Dialog Management
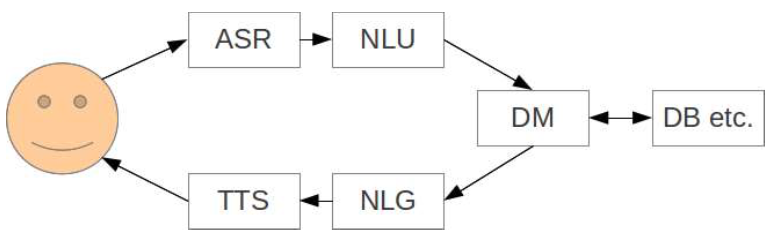
Dialog Modeling
Dialog manager
Manage flow of conversation
Input: Semantic representation of the input
Output: Semantic representation of the output
Utilize additional knowledge
User information
Dialog History
Task-specific information
🔴 Challenges
Consisting of many different components
Each component has errors
More components –> less robust
Should be modular
Need to find unambiguous representation
Hard to train from data
Dialog Types
Goal-oriented Dialog
- Follows a fixed (set of) goals
Ticket vending machines
Restaurant reservation
Car SDS
- Aim: Reach goal as fast as possible
- Main focus of SDS research
Social Dialog
Social Dialog / Conversational Bots / Chit-Chat Setting
Most human
Small talk conversation
Aims:
Generate interesting, coherent, meaningful responses
Carry-on as long as possible
Be a companion
Dialog Systems
Initiative
System Initiative
Command & control
Example (U: User, S: System)

Mixed Initiative
Most nature
Example

User Initiative
User most powerful
Error-prone
Example

Confirmation
Explicit verification

Implicit verification

Alternative verification

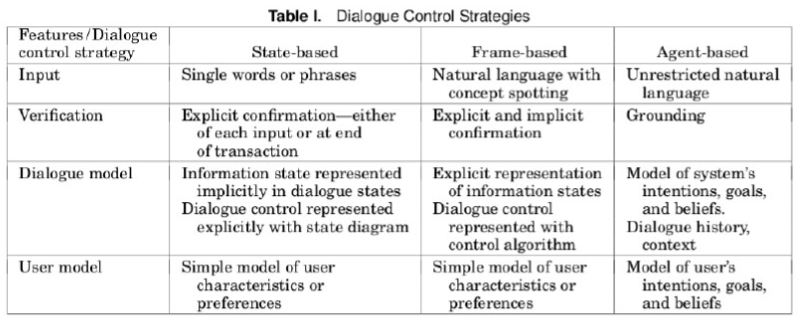
Development
- Create management by templates/rules
- Train model to predict answer given input
- POMDP
- No separation into NLU/DM/NLG
Components
Dialog Model: contains information about
- whether system, user or mixed initiative?
- whether explicit or implicit confirmation?
- what kind of speech acts needed?
User Model: contains the system’s beliefs about
what the user knows
the user’s expertise, experience and ability to understand the system’s utterances
Knowledge Base: contains information about
- the world and the domain
Discourse Context: contains information about
- the dialog history and the current discourse
Reference Resolver
- performs reference resolution and handles ellipsis
Plan Recognizer and Grounding Module
- interprets the user’s utterance given the current context
- reasons about the user’s goals and beliefs
Domain Reasoner/Planner
- generates plans to achieve the shared goals
Discourse Manager
- manages all information of dialog flow
Error Handling
- errors or misunderstandings detection and recovery
Rule-based Systems
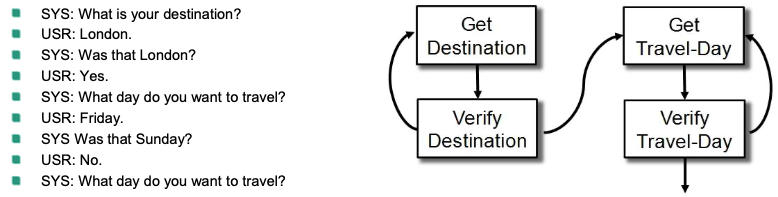
Finite State-based
💡 Idea: Iterate though states that define actions
Dialog flow:
specified as a set of dialog states (stages)
transitions denoting various alternative paths through the dialog graph
Nodes = dialogue states (prompts)
Arcs = actions based on the recognized response
Example
👍 Advantages
- Simple to construct due to simple dialog control
- The required vocabulary and grammar for each state can be specified in advance
- Results in more constrained ASR and SLU
👎 Disadvantages
- Restrict the user’s input to predetermined words/phrases
- Makes the correction of misrecognized items difficult
- Inhibits the user’s opportunity to take the initiative and ask questions or introduce new topics
