Summarization
TL;DR
Most important technique
Tasks:
Algorithms:
Abstract summarization still an open problem
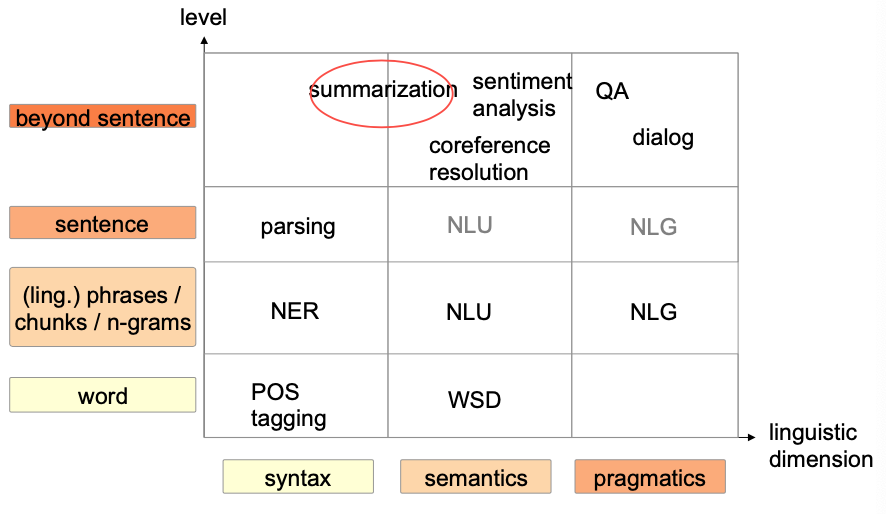
Introduction
What is Summarization?
- Reduce natural language text document
- Goal: Compress text by extracting the most important/relevant parts 💪
Applications
Articles, news: Outlines or abstracts
Email / Email threads
Health information
Meeting summarization
Dimensions
Single vs. multiple
- Single-document summarization
- Given single document
- Produce abstract, outline, headline, etc.
- Multiple-document summarization
Given a group of documents
A series of news stories on the same event
A set of web pages about some topic or question
- Single-document summarization
Generic vs. Query-focused summarization
- Generic summarization: summarize the content of the document
- Query-focused summarization: kind of complex question answering 🤪
- Summarize a document with respect to an information need expressed in a user query
- Longer, descriptive, more informative answers
- Answer a question by summarizing a document that has information to construct the answer
Techniques
Extraction
- Select subset of existing text segments
- e.g.:
Sentence extraction
Key-phrase extraction
- Simpler, most focus in research
Abstraction
- Use natural language generation to create summary
- More human like
Extractive summarization
Three main components
- Content selection ("Which parts are important to be in the summary?")
- Information ordering ("How to order summaries?")
- Sentence realization (Clean up/Simplify sentences)
Supervised approaches
Key-word extraction
Given: Text (e.g. abstract of an article, …)
Task: Find most important key phrases
Computer Human Select key phrases from the text Abstraction of the text No new wordings New words
Key-phrase extraction using Supervised approaches
Given: Collection of text with key-words
Algorithm
Extract all uni-grams, bi-grams and tri-grams
Example

Extraction: Compatibility, Compatibility of, Compatibility of systems, of, of systems, of systems of, systems, systems of, systems of linear, of linear, of linear constraints, linear, linear constraints, linear constraints over, …
Annotate each examples with features
Annotate training examples with class:
- 1 if sequence is part of the key words
- 0 if sequence is not part of the key words
Train classifier
Create test examples and classify
Examples set
- All uni-, bi-, and trigrams (except punctuation)
- restrict to certain POS sets
🔴 Problem:
Enough examples to generate all/most key phrases
Too many examples -> low performance of classifier
Features
Term frequency
TF-IDF (Term Frequency–Inverse Document Frequency)
Reflect importance of a word in a document
$$ \text{TF-IDF} = tf * idf $$$tf(w, D)$:
- Term Frequency, measures how frequently a term occurs in a document.
