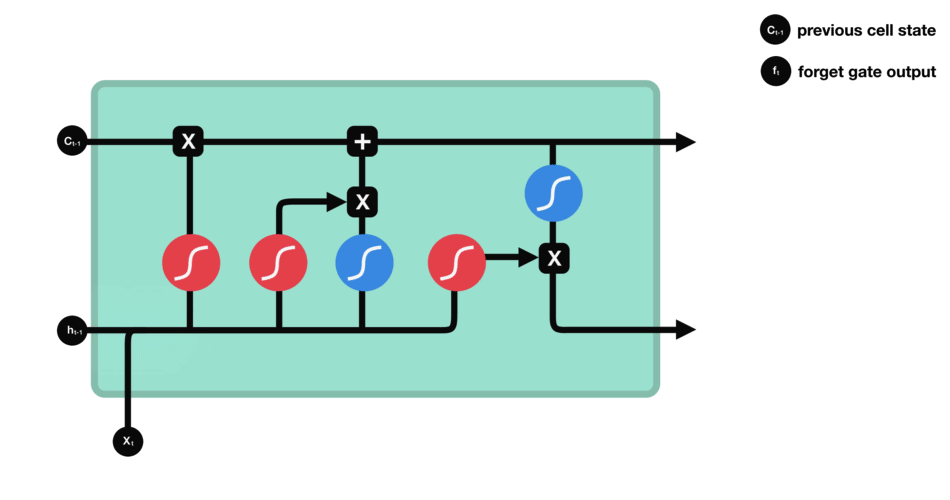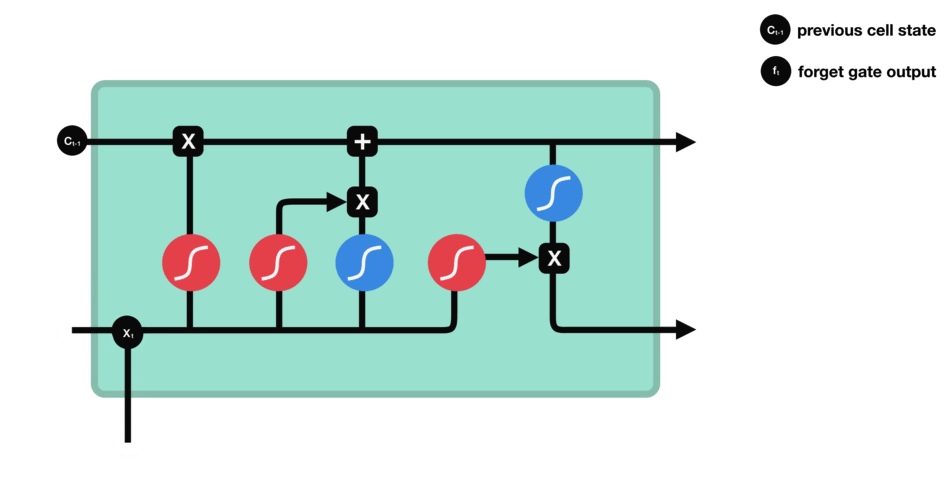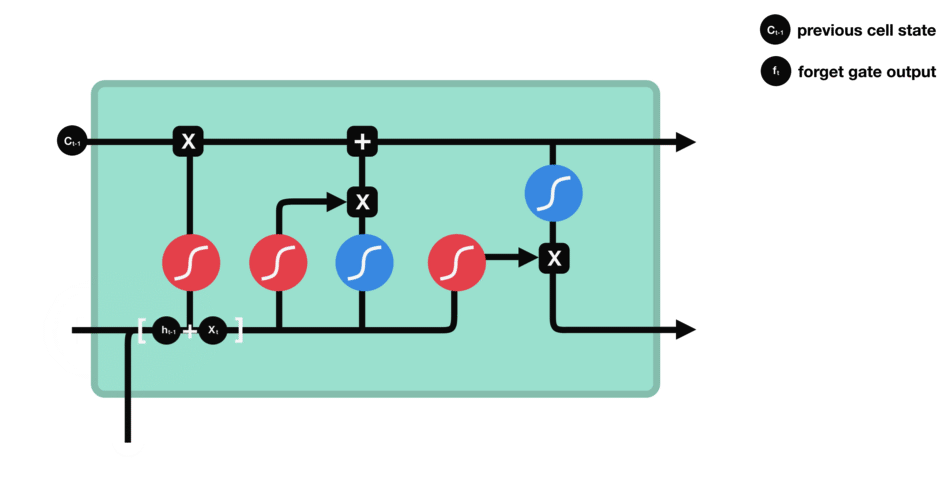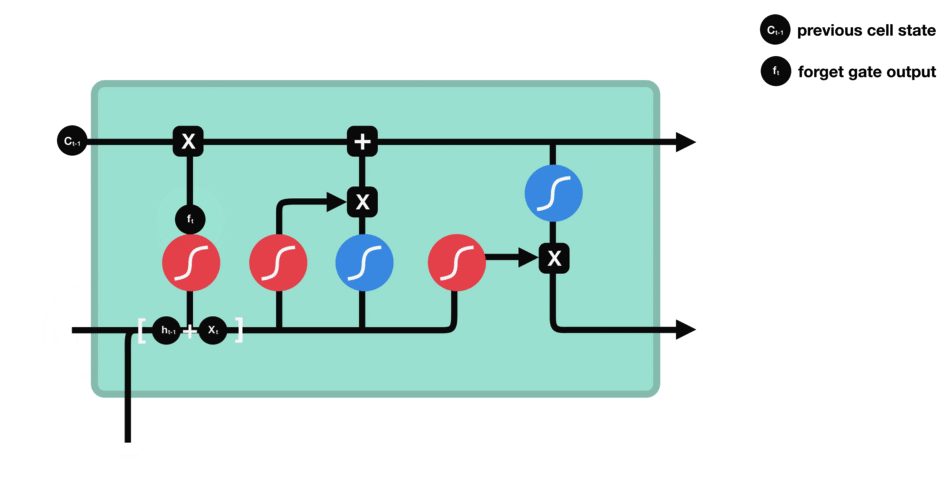
LSTM Summary
Problem of Vanilla RNN
Short-term memory
If a sequence is long enough, they’ll have a hard time carrying information from earlier time steps to later ones. So if you are trying to process a paragraph of text to do predictions, RNN’s may leave out important information from the beginning.
Vanishing gradient problem
The gradient shrinks as it back propagates through time. If a gradient value becomes extremely small, it doesn’t contribute too much learning.