Frame-based
💡 Idea: Fill slots in a frame that defines the goal
Dialog flow:
- is NOT predetermined, but depends on
the contents of the user’s input
the information that the system has to elicit
- is NOT predetermined, but depends on
Example
Eg1

Eg2

Slot(/Form/Template) filling
One slot per piece of information
Takes a particular action based on the current state of affairs
Questions and other prompts
- List of possibilities
- conditions that have to be true for that particular question or prompt
👍 Advantages
- User can provide over-informative answers
- Allows more natural dialogues
👎 Disadvantages
- Cannot handle complex dialogues
Agent-based
💡 Idea:
Communication viewed as interaction between two agents
Each capable of reasoning about its own actions and beliefs
also about other’s actions and beliefs
Use of “contexts”
Example

Allow complex communication between the system, the user and the underlying application to solve some problem/task
Many variants depends on particular aspects of intelligent behavior included
Tends to be mixed-initiative
- User can control the dialog, introduce new topics, or make contribution
👍 Advantages
- Allow natural dialogue in complex domains
👎 Disadvantages
- Such agents are usually very complex
- Hard to build 😢
Limitations of Rule-based DM
Expensive to build Manual work
Fragile to ASR errors
No self-improvement over time
Statistical DM
Motivation
User intention can ONLY be imperfectly known
- Incompleteness – user may not specify full intention initially
- Noisiness – errors from ASR/SLU
Automatic learning of dialog strategies
- Rule based time consuming
👍 Advantages
Maintain a distribution over multiple hypotheses for the correct dialog state
- Not a single hypothesis for the dialog state
Choose actions through an automatic optimization process
Technology is not domain dependent
- same technology can be applied to other domain by learning new domain data
Markov Decision Process (MDP)
A model for sequential decision making problems
- Solved using dynamic programming and reinforcement learning
- MDP based SDM: dialog evolves as a Markov process
Specified by a tuple $(S, A, T, R)$
$S$: a set of possible world states $s \in S$
$A$: a set of possible actions $a\in A$
$R$: a local real-valued reward function
$$ R: S \times A \mapsto \mathcal{R} $$$T$: a transition mode
$$ T(s\_{t-1}, a\_{t-1}, s\_t) = P(s\_t | s\_{t-1}, a\_{t-1}) $$
🎯 Goal of MDP based SDM: Maximize its expected cumulative (discounted) reward
$$ E\left(\sum\_{t=0}^{\infty} \gamma^{t} R\left(s\_{t}, a\_{t}\right)\right) $$Requires complete knowledge of $S$ !!!
Reinforcement Learning
“Learning through trial-and-error” (reward/penalty)
🔴 Problem
No direct feedback
Only feedback at the end of dialog
🎯 Goal: Learn evaluation function from feedback
💡 Idea
Initial all operations have equal probability
If dialog was successful –> all operations are positive
If dialog was negative –> operations negative
How RL works?