- Number of occurrences of word $w$ in document $d$ divided by the maximum frequency of one word in $D$
Alternative definition:
$$ > tf(w, D) = \frac{\text{count of } w \text{ in } D}{\text{number of words in } D} > $$$idf(w)$:
- Inverse Document Frequency, measures how important a term is
- Idea: Words which occur in less documents are more important
- Number of documents divided by the number of documents which contain $w$
- Consider a document containing 100 words wherein the word cat appears 3 times. The term frequency (i.e., tf) for cat is then (3 / 100) = 0.03. Now, assume we have 10 million documents and the word cat appears in one thousand of these. Then, the inverse document frequency (i.e., idf) is calculated as log(10,000,000 / 1,000) = 4. Thus, the Tf-idf weight is the product of these quantities: 0.03 * 4 = 0.12.
Length of the example
Relative position of the first occurrence
Boolean syntactic features
- contains all caps
Learning algorithm
Decision trees,
Naive Bayes classifier
…
Evaluation
Compare results to reference
Test set: Text
Human generated Key words
Metrics:
Precision
Recall
F-Score
🔴 Problems
- Humans do not only extract key words, but also abstract
- Normally not all key words are reachable
Sentence extraction
Use statistic heuristics to select sentences
Do not change content and meaning
💡 Idea
- Use measure to determine importance of sentence
- TF-IDF
- Supervised trained combination of several features
- Rank sentence according to metric
- Output sentences with highest scores:
- Fixed number
