Question Answering
Definition
Question Answering
Automatically answer questions posed by humans in natural language
Give user short answer to their question
Gather and consult necessary information
Related topics
Information Retrieval
Reading Comprehension
Database Access
Dialog
Text Summarization
Problem Dimensions
Questions
- Question class
- Almost universally factoid questions E.g.: “What does the Peugeot company manufacture?”
- More open in dialog context
- Question domain
Topic of the content
Open-Domain: Any topic
Closed-Domain: Specific topic, e.g. movies, sports, etc
- Context
- How much context is provided?
- Is search necessary?
- Answer types
- Factual Answers
- Opinion
- Summary
- Kind of questions
Yes/No
“wh”-questions
Indirect requests (I would like to…)
Commands
Applications
- Knowledge source types
Structured data (database)
Semi-structured data (e.g. Wikipedia tables)
Free text (e.g. Wikipedia text)
- Knowledge source origins
- Search over the web
- Search of a collection
- Single text
- Domain
- Domain-independent
- Domain-specific system
Users
First time/casual users
- Explain limitations
Power users
Emphasize novel information
Omit previously provided information
Answers
- Long
- Short
- Lists
- Narrative
- Creation
- Extraction
- Generation
Evaluation
- What is a good answer?
- Should the answer be short or long?
- Easier to have the answer in longer segments
- Less concise, more comprehensive
Presentation
Underspecified question
Feedback
Too many documents
Text or speech input
Examples
- TREC
- SQuAD (Stanford Question Answering Dataset)
- IBM Watson
Motivation
- Vast amounts of information written by humans for humans
- Computers are good at searching vast amounts of information
- Natural interaction with computers 💪
System Approaches
Text-based system
- Use information retrieval to search for matching documents
Knowledge-based approaches
Build semantic representation of the query
Retrieve answer from semantic databases (Ontologies)
Knowledge-rich / hybrid approaches
Combine both
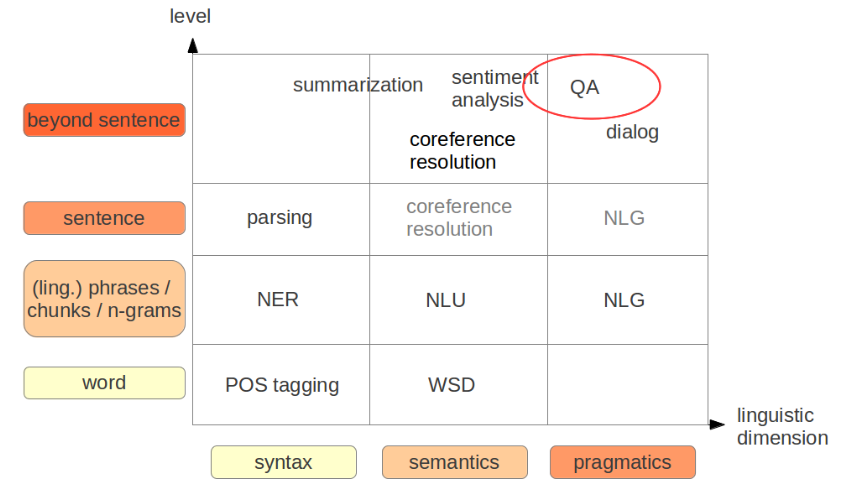
QA System Overview
Components
Information Retrieval
- Need to find good text segments
Answer Extraction
- Given some context and the question, produce an answer
- Either part may be supplemented by other NLP tools
Common Components
Preprocessing
Question Analysis
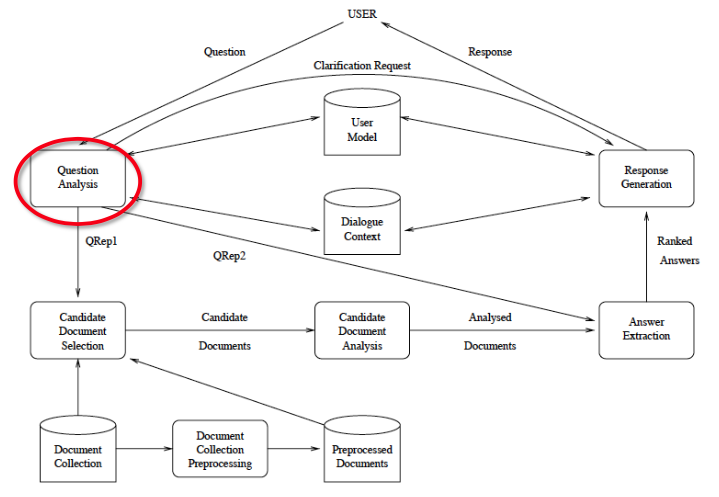
Input: Natural language question
Implicit input
Dialog state
User information
Derived inputs
- POS-tags, NER, dependency graph, syntax tree, etc.