There is an agent with the capacity to act
Each action influences the agent’s future state
Success is measured by a scalar reward signal
In a nutshell:
Select actions to maximize future reward
Ideally, a single agent could learn to solve any task 💪
Sequential Decision Making
- 🎯 Goal: select actions to maximize total future reward
- Actions may have long term consequences
- Reward may be delayed
- It may be better to sacrifice immediate reward to gain more long-term reward 🤔
Agent and Environment
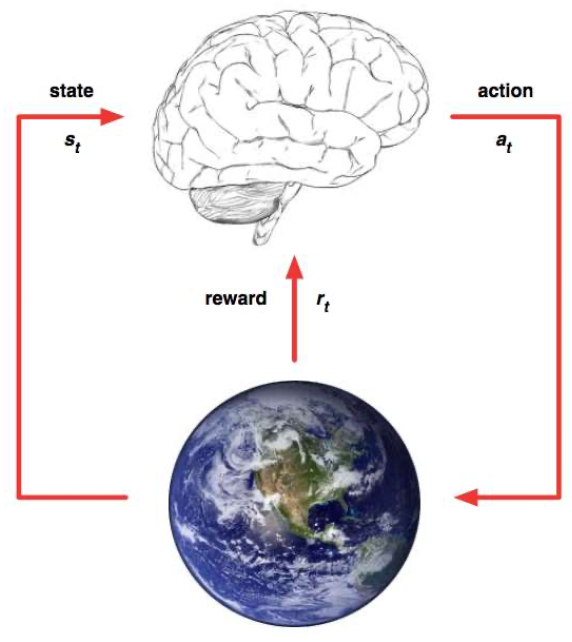
At each step $t$
- Agent:
- Receives state $s\_t$
- Receives scalar reward $r\_t$
- Executes action $a\_t$
- The environment:
- Receives action $a\_t$
- Emits state $s\_t$
- Emits scalar reward $r\_t$
- The evolution of this process is called a Markov Decision Process (MDP)
Supervised Learning Vs. Reinforcement Learning
Supervised Learning:
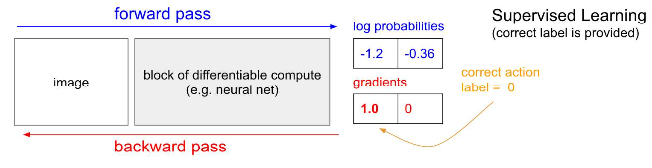
- Label is given: we can compute gradients given label and update our parameters
Reinforcement Learning
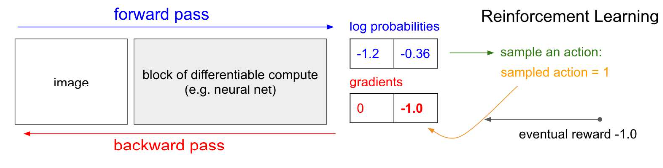
- NO label given: instead we have feedback from the environment
- Not an absolute label / error. We can compute gradients, but do not yet know if our action choice is good. 🤪
Policy and Value Functions
Policy $\pi$ : a probability distribution of actions given a state
$$ a = \pi(s) $$Value function $Q^\pi(s, a)$ : the expected total reward from state $s$ and action $a$ under policy $\pi$
$$ Q^{\pi}(s, a)=\mathbb{E}\left[r\_{t+1}+\gamma r\_{t+2}+\gamma^{2} r\_{t+3}+\cdots \mid s, a\right] $$- “How good is action $a$ in state $s$?”
- Same reward for two actions, but different consequences down the road
- Want to update our value function accordingly
- “How good is action $a$ in state $s$?”
Appoaches to RL
Policy-based RL
Search directly for the optimal policy $\pi^\*$
(policy achieving maximum future reward)
Value-based RL
- Estimate the optimal value function $Q^{∗}(s,a)$ (maximum value achievable under any policy)
- Q-Learning: Learn Q-Function that approximates $Q^{∗}(s,a)$
- Maximum reward when taking action $a$ in $s$
- Policy: Select action with maximal $Q$ value
- Algorithm:
- Initialized $Q$ randomly
- $Q(s, a) \leftarrow(1-\alpha) Q(s, a)+\alpha\left(r\_{t}+\gamma \cdot \underset{a}{\max} Q\left(s\_{t+1}, a\right)\right)$
Goal-oriented Dialogs: Statistical POMDP
POMDP : Partially Observable Markov Decision Process
MDP –> POMDP: all states $s$ cannot observed
POMDP based SDM –> reinforcement learning + belief state tracking
dialog evolves as a Markov process $P(s\_t | s\_{t-1}, a\_{t-1})$
$s\_t$ is NOT directly observable
–> belief state $b(s\_t)$: prob. distribution of all states
SLU outputs a noisy observation $o\_t$ of the user input with prob. $P(o\_t|s\_t)$
Specified by tuple $(S, A, T, R, O, Z)$
$S, A, T, R$ constitute an MDP
$O$: a finite set of observations received from the environment
$Z$: the observation function s.t.
$$ Z(o\_t,s\_t,a\_{t-1}) = P(o\_t|s\_t,a\_{t-1}) $$
Local reward is the expected reward $\rho$ over belief states
$$ \rho(b, a)=\sum\_{s \in S} R(s, a) \cdot b(s) $$Goal: maximize the expected cumulative reward.