- All sentence above threshold
- Use measure to determine importance of sentence
Limitations: Do NOT change text (e.g. add phrases, delete parts of the text)
Evaluation
Idea: Compare automatic summary to abstract of text
- Problem: Different sentences –> Nearly no exact match 😭
ROUGE - Recall-Oriented Understudy for Gisting Evaluation
Use also approximate matches
Compare automatic summary to human generated text
Given a document D and an automatic summary X
M humans produce a set of reference summaries of D
What percentage of the n-grams from the reference summaries appear in X?
ROUGE-N: Overlap of N-grams between the system and reference summaries
$$ \text{ROUGH-N} = \frac{\sum\_{S \in \\{\text{Reference Summaries}\\}} \sum\_{gram\_n \in S}\operatorname{Count}\_{match}(gram\_n)}{\sum\_{S \in \\{\text{Reference Summaries}\\}} \sum\_{gram\_n \in S}\operatorname{Count}(gram\_n)} $$Example:
Auto-generated summary ($Y$)
the cat was found under the bedGold standard (human produced) ($X1$)
the cat was under the bed1-gram and 2-gram summary:
# 1-gram reference 1-gram 2-gram reference 2-gram 1 the the the cat the cat 2 cat cat cat was cat was 3 was was was found was under 4 found under found under under the 5 under the under the the bed 6 the bed the bed 7 bed count 7 6 6 5 - $\operatorname{ROUGE}-1(X1, Y) = \frac{6}{6} = 1$
- $\operatorname{ROUGE}-2(X1, Y) = \frac{4}{5}$
Unsupervised approaches
Problems of supervised approaches: Hard to acquire training data
We try to use unsupervised learning to find key phrases / sentences which are most important. But which sentences are most important?
