N Gram
Language models (LMs): Model that assign probabilities to sequence of words
N-gram: a sequence of N words
E.g.: Please turn your homework …
- bigram (2-gram): two-word sequence of word
- “please turn”, “turn your”, or ”your homework”
- trigram (3-gram): three-word sequence of word
- “please turn your”, or “turn your homework”
Motivation
$P(w|h)$: probability of a word $w$ given some history $h$.
Our task is to compute $P(w|h)$.
Consider a simple example:
Suppose the history $h$ is “its water is so transparent that” and we want to know the probability that the next word is the: $P(\text {the} | \text {its water is so transparent that})$
Naive way
Use relative frequency counts (“Out of the times we saw the history $h$, how many times was it followed by the word $w$”?)
- Take a very large corpus, count the number of times we see
its water is so transparent that, and count the number of times this is followed bythe.
With a large enough corpus, such as the web, we can compute these counts and estimate the probability
- Works fine in many cases
🔴 Problems
Even the web isn’t big enough to give us good estimates in most cases.
This is because language is creative;
new sentences are created all the time,
and we won’t always be able to count entire sentences.
Similarly, if we wanted to know the joint probability of an entire sequence of words like
its water is so transparent, we could do it by asking “out of all possible sequences of five words, how many of them areits water is so transparent?”- We have to get the count of
its water is so transparentand divide by the sum of the counts of all possible five word sequences. That seems rather a lot to estimate!
- We have to get the count of
Cleverer way
Notation:
- $P(X\_i=\text{''the''})$: probability of a particular random variable $X\_i$ taking on the value “the”
- Simplification: $P(the)$
- $w\_1\dots w\_n$ or $w\_1^n$: a sequence of $n$ words
- $w\_1^{n-1}$: the string $w\_1, w\_2, \dots w\_{n-1}$
- $P(w\_1, w\_2, \dots, w\_n)$: joint probability of each word in a sequence having a particular value $P(X\_1=w\_1, X\_2=w\_2, \dots, X\_n=w\_n)$
Compute $P(w\_1, w\_2, \dots, w\_n)$: Use the chain rule of probability
$$ \begin{aligned} P\left(X\_{1} \ldots X\_{n}\right) &=P\left(X\_{1}\right) P\left(X\_{2} | X\_{1}\right) P\left(X\_{3} | X\_{1}^{2}\right) \ldots P\left(X\_{n} | X\_{1}^{n-1}\right) \\\\ &=\prod\_{k=1}^{n} P\left(X\_{k} | X\_{1}^{k-1}\right) \end{aligned} $$Apply to words:
$$ \begin{aligned} P\left(w\_{1}^{n}\right) &=P\left(w\_{1}\right) P\left(w\_{2} | w\_{1}\right) P\left(w\_{3} | w\_{1}^{2}\right) \ldots P\left(w\_{n} | w\_{1}^{n-1}\right) \\\\ &=\prod\_{k=1}^{n} P\left(w\_{k} | w\_{1}^{k-1}\right) \end{aligned} $$🔴 Problem: We don’t know any way to compute the exact probability of a word given a long sequence of preceding words $P(w\_n|w\_1^{n-1})$
- we can’t just estimate by counting the number of times every word occurs following every long string, because language is creative and any particular context might have never occurred before! 🤪
🔧 Solution: n-gram model
n-gram model
💡 Idea of n-gram model: instead of computing the probability of a word given its entire history, we can approximate the history by just the last few words.
E.g.: the bigram model, approximates the probability of a word given all the previous words $P(w\_n|w\_1^{n-1})$ by using only the conditional probability of the PRECEDING word $P(w\_n|w\_{n-1})$:
$$ P\left(w\_{n} | w\_{1}^{n-1}\right) \approx P\left(w\_{n} | w\_{n-1}\right) $$- E.g.: $P(\text { the } | \text { Walden Pond's water is so transparent that }) \approx P(\text{the}|\text{that})$
👆 The assumption that the probability of a word depends only on the previous word is called a Markov assumption. Markov models are the class of probabilistic models that assume we can predict the probability of some future unit without looking too far into the past.
Generalize the bigram (which looks one word into the past) to the trigram (which looks two words into the past) and thus to the n-gram (which looks $n − 1$ words into the past):
$$ P\left(w\_{n} | w\_{1}^{n-1}\right) \approx P\left(w\_{n} | w\_{n-N+1}^{n-1}\right) $$Estimate n-gram probabilities
Intuitive way: Maximum Likelihood Estimation (MLE)
- Get counts from a corpus
- Normalize the counts so that they lie between 0 and 1
Bigram
Let’s start from bigram. To compute a particular bigram probability of a word $y$ given a previous word $x$, we’ll compute the count of the bigram $C(xy)$ and normalize by the sum of all the bigrams that share the same first word $x$
$$ P\left(w\_{n} | w\_{n-1}\right)=\frac{C\left(w\_{n-1} w\_{n}\right)}{\sum\_{w} C\left(w\_{n-1} w\right)} $$We can simplify this equation, since the sum of all bigram counts that start with a given word $w\_{n-1}$ must be equal to the unigram count for that word $w\_{n-1}$
$$ P\left(w\_{n} | w\_{n-1}\right)=\frac{C\left(w\_{n-1} w\_{n}\right)}{C\left(w\_{n-1}\right)} $$Example:
Given a mini-corpus of three sentences
<s> I am Sam </s>
<s> Sam I am </s>
<s> I do not like green eggs and ham </s>
- We need to augment each sentence with a special symbol
<s>at the beginning of the sentence, to give us the bigram context of the first word.