Operation (at each time step)
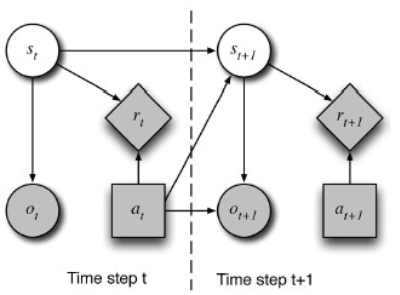 - World is in unobserved state $s\_t$
- World is in unobserved state $s\_t$Maintain distribution over all possible states with $b\_t$
$$ b\_t(s\_t) = \text{Probability of being in state } s\_t $$DM selects action $a\_t$ based on $b\_t$
Receive reward $r\_t$
Transition to unobserved state $s\_{t+1}$ ONLY depending on $s\_t$ and $a\_t$
Receive obserservation $o\_{t+1}$ ONLY depending on $a\_t$ and $s\_{t+1}$
Update of belief state
$$ b\_{t+1}\left(s\_{t+1}\right)=\eta P\left(o\_{t+1} \mid s\_{t+1}, a\_{t}\right) \sum\_{s\_{t}} P\left(s\_{t+1} \mid s\_{t}, a\_{t}\right) b\_{t}\left(s\_{t}\right) $$Policy $\pi$:
$$ \pi(b) \in \mathbb{A} $$Value function:
$$ V^{\pi}\left(b\_{t}\right)=\mathbb{E}\left[r\_{t}+\gamma r\_{t+1}+\gamma^{2} r\_{t+2}+\ldots\right] $$
POMDP model
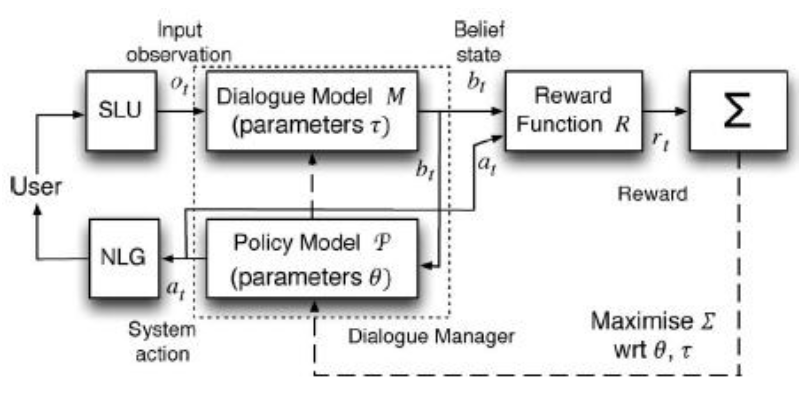
Two stochastic models
- Dialogue model $M$
- Transition and observation probability model
- In what state is the dialogue at the moment
- Policy Model $\mathcal{P}$
- What is the best next action
- Dialogue model $M$
Both models are optimized jointly
- Maximize the expect accumulated sum of rewards
- Online: Interaction with user
- Offline: Training with corpus
- Maximize the expect accumulated sum of rewards
Key ideas
- Belief tracking
Represent uncertainty
Pursuing all possible dialogue paths in parallel
- Reinforcement learning