Output: Representation for Information Retrieval and Answer Extraction
- For IR: Weighted vector or search term collection
- For answer extraction
- Lexical answer type (person/company/acronym/…)
- Additional constraints (e.g. relations)
Answer Type Classification
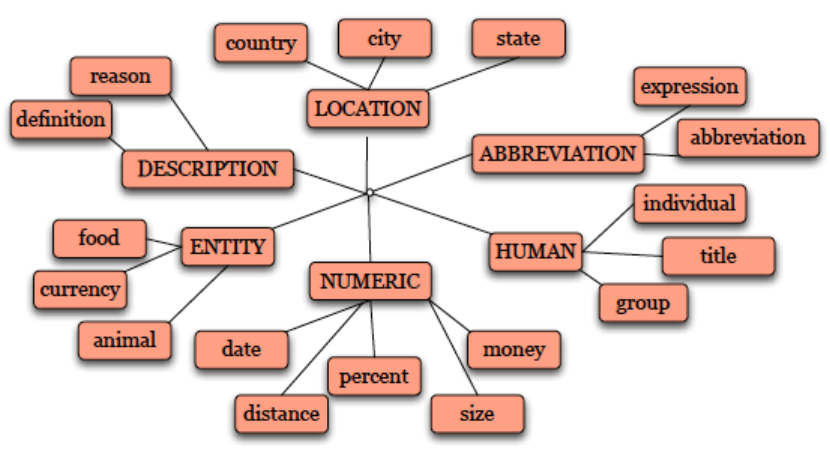
Classical approach: Question word (who, what, where,…)
When: date
Who: person
Where: location
Examples
Regular expressions
Who {is | was | are | were } – Person
Question head word (First noun phrase after the question word)
- Which city in China has the largest number of foreign financial companies?
- What is the state flower of California?
🔴 Problems
- “Who” questions could refer to e.g. companies
- E.g. “Who makes the Beetle?”
- Which / What is not clear
- E.g. “What was the Beatles’ first hit single?”
- “Who” questions could refer to e.g. companies
Approaches
- Manually created question type hierarchy
- Machine learning classification
(Current ML systems often do NOT use Answer Type Classification 😂)
Constraints
Keyword extraction
- Expand keywords using synonyms
Statistical parsing
- Identify semantic constraints
Example
Represent a question as bag-of-words
“What was the monetary value of the Nobel Peace Price in 1989?”
monetary, value, Nobel, Peace, Price, 1989“What does the Peugeot company manufacture?”
Peugeot, company, manufacture“How much did Mercury spend on advertising in 1993?”
