Natural Language Generation
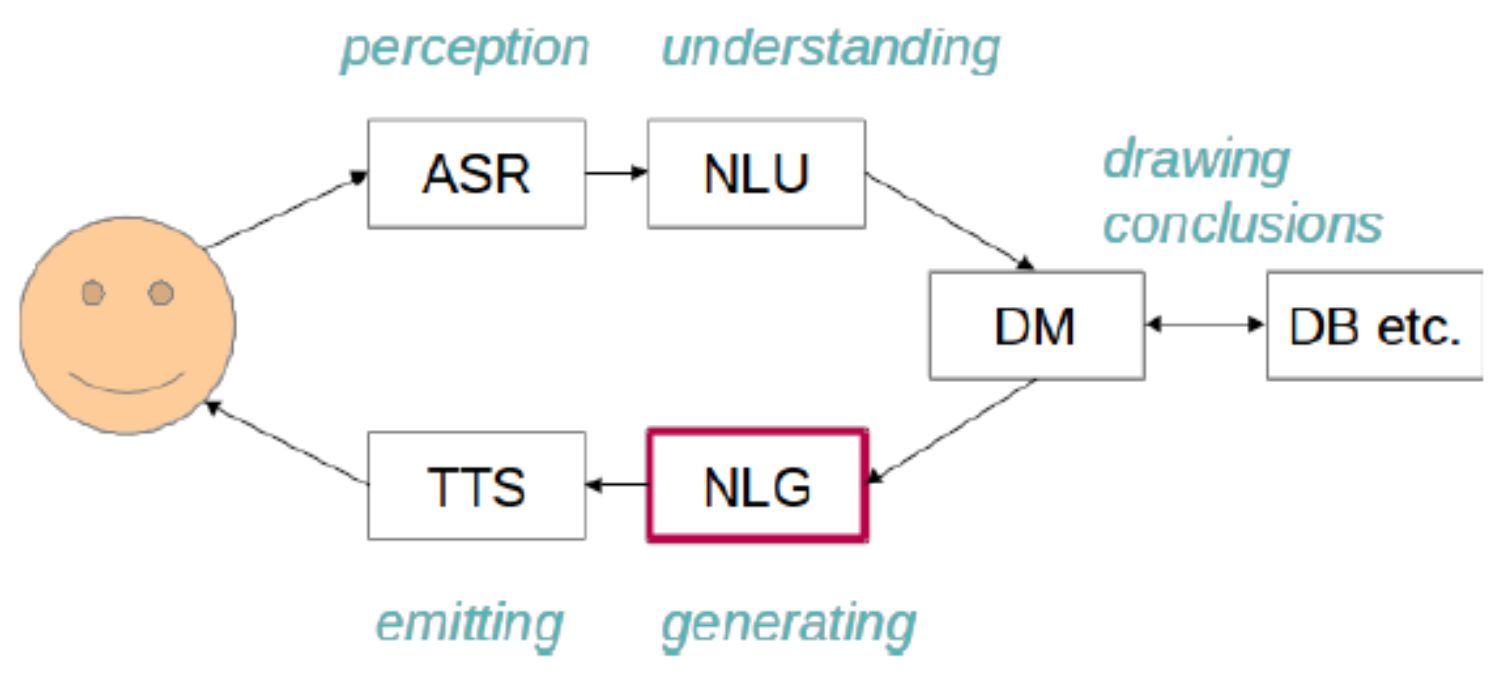
Motivation
🎯 Goal: generate natural language from semantic representation (or other data)
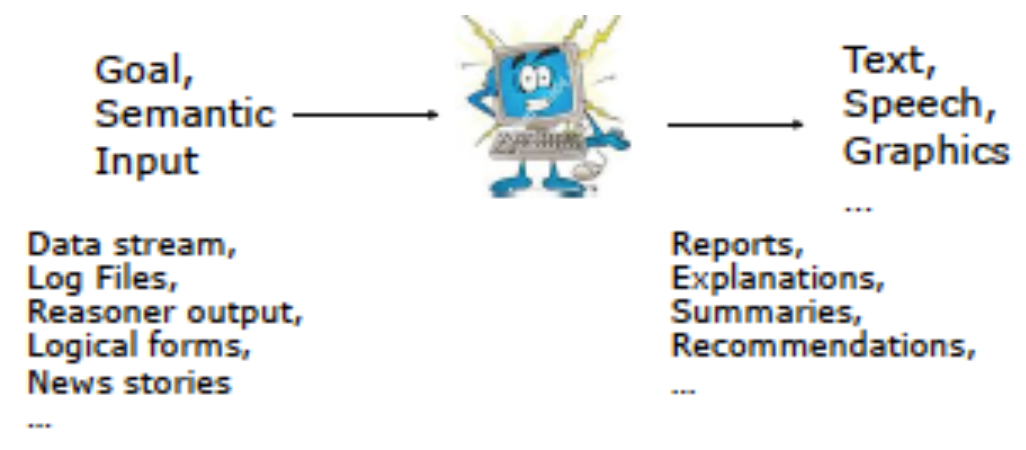
Examples
Pollen Forecast
Pollen Forecast for Scotland
Taking six numbers as input, a simple NLG system generates a short textual summary of pollen levels
“Grass pollen levels for Friday have increased from the moderate to high levels of yesterday with values of around 6 to 7 across most parts of the country. However, in Northern areas, pollen levels will be moderate with values of 4.”