- Use machine learning to learn parameters
- Belief tracking
🔴 Challenges
- Belief tracking
- Policy learning
- User simulation
Belief state
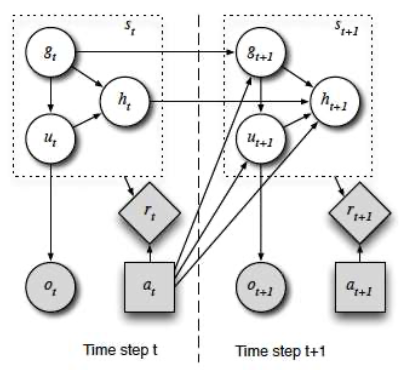
Information encoded in the state
$$ \begin{aligned} b\_{t+1}\left(g\_{t+1}, u\_{t+1}, h\_{t+1}\right)=& \eta P\left(o\_{t+1} \mid u\_{t+1}\right) \\\\ \cdot & P\left(u\_{t+1} \mid g\_{t+1}, a\_{t}\right) \\\\ \cdot & \sum_{g\_{t}} P\left(g\_{t+1} \mid g\_{t}, a\_{t}\right) \\\\ \cdot & \sum_{h\_{t}} P\left(h\_{t+1} \mid g\_{t+1}, u\_{t+1}, h\_{t}, a\_{t}\right) \\\\ \cdot & b\_{t}\left(g\_{t}, h\_{t}\right) \end{aligned} $$- User goal $g\_t$: Information from the user necessary to fulfill the task
- User utterance $u\_t$
- What was said
- Not what was recognized
- Dialogue history $h\_t$
Using independence assumptions
Observation model: Probability of observation $o$ given $u$
- Reflect speech understanding errors
User model: Probability of the utterance given previous output and new state
Goal transition model
History model
Model still too complex 🤪
- Solution
- n-best approach
- Factored approach
- Combination is possible
- Solution
Policy
- Mapping between belief states and system actions
- 🎯 Goal: Find optimal policy π’
- Problem: State and action space very large
- But:
- Small part of belief space only visited
- Plausible actions at every point very restricted
- Summary space: Simplified representation
