Language and Vision
Motivation
Human interacts with environment multimodal
Modalities
- Text
- Audio
- Vision
Other modalities can be used to disambiguate text
Jointly using different modalities
Image description
Generation
Generate description/caption of image
Verbalize the most salient aspects of the image
Typically one sentence
Example

Joint use of
- Computer vision
- Natural language processing
🔴 Challenges
- Cover any visual aspect of the image:
Objects and their attributes
Features of the scene
Interaction of objects
- Reference to objects not in the image:
- E.g. people waiting for a train
- Background knowledge necessary
- E.g. Picture of Mona Lisa
Task
Input: Image
Generate representation
Output: Text
Related to Natural language generation
Content selection
Organizing of content
Surface realization
Generation from Visual Input
Standard pipeline:
- Computer vision: Recognize
Scene
Objects
Spatial relationship
Actions
- Natural language generation
- Combine words/phrases from first step using
- Templates
- N-grams
- Grammar rules
- Combine words/phrases from first step using
- Computer vision: Recognize
Example
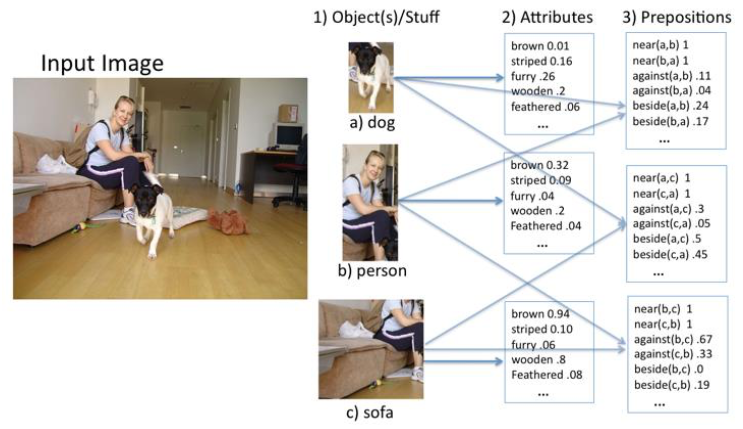
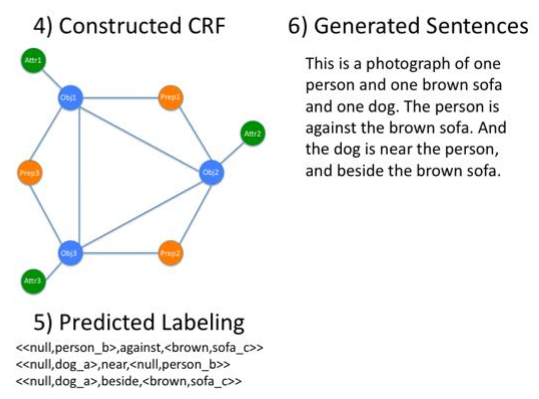
End-to-End approaches (Show, Attend, Tell)
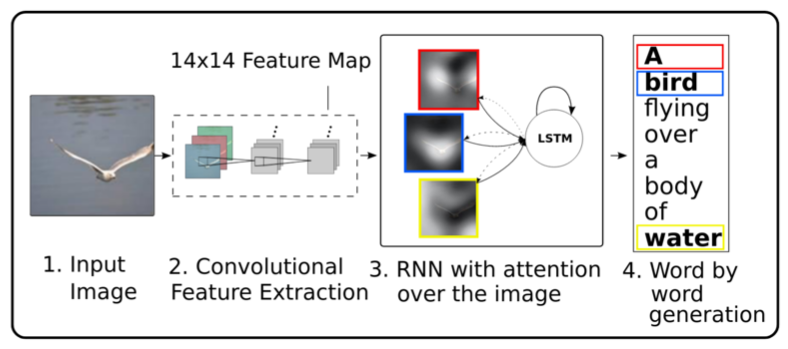
CNN Encoder of the image
LSTM-based Decoder generating the sentences
Attention mechanism to attend to different parts of the image
Examples

