Optimizing for Sentiment Analysis
While standard naive Bayes text classification can work well for sentiment analysis, some small changes are generally employed that improve performance. 💪
Binary multinomial naive Bayes (binary NB)
First, for sentiment classification and a number of other text classification tasks, whether a word occurs or not seems to matter more than its frequency.
Thus it often improves performance to clip the word counts in each document at 1.
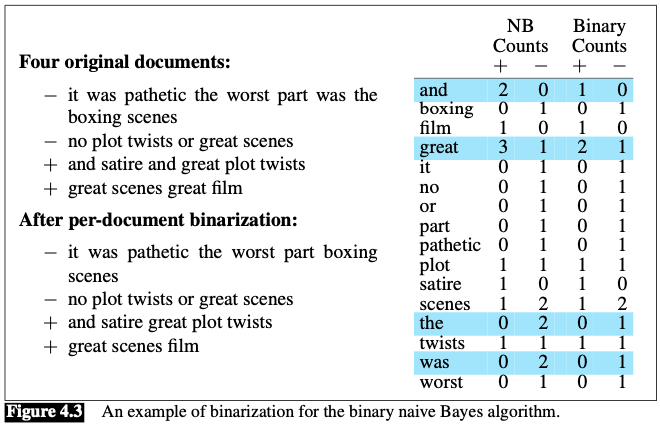
Example:
- The example is worked without add-1 smoothing to make the differences clearer.
- Note that the results counts need not be 1; the word great has a count of 2 even for Binary NB, because it appears in multiple documents (in both positive and negative class).
Deal with negation
During text normalization, prepend the prefix NOT_ to every word after a token of logical negation (n’t, not, no, never) until the next punc- tuation mark.
Example:

Deal with insufficient labeled training data
Derive the positive and negative word features from sentiment lexicons, lists of words that are pre-annotated with positive or negative sentiment.
Popular lexicons:
- General Inquirer
- LIWC
- opinion lexicon
- MPQA Subjectivity Lexicon