🔴 Disadvantages
Predefine structure of the dialog states
Location
Price range
Type of cuisine
Limited to very narrow domain
Cannot encode all features/slots that might be useful
Neural Dialog Models
End-to-End training
- Optimize all parameters jointly
Continuous representations
- No early decision
- No propagation of errors
Challenges
- Representation of history/context
- Policy- Learning
- Interactive learning
- dIntegration of knowledge sources
Datasets
Goal oriented
bAbI task
- Synthetic data – created by templates
DSTC (Dialog State tracking challenge)
Restaurant reservation
Collected using 3 dialog managers
Annotated with dialog states
Social dialog
- Learn from human-human communication
Architecture
Memory Networks
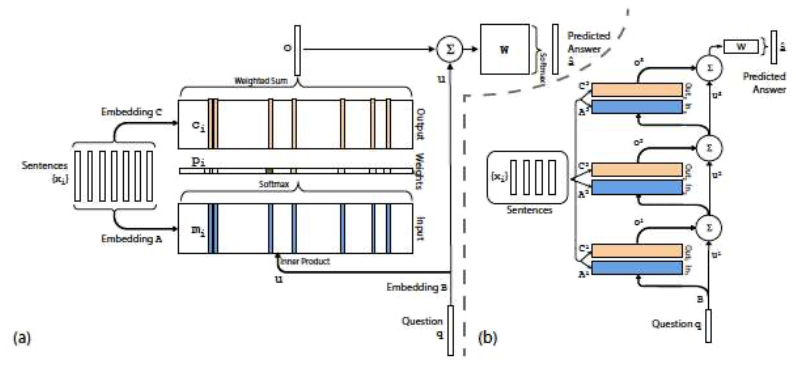
Neural network model
Writing and reading from a memory component
Store dialog history
- Learn to focus on important parts
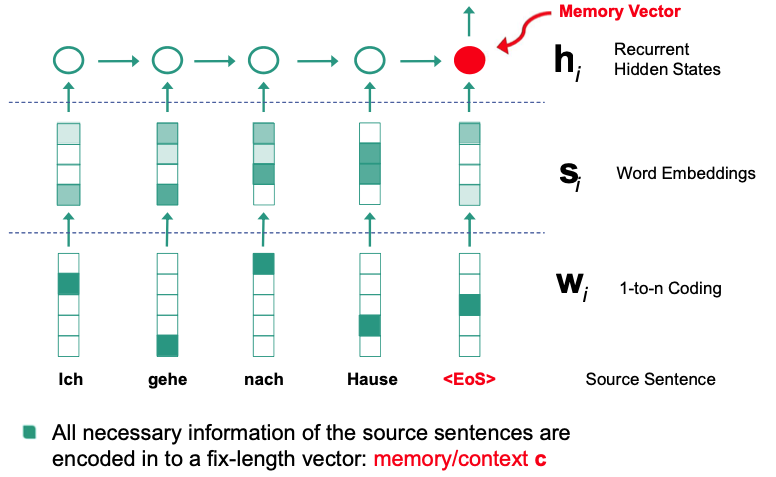
Sequence-to-Sequence Models: Encoder-Decoder
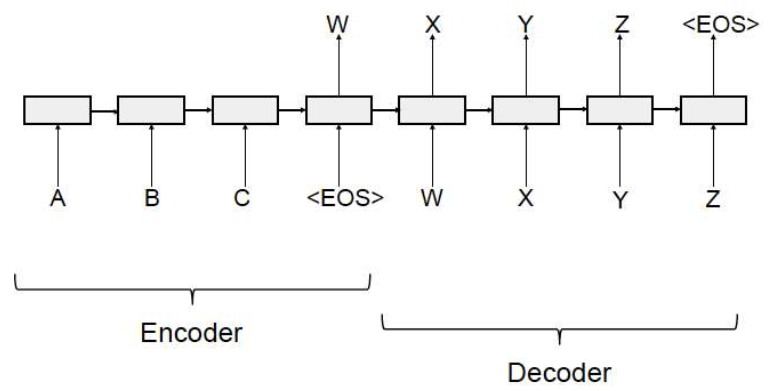
Encoder
- Read in Input
- Represent content in hidden fix dimension vector
- LSTM-based model
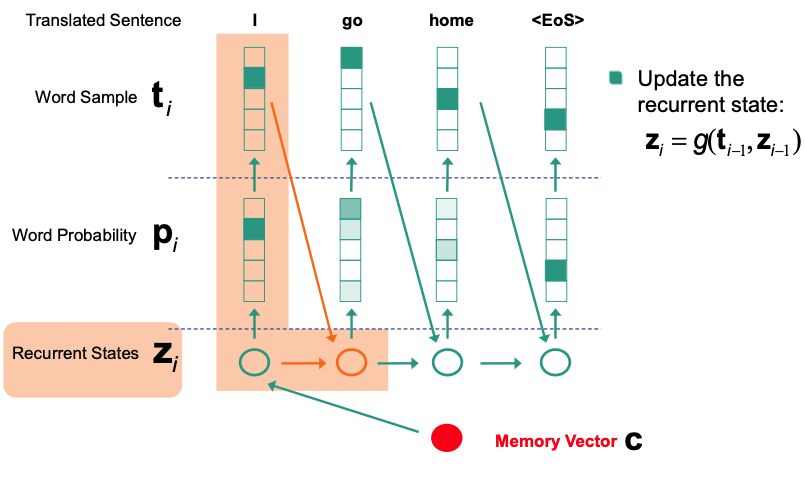
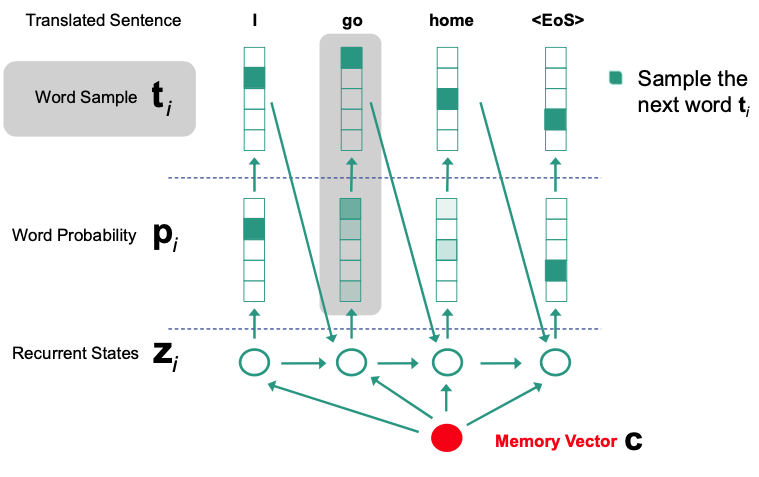
Decoder
- Generate Output
- Use fix dimension vector as input
- LSTM-based model
EOSsymbol to start outputting
Example
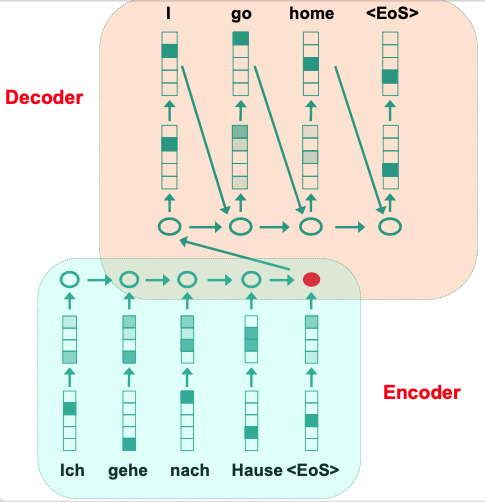
Recurrent-based Encoder-Decoder Architecture
Trained end-to-end.