The actual forecast (written by a human meteorologist) from the data
“Pollen counts are expected to remain high at level 6 over most of Scotland, and even level 7 in the south east. The only relief is in the Northern Isles and far northeast of mainland Scotland with medium levels of pollen count.”
Weather Forecast
Function: Produces textual weather reports in English and French
Input: Numerical weather simulation data annotated by human forecaster
Difficulties/Challenges
Making choices
Content to be included/omitted
Organization of content into coherent structure
Style (formality, opinion, genre, personality…)
Packaging into sentences
Syntactic constructions
How to refer to entities (referring expression generation)
What words to use (lexical choice)
Rule-based methods
Six basic activities in NLG:
Deciding what information to mention in the text
Discourse planning
Imposing ordering and structure over the information to convey
Merging of similar sentences to improve readability and naturalness
Deciding the specific words and phrases to express the concepts and relations
Referring expression generation
Selecting words or phrases to identify domain entities
Creating the actual text, which is correct according to the grammar rules of syntax, morphology and orthography
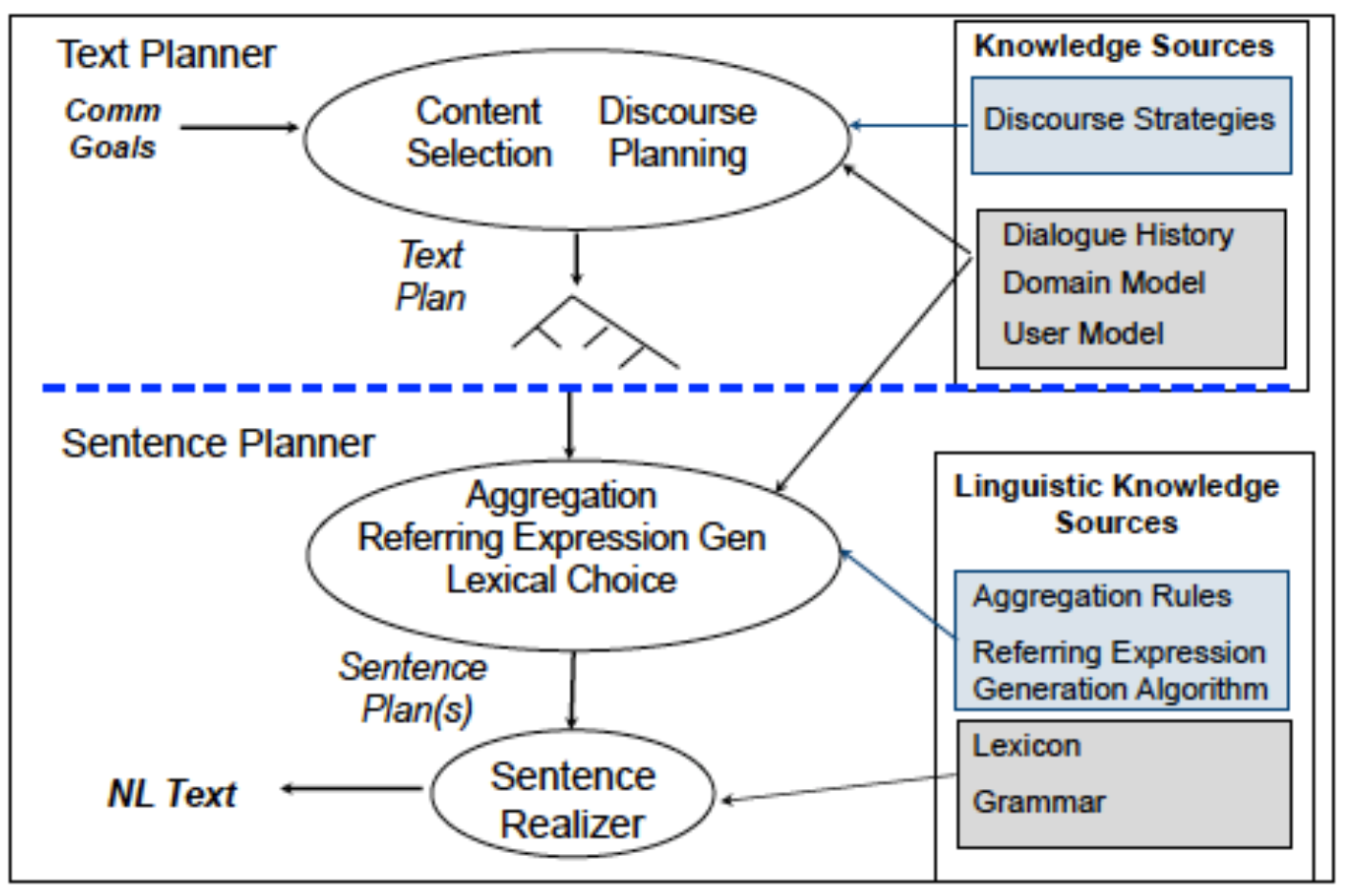
3-stages pipelined architecture:
- Text planning (Act 1 and 2)
- Sentence planning (Act 3, 4, and 5)
- Linguistic realization (Act 6)
Intermediate representations: Text plans
- Represented as trees whose leaf nodes specify individual messages and internal nodes show how messages are conceptually grouped
Sentence plans
- Template representation, possibly with some linguistic processing → Represent sentences as boilerplate text and parameters that need to be inserted into the boilerplate text
- abstract sentential representation → Specify the content words (nouns, verbs, adjectives and adverbs) of a sentence, and how they are related
Text/Document planner
Determine
- what information to communicate
- how to structure information into a coherent text
Common Approaches:
methods based on observations about common text structures (Schemas)
