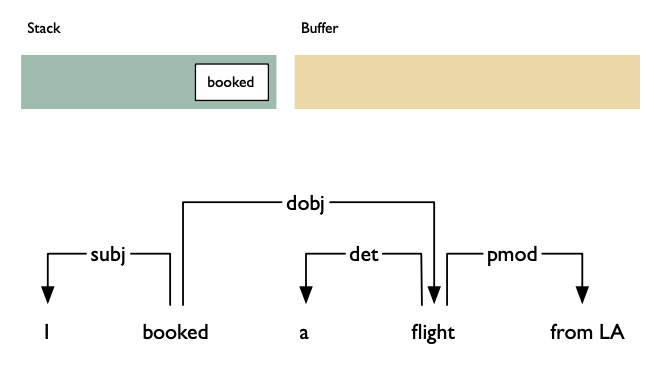
Shift: advances in the input stream by one symbol. That shifted symbol becomes a new single-node parse tree.
Reduce: applies a completed grammar rule to some of the recent parse trees, joining them together as one tree with a new root symbol.
Example
Shift reducea algorithm example
Dynamic Programming
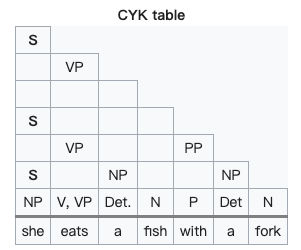
CYK Parsing
Avoid repeat work
Use Dynamic Programming
Transform grammar in Chomsky normal form
Store best trees for subphrases
Combine tree from best trees of subphrases
All rules must have the following form
A –> BC
A, B, C non-terminals
B, C not the start symbol
A –> a
A non-terminal
a terminal
S –> $\epsilon$
Create empty string if it is in the grammar
Every context-free grammar can be transferred into one having Chomsky normal form
Binarization
Only rules with two non-terminals
Idea:
Introduce additional non-terminal
Replace one rules with three non-terminals by two rules with two non- terminals each