Encoder
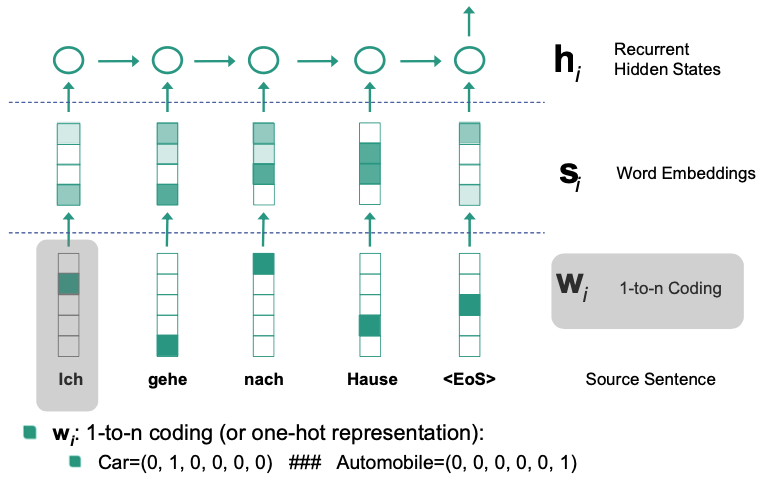
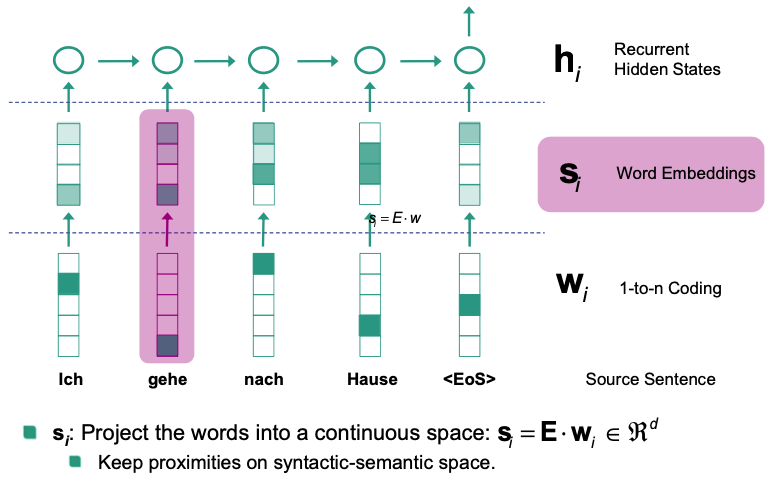
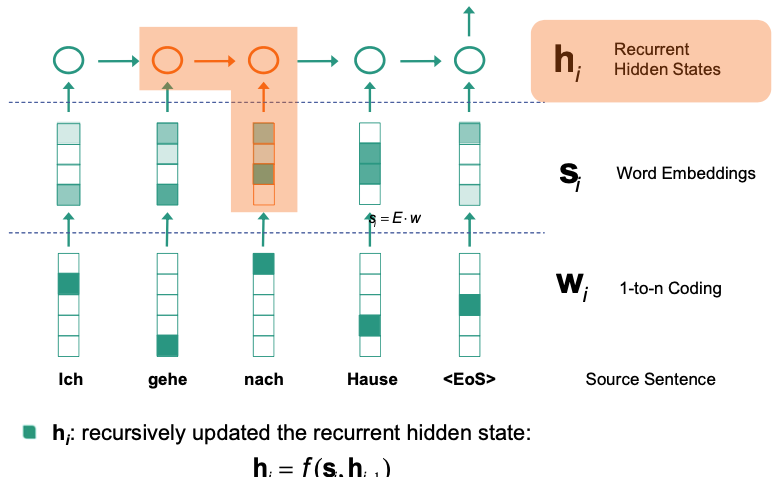
Decoder
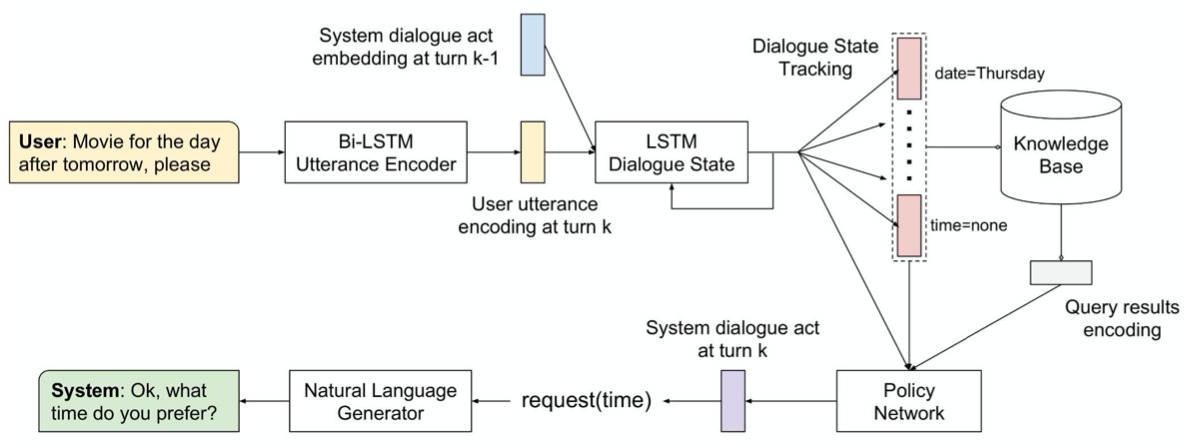
Dedicated Dialog Architecture
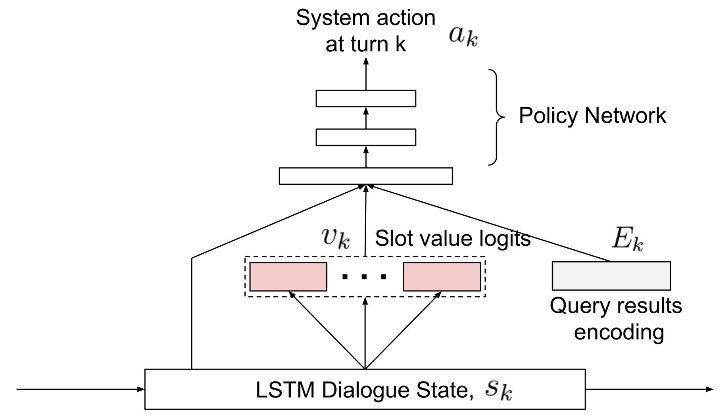
Training
Supervised learning
Supervised: Learning from corpus
Algorithm:
- Input user utterance
- Calculate system output
- Measure error
- Backpropagation error
- Update weights
Problem:
- Error lead to different dialogue state
- Compounding errors
Imitation learning
- Imitation learning
Interactive learning
Correct mistakes and demonstrate expected actions
- Algorithm: same as supervised learning
- Problem: costly
Deep reinforcement learning
Imitation learning
- Interactive learning
- Feedback only at end of the dialogue
Successful/ Failed task
Additional reward for fewer steps 👏
Challenge:
- Sampling of different actions
- Hugh action space