methods based on reasoning about the purpose of the text and discourse coherence (Rhetorical Structure Theory, planning)
Content Selection
Text is sequence of MESSAGES, predefined data structures:
- correspond to informational units in the text
- collect together underlying data in ways that are convenient for linguistic expression
How to devise MESSAGE types?
- Rhetorical predicates: generalizations made by linguists
- From corpus analysis, identify agglomerations of informational elements
- Application dependent
Rhetorical predicates
Attribute
E.g. Mary has a pink coat.
Equivalence
E.g. Wines described as ‘great’ are fine wines from an especially good village.
Specification
E.g. [The machine is heavy.] It weighs 2 tons.
Constituency
E.g. [This is an octopus.] There is his eye, these are his legs, and he has these suction cups.
Evidence
E.g. [The audience recognized the difference.] They started laughing right from the very first frames of that film.
…
Corpus-based content selection
(Take weather forecast as example)
- Routine messages: always included
- E.g.
MonthlyRainFallMsgMonthlyTemperatureMsgRainSoFarMsgMonthlyRainyDaysMsg
- E.g.
- Significant Event messages: Only constructed if the data warrants it
- E.g. if rain occurs on more than a specified number of days in a row
RainEventMsgRainSpellMsgTemperatureEventMsg
- E.g. if rain occurs on more than a specified number of days in a row
Example

Define Schemas

Produces a text/document plan
- a tree structure populated by messages at its leaf nodes
Aggregation
Deciding how messages should be composed together to produce specifications for sentences or other linguistic units
On the basis of
- Information content
- Possible forms of realization
- Semantics
Some possibilities:
- Simple conjunction
- Ellipsis
- Embedding
- Set introduction
Example
Without aggregation:
Heavy rain fell on the 27th. Heavy rain fell on the 28th.Aggregation via simple conjunction:
Heavy rain fell on the 27th and heavy rain fell on the 28th.Aggregation via ellipsis:
Heavy rain fell on the 27th and [] on the 28th.Aggregation via set introduction:
Heavy rain fell on the 27th and 28th.