In recurrent neural networks, layers that get a small gradient update stops learning. Those are usually the earlier layers. So because these layers don’t learn, RNN’s can forget what it seen in longer sequences, thus having a short-term memory.
Solution: Long Short Term Memory (LSTM)!
Intuition
Let’s say you’re looking at reviews online to determine if you want to buy Life cereal . You’ll first read the review then determine if someone thought it was good or if it was bad.
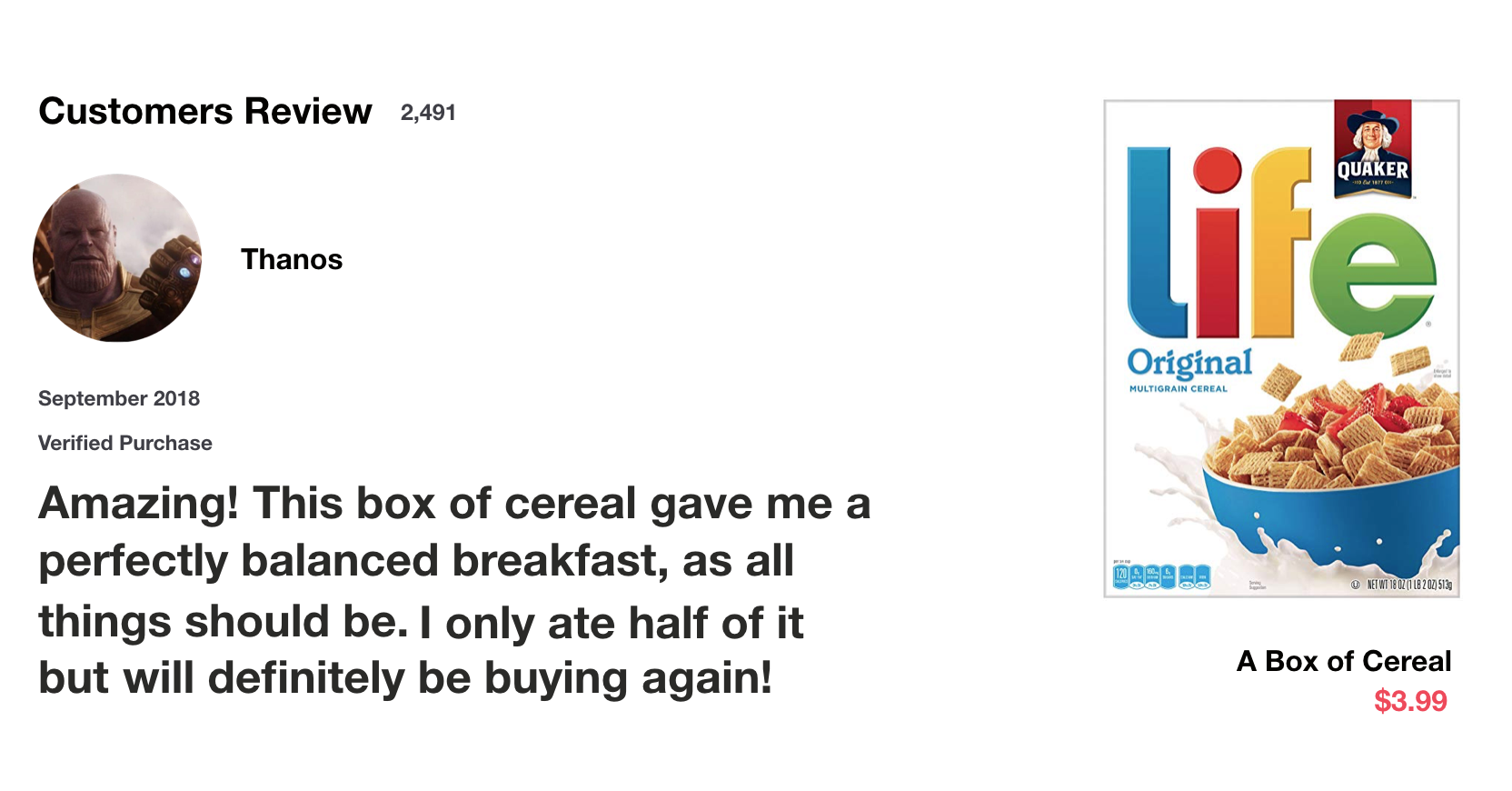
When you read the review, your brain subconsciously only remembers important keywords. You pick up words like “amazing” and “perfectly balanced breakfast”. You don’t care much for words like “this”, “gave“, “all”, “should”, etc. If a friend asks you the next day what the review said, you probably wouldn’t remember it word for word. You might remember the main points though like “will definitely be buying again”.

And that is essentially what an LSTM does. It can learn to keep only relevant information to make predictions, and forget non relevant data.
Review of vanilla RNN
LSTM is explicitly designed to avoid the long-term dependency problem. They have internal mechanisms called gates that can regulate the flow of information. These gates can learn which data in a sequence is important to keep or throw away. By doing that, it can pass relevant information down the long chain of sequences to make predictions.
In order to achieve a solid understanding of LSTM, let’s start from the standard (vanilla) RNN.
All recurrent neural networks have the form of a chain of repeating modules of neural network. In standard RNNs, this repeating module will have a very simple structure, such as a single tanh layer.
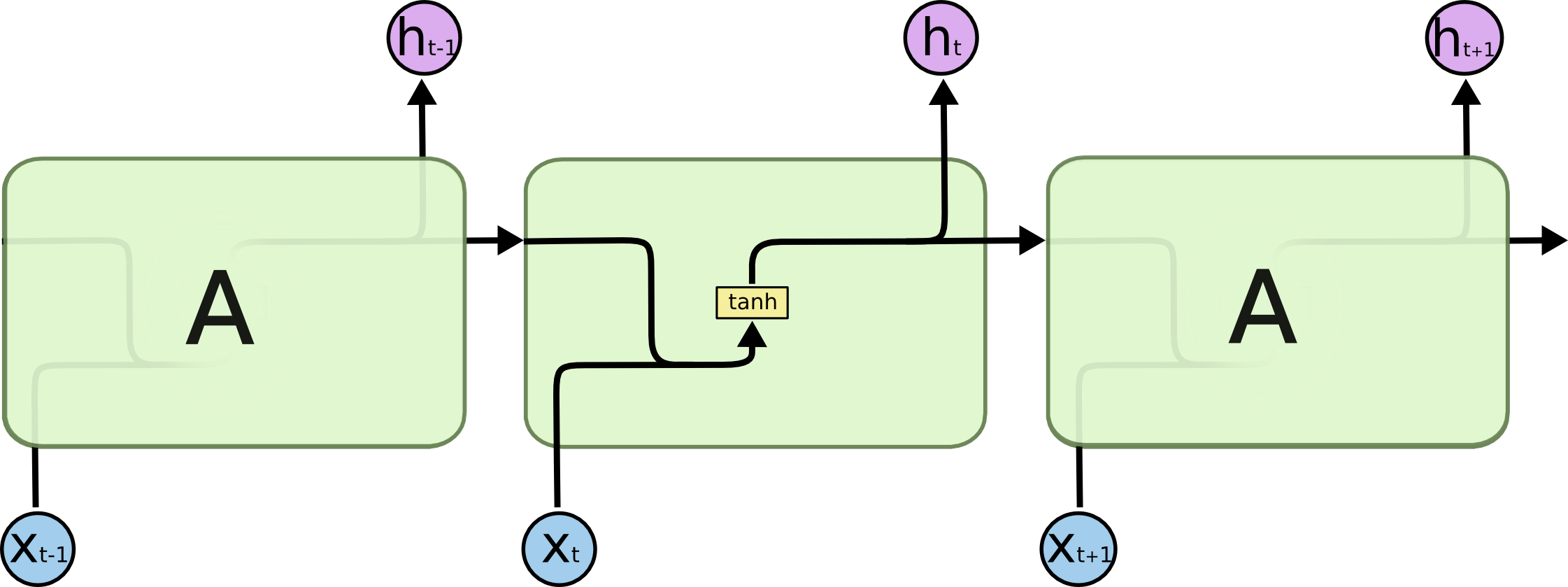
An RNN works like this
- First words get transformed into machine-readable vectors.
- Then the RNN processes the sequence of vectors one by one.