Mercury, spend, advertising, 1993
Retrieval: Candidate Document Selection
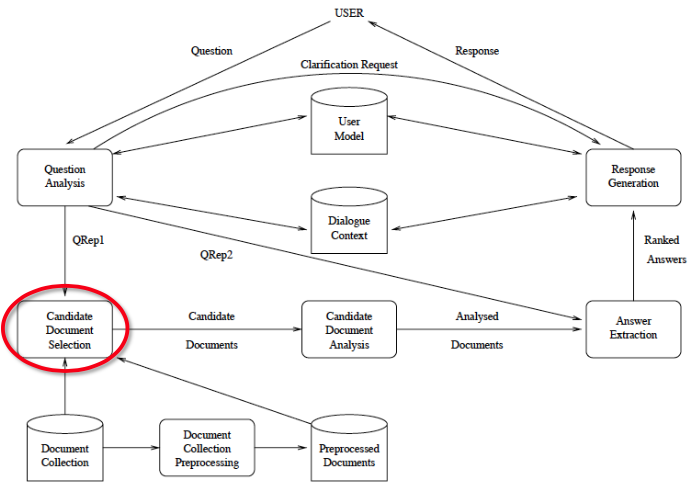
Most common approach:
- Conventional Information Retrieval search
Using search indices
Lucene
TF-IDF
- Several stages: Coarse-to-fine search
- Conventional Information Retrieval search
Result: Small set of documents for detailed analysis
Decisions: Boolean vs. rank-based engines
Retrieve only part of the document
- Mostly only part of the document is important
Passage retrieval
- Return only subsets of the document
Segment document into coherent text segments
Combine results from multiple search engines
Text-based system
Use only syntactic information such as n-grams
Example: TF-IDF (Term Frequency, Inverse Document frequency)
Weighted bag-of-words vector
One component per word in vocabulary
Term frequency: Number of times term appears in the document
Document frequency: Number of documents the term appears in
Knowledge-based / semantic-based system
Build semantic representation by extracting information from the question
Construct structured query for semantic database
Not raw or indexed text corpus
Examples
WordNet
Wikipedia Infoboxes
FreeBase
Candidate Document Analysis
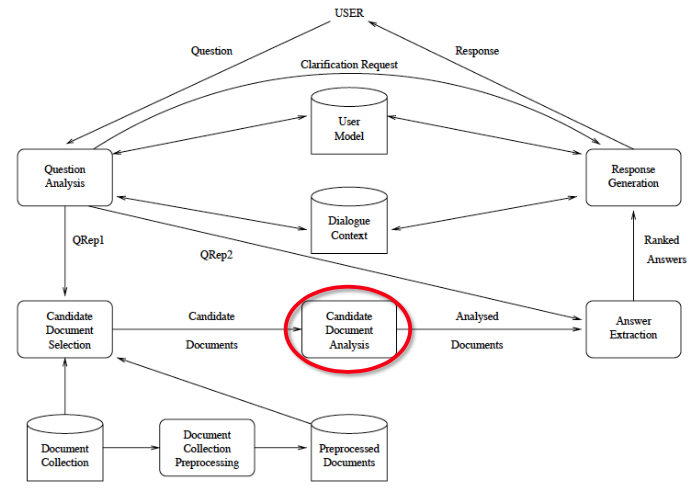
- Named entity tagging
- Often including subclasses (towns, cities, provinces, …)
- Sentence splitting, tagging, chunk parsing
- Identify multi-word terms and their variants
- Represent relation constraints of the text
Answer Extraction
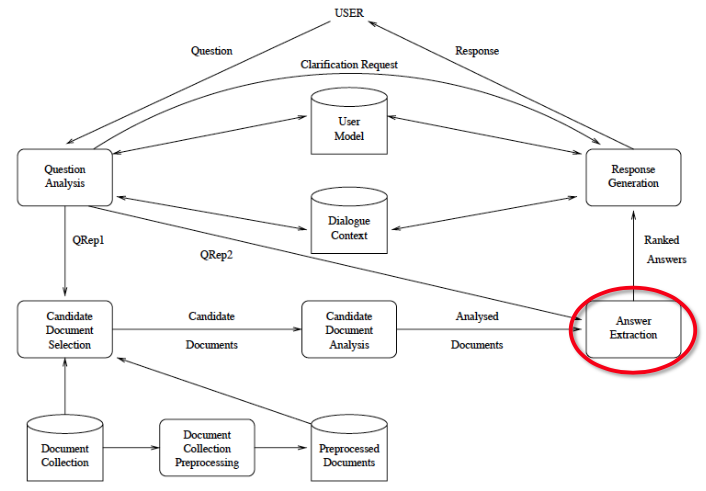
Input
Representations for candidate text segments and question
Rank set of candidate sentences