Lexicalization
- Choose words and syntactic structures to express content selected
- If several lexicalizations are possible, consider:
user knowledge and preferences
consistency with previous usage
Pragmatics: emphasis, level of formality, personality, …
interaction with other aspects of micro planning
- Example
S: rainfall was very poor
NP: a much worse than average rainfall
ADJP: much drier than average
Generating Referring Expressions (GRE)
Identify specific domain objects and entities
GRE produces description of object or event that allows hearer to distinguish it from distractors
Issues
Initial introduction of an object
Subsequent references to an already salient object
Example
Referring to months:
June 1999
June
the month
next June
Referring to temporal intervals
- 8 days starting from the 11th
- From the 11th to the 18th
(Relatively simple, so can be hardcoded in document planning)
Realization
🎯 Goal: to convert text specifications into actual text
Purpose: hide the peculiarities of the target language from the rest of the NLG system
Example
Evaluation
Task-based (extrinsic) evaluation
- how well the generated text helps to perform a task
Human ratings
- quality and usefulness of the text
Metrics
e.g. BLEU (Bilingual Evaluation Understudy)
Quality is considered to be the correspondence between machine’s output and that of a human
Statistical methods
Problems of conventional NLG components
- expensive to build
- need lots of handcrafting or a well-labeled dataset to be trained on
- kind and amount of available data severely limits the development 😢
- makes cross-domain, multi-lingual SDSs (Spoken Dialogue Systems) intractable 😢
Motivation
- human languages are context-aware
- natural response should be directly learned from data than depending on defined syntaxes or rules
Deep Learning NLG
Significant progress in applying statistical method for SLU and DM in past decade
- including making them more easily extensible to other application/domains
Data-driven NLG for SDSs relatively unexplored due to mentioned difficulty of collecting semantically-annotated corpora
- rule-based NLG remains the norm for most systems
Goal of the NLG component of an SDS:
map an abstract dialog act consisting of an act type and a set of attribute(slot)-value pairs into an appropriate surface text
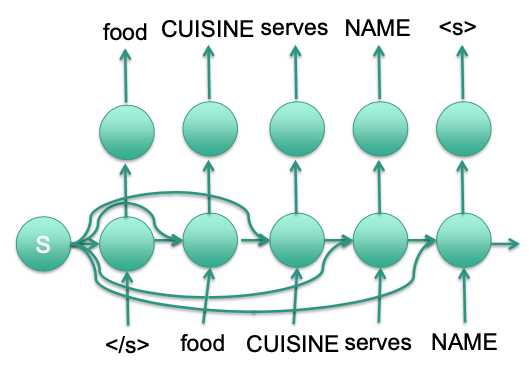
(RNN-based) Generation