The calculations for some of the bigram probabilities from this corpus:
$$ \begin{array}{lll} P(\mathrm{I} |<\mathrm{s}>)=\frac{2}{3}=0.67 & P(\mathrm{Sam} |<\mathrm{s}>)=\frac{1}{3}=0.33 & P(\mathrm{am} | \mathrm{I})=\frac{2}{3}=0.67 \\\\ P(| \mathrm{Sam})=\frac{1}{2}=0.5 & P(\mathrm{Sam} | \mathrm{am})=\frac{1}{2}=0.5 & P(\mathrm{do} | \mathrm{I})=\frac{1}{3}=0.33 \end{array} $$N-gram
For the general case of MLE n-gram parameter estimation:
$$ P\left(w\_{n} | w\_{n-N+1}^{n-1}\right)=\frac{C\left(w\_{n-N+1}^{n-1} w\_{n}\right)}{C\left(w\_{n-N+1}^{n-1}\right)} $$It estimates the n-gram probability by dividing the observed frequency of a particular sequence by the observed frequency of a prefix. This ratio is called a relative frequency.
Example:
Use data from the now-defunct Berkeley Restaurant Project.
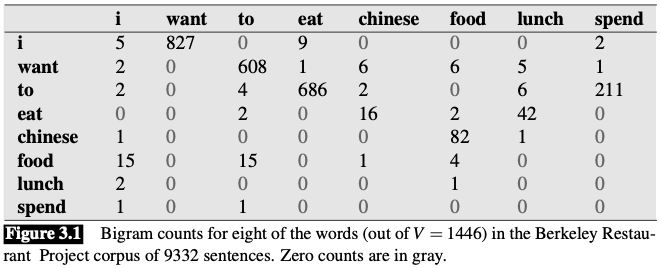
👆 This figure shows the bigram counts from a piece of a bigram grammar.
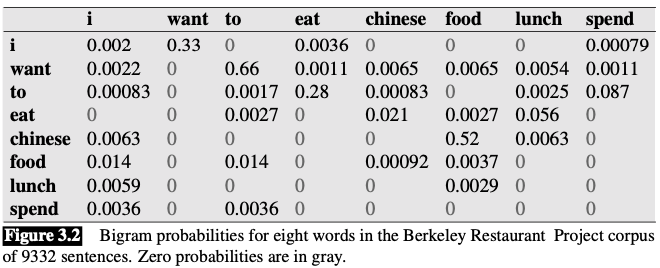
👆 This figure shows the bigram probabilities after normalization (dividing each cell in figure above (Figure 3.1) by the appropriate unigram for its row, taken from the following set of unigram probabilities)

Other useful probabilities:
$$ \begin{array}{ll} P(\mathrm{i} |<\mathrm{s}>)=0.25 & P(\text { english } | \text { want })=0.0011 \\\\ P(\text { food } | \text { english })=0.5 & P(| \text { food })=0.68 \end{array} $$Now we can compute the probability of sentences like I want English food by simply multiplying the appropriate bigram probabilities together:
$$ \begin{aligned} &P(\langle s\rangle\text { i want english food}\langle / s\rangle) \\\\ =\quad & P(\mathrm{i} |<\mathrm{s}>) \cdot P(\text { want } | \mathrm{i}) \cdot P(\text { english } | \text { want }) \cdot P(\text { food } | \text { english }) \cdot P(| \text { food }) \\\\ =\quad & .25 \times .33 \times .0011 \times 0.5 \times 0.68 \\\\ =\quad & .000031 \end{aligned} $$Pratical issues
In practice it’s more common to use trigram models, which condition on the previous two words rather than the previous word, or 4-gram or even 5-gram models, when there is sufficient training data.
- Note that for these larger n- grams, we’ll need to assume extra context for the contexts to the left and right of the sentence end. For example, to compute trigram probabilities at the very beginning of the sentence, we can use two pseudo-words for the first trigram (i.e., $P(I|\text{\
- Note that for these larger n- grams, we’ll need to assume extra context for the contexts to the left and right of the sentence end. For example, to compute trigram probabilities at the very beginning of the sentence, we can use two pseudo-words for the first trigram (i.e., $P(I|\text{\
We always represent and compute language model probabilities in log format as log probabilities.
Multiplying enough n-grams together would easily result in numerical underflow 🤪 (Since probability $\in (0, 1)$)
Adding in log space is equivalent to multiplying in linear space, so we combine log probabilities by adding them.