Retrieval
💡 Idea: Use description of similar image
Algorithm:
Extract visual feature
Retrieve most similar images using similarity function
Re-rank images
Combine retrieved descriptions
Example
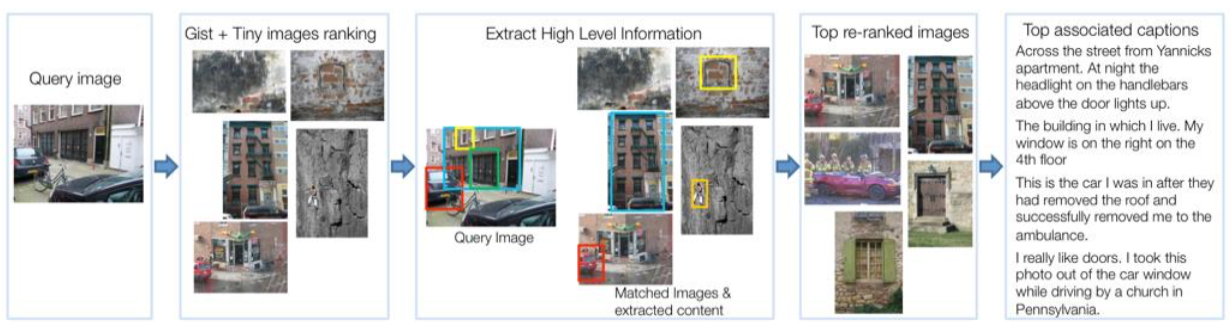
Description retrieval
Visual question answering
Given:
Image
Question related to the image
Example

Output: Answer
Most common model: Joint neural network
🔴 Challenges: Multi-step reasoning
Steps
- Locate objects (bike, window, street, basket and dogs)
- Identify concepet (sitting)
- Rule out irrelavant objects
Image model
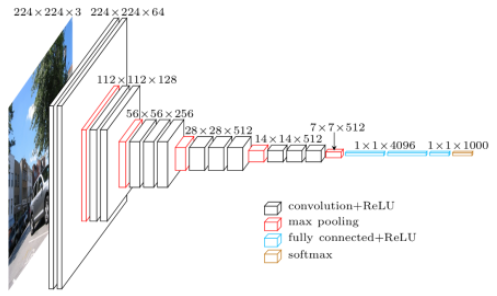
CNN:
- Often pretrained models used
- Global features: Fixed size representation of the whole image
- Local features: Representation of different regions of the image
Text model
Read question word by word
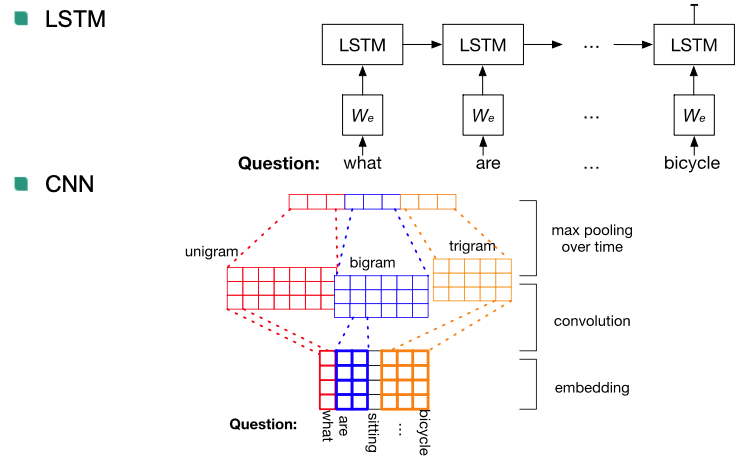
Answer generation
One word or free text
Input: Image features and text features
Output: Most probable word
Models:
- Fully connected NN
- Attention mechanism