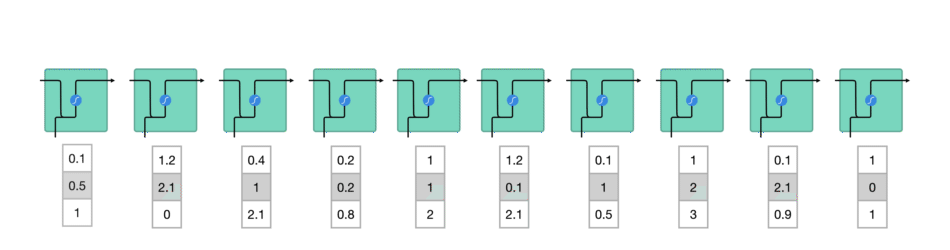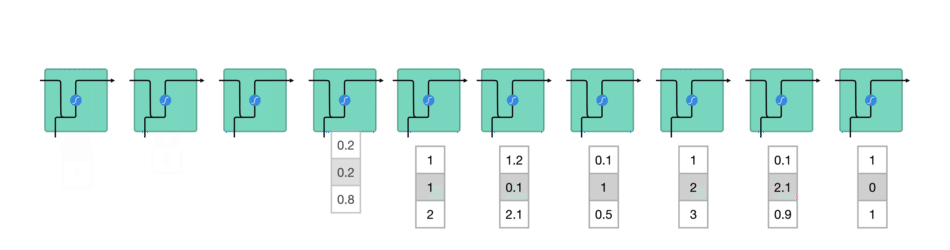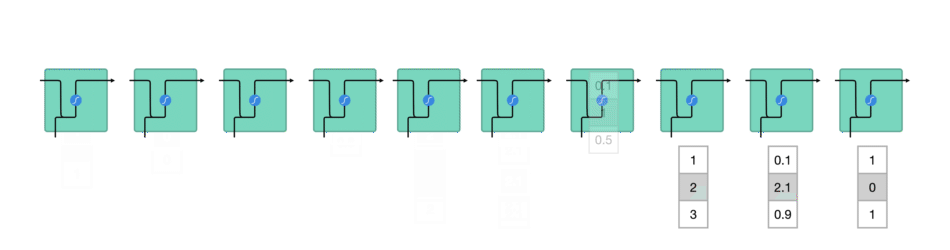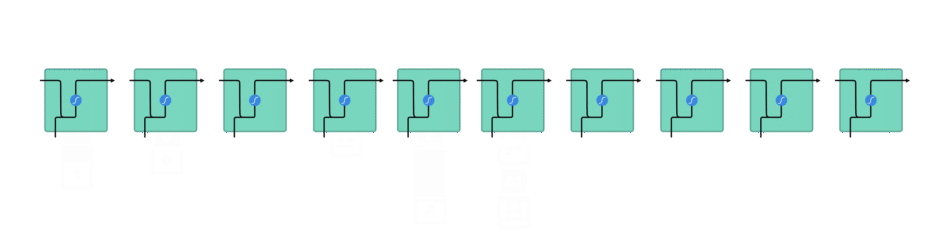
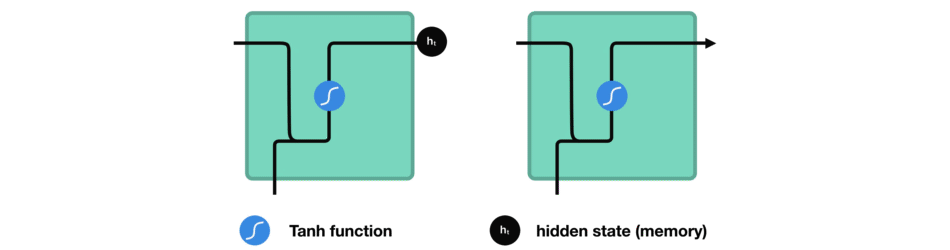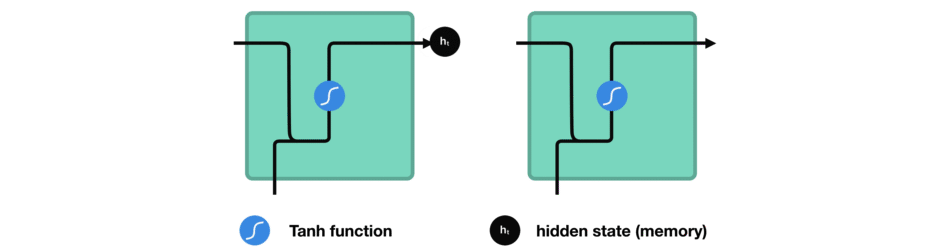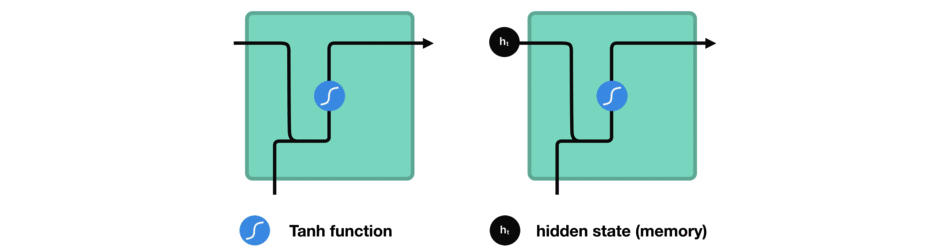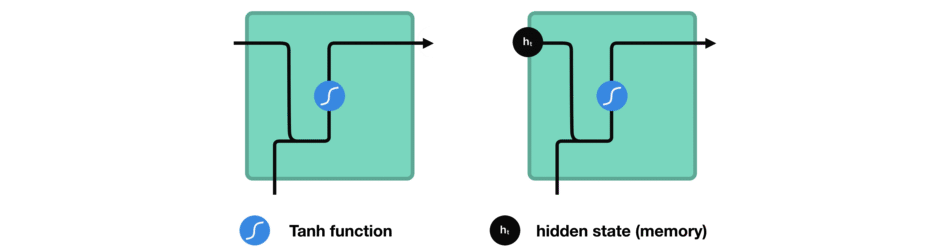
While processing, it passes the previous hidden state to the next step of the sequence. The hidden state acts as the neural networks memory. It holds information on previous data the network has seen before.
Calculate the hidden state in each cell:
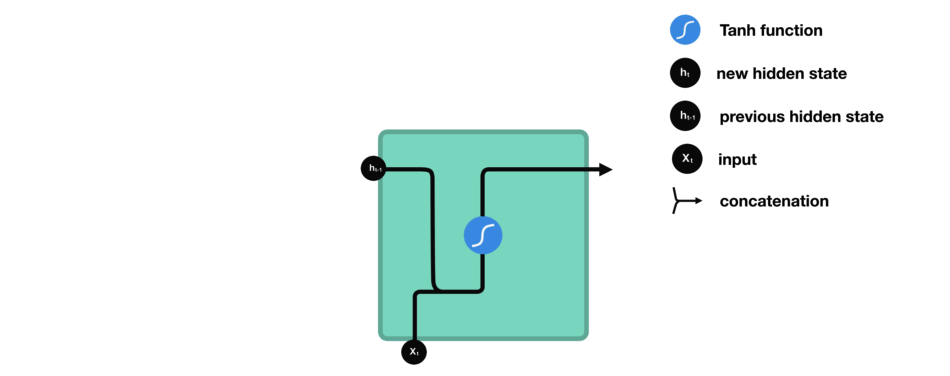