💡 Idea: Sentences which are most similar to the other sentences in the text
Graph-based approaches
- Map text into a graph
- Nodes:
- Text segments: Words
- Edges: Similarity
- Nodes:
- Find most important/central vertices
- Algorithms: TextRank / LexRank
Graph-based approaches : Key-phrase extraction
Graph
- Nodes
- Text segments: Words
- Restriction:
- Nouns
- Adjective
- Edges
- items co-occur in a window of N words
- Nodes
Calculate most important nodes
Build Multi-word expression in post-processing
- Mark selected items in original text
- If two adjacent words are marked –> Collapse to one multi-words expression
Example
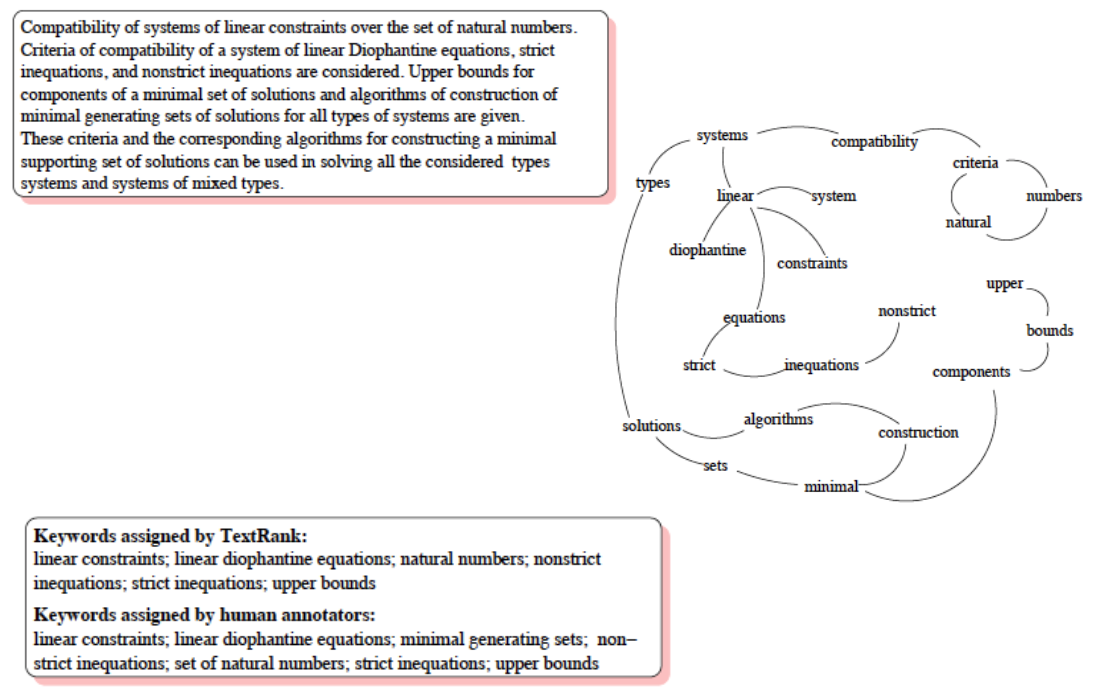
Graph-based approaches : Sentence extraction
Graph:
Nodes: Sentences
Edges: Fully connected with weights
Weights:
TextRank: Word overlap normalized to sentence length
$$ \text {Similarity}\left(S\_{i}, S\_{j}\right)=\frac{\left|\left\\{w\_{k} \mid w\_{k} \in S\_{i} \text{ & } w\_{k} \in S\_{j}\right\\}\right|}{\log \left(\left|S\_{i}\right|\right)+\log \left(\left|S\_{j}\right|\right)} $$LexRank: Cosine Similarity of TF-IDF vectors
$$ \text { idf-modified-cosine }(x, y)=\frac{\sum\_{w \in x, y} \mathrm{tf}\_{w, x} \mathrm{tf}\_{w, y}\left(\mathrm{idf}\_{w}\right)^{2}}{\sqrt{\sum\_{x\_{i} \in x}\left(\mathrm{tf}\_{x\_{i}, x} \mathrm{idf}\_{x\_{i}}\right)^{2}} \times \sqrt{\sum\_{y\_{i} \in y}\left(\mathrm{tf}\_{y\_{i}, y} \mathrm{idf}\_{y\_{i}}\right)^{2}}} $$
Abstract summarization