Conditional text generation
- Text has different length
Use RNN-based neural network
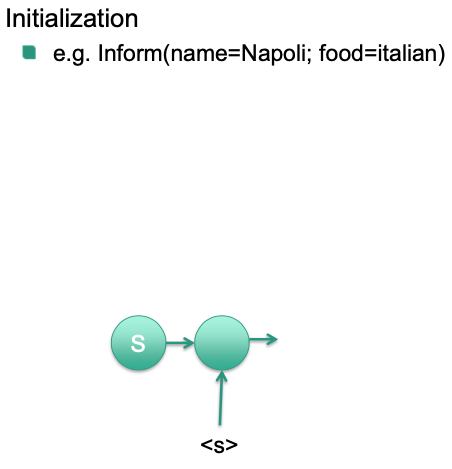
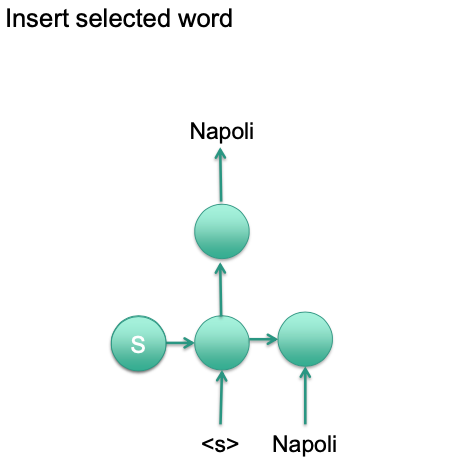
Decoding
Initialize RNN with input
- Hidden state or first input
Generate output probability for first word
Sample first word/Select most probable word
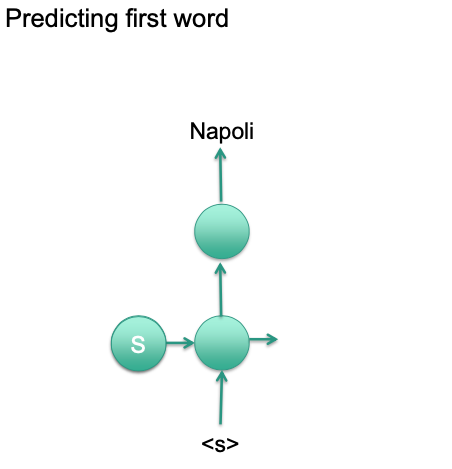
Insert selected word into RNN
Continue till
<eos>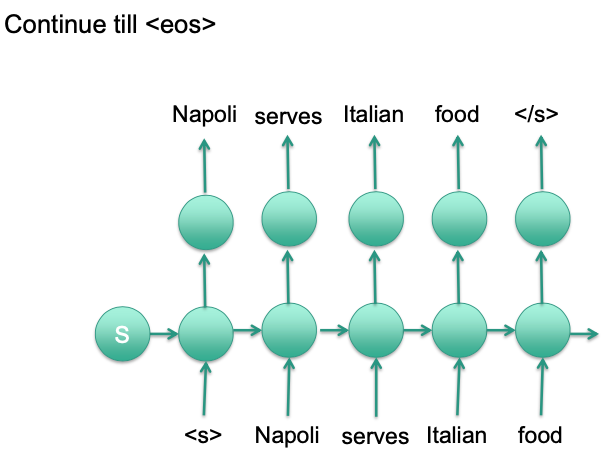
🔴 Challenges
Large vocabulary
Names of all restaurants
Delexicalization: Replace slot values by slot names
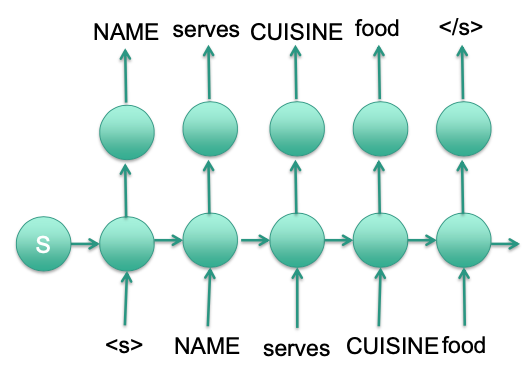
Vanishing gradient
Repeated input
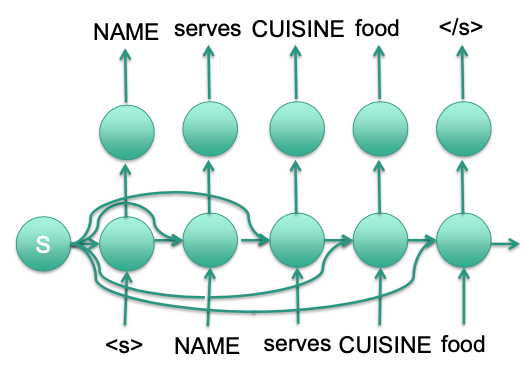
Gating of input vector
Problem: Output NAME several times
Remove NAME from S when it has been output
Only backward dependencies
Rerank output with different models
- N-Best list reranking
- Cannot look at all possible output
- But: Generate several good outputs (e.g. top 10; top 100)
- Then we can also use other models to evaluate them
- Possible to select different one
- But if good output is not in best, we can not find it 🤪
- N-Best generation
- Beam search
- Select top $k$ words at timestep 1
- Independently insert all of them at timestep 2
- Select top $k$ words
- $k*k$ possible output at timestep 2
- Filter top $k$
- Continue with top $k$ at timestep 3
- Beam search
- N-Best list reranking
Right to left
Rescoring
Inverse direction
Left to write decoding
- RNN allows generation from left-to-right
- 👍 Advantages
- Do not need to generate all possible output and then evaluate
- Possible for most task
- 👎 Disadvantages
No global view
Word probability only on previous words
Non optimal modeling if all slots have been filed
- 👍 Advantages
Generating long sequence
RNN prefers short sequences –> Hard to train long sequences 😢
- Incoherent E.g. The sun is the center of the sun
- Redundant E.g. I like cake and cake
- Contradictory E.g. I don’t own a gun, but I do own a gun
💡 Idea:
Generate only fix length segments
Condition on input and previous target sequence
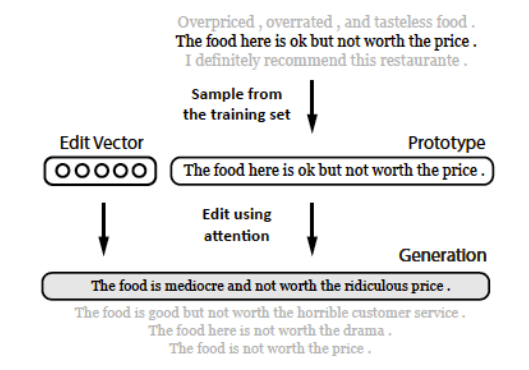
Generating by editing
Similar sentence should be in the training data
- Edit this sentence instead of generating new sentence
💡Idea
Find similar sentence
Combine edit vector and input sentence
Generate output sentence
Use sequence to sequence model
Again RNN
But easier to copy then to generate