Expected answer type(s)
Find answer strings that match the answer type(s) based on documents
Extractive: Answers are substrings in the documents
Generative: Answers are free text (NLG)
Rank the candidate answers
- E.g. overlap between answer and question
Return result(s) with best overall score
Example

Response Generation
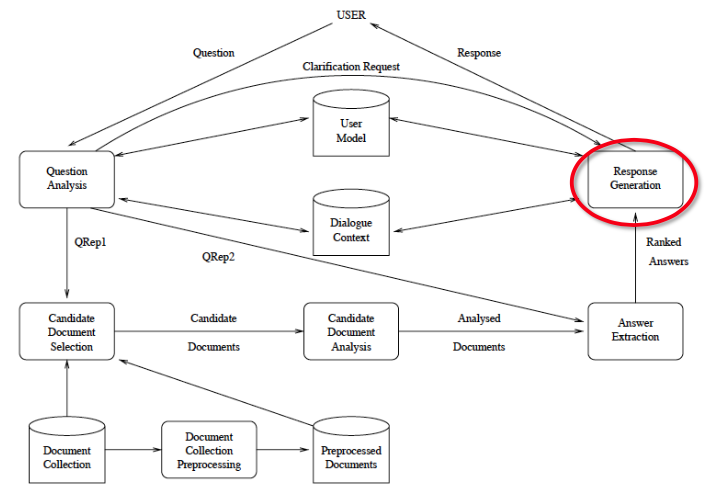
Rephrase text segment
- E.g. resolve anaphors
Provide longer or shorter answer
- Add some part of context into the answer
If answer is too complex
Truncate answer
Start dialog
Neural Network Approach
- Neural models struggle with Information Retrieval 🤪
- Excellent results on answer extraction 😍
- Given: Question and Context (document, paragraph, nugget, etc.)
- Result: Answer as substring from context
- Predict most likely start and end index as classification task
- Combines:
- Question Analysis
- Retrieved Document Analysis
- Answer Extraction
- Response Generation
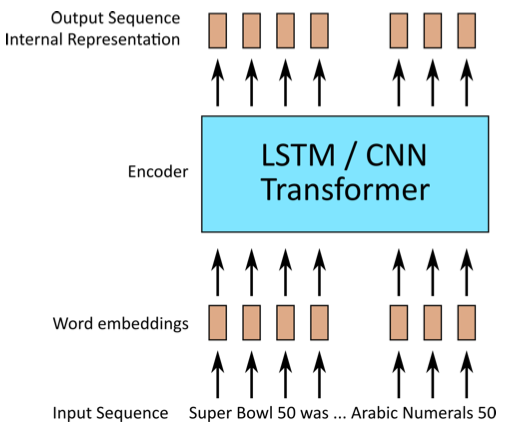
Neural Answer Extraction
Encoder-decoder model
Encoder
Answer prediction
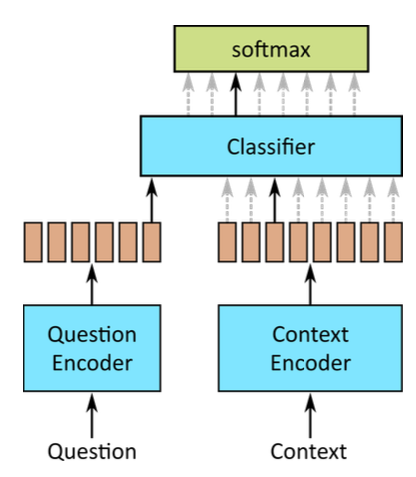
- Softmax output $i$ is probability that answer starts at token $i$
- Mirrored setup for end probability
- 🔴 Problem: Relying on single vector for question encoding
- Long range dependencies
- Feedback at end of sequence
- Vanishing gradients
Solution: Use MORE information from the question
–> Attention mechanism
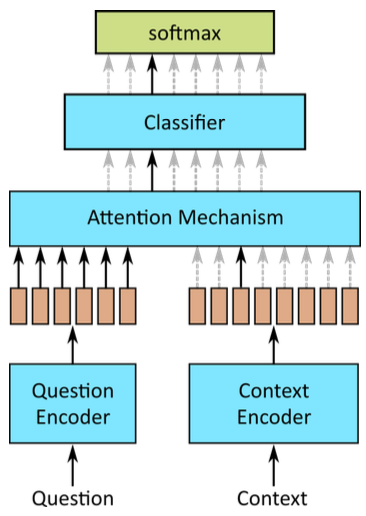
- Calculates weighted sum of question encodings
- Weight is based on similarity between question encoding and context encoding
- Different similarity metrics