- Sequence to Sequence task
- Input: Document
- Output: Summary
- Several NLP tasks can be modeled like this (ASR, MT,…)
- Successful deep learning approach: Encoder-Decoder Model
Sequence-to-Sequence Model
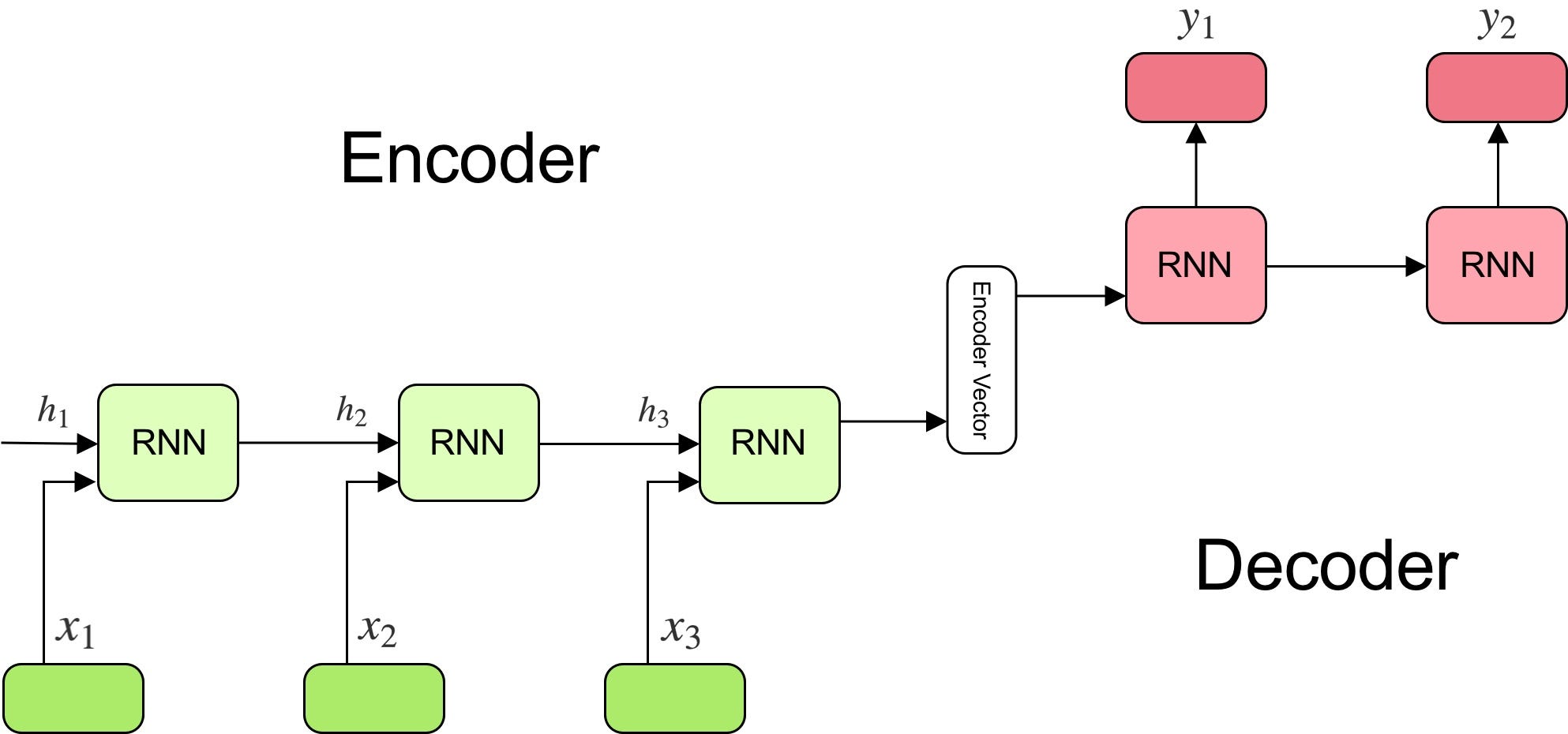
- Predict words based on
- previous target words and
- source sentence
- Encoder: Read in source sentence
- Decoder: Generate target sentence word by word
Encoder
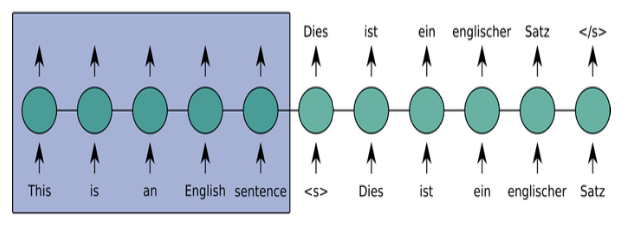
Read in input: Represent content as hidden vector with fixed dimension
LSTM-based model
Fixed-size sentence representation
Details:
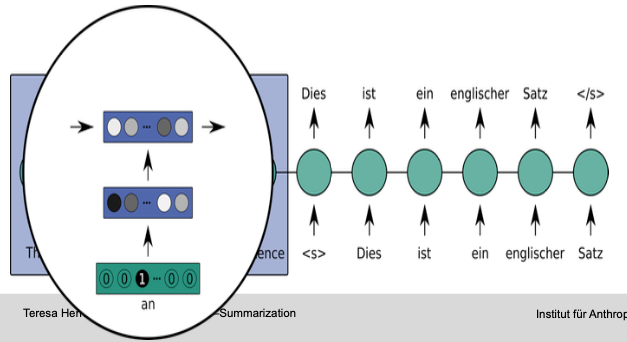
- One–hot encoding
- Word embedding
- RNN layer(s)
Decoder
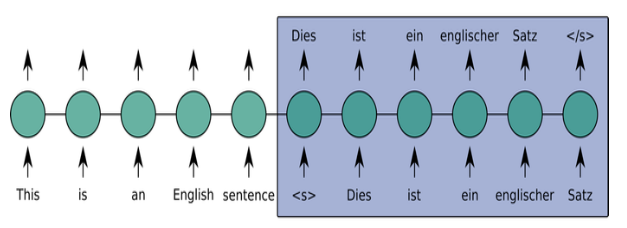
Generate output: Use output of encoder as input
LSTM-based model
Input last target word
Attention-based Encoder-Decoder
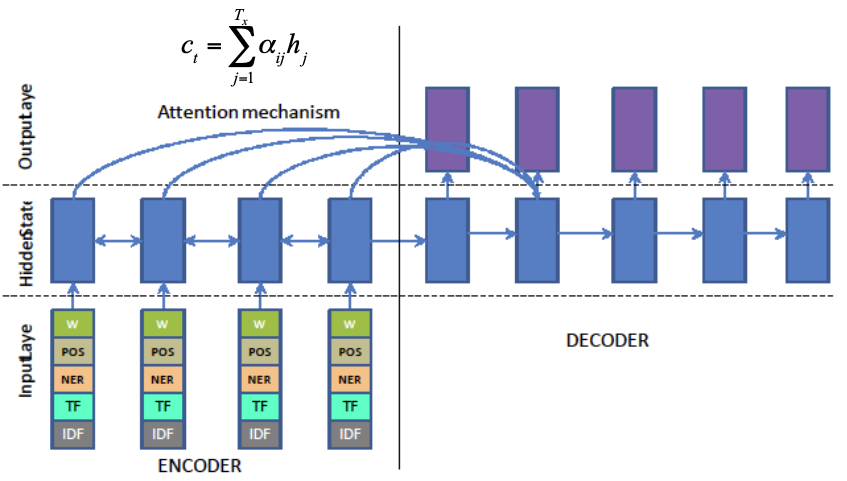
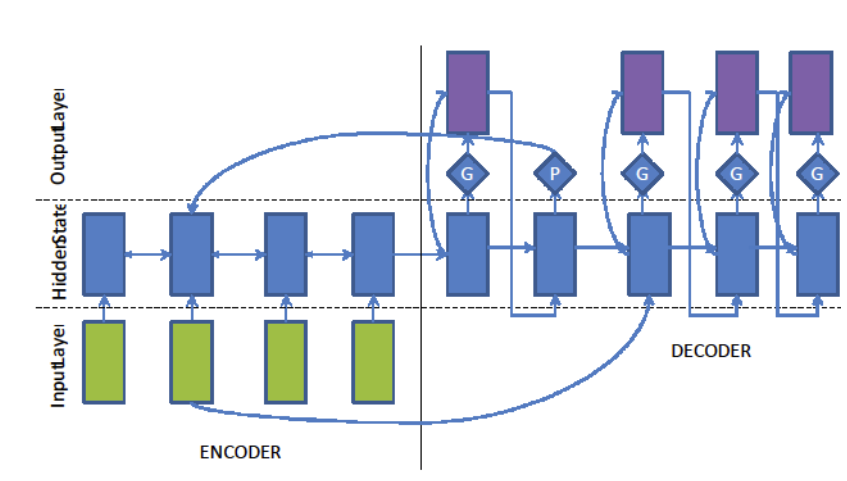
Attention-based Encoder : copy mechanism
Calculate probability “better to generate one word from vocabulary than to copy a word from source sentence“
$$ p\_{g e n}=\sigma\left(w\_{c}^{T} c\_{t}+w\_{s}^{T} s\_{t}+w\_{x}^{T} x\_{t}+b\_{p t r}\right) $$Word with the highest probability should be the output word
$$ P(w)=p\_{g e n} P\_{v o c a b}(w)+\left(1-p\_{g e n}\right) \sum\_{j: w\_{j}=w} \alpha\_{i j} $$Data
- Training data
- Documents and summary
- DUC data set
- News article
- Around 14 word summary
- Giga word
- News articles
- Headline generation
- CNN/Mail Corpus
- Article
- Predict bullet points
Reference
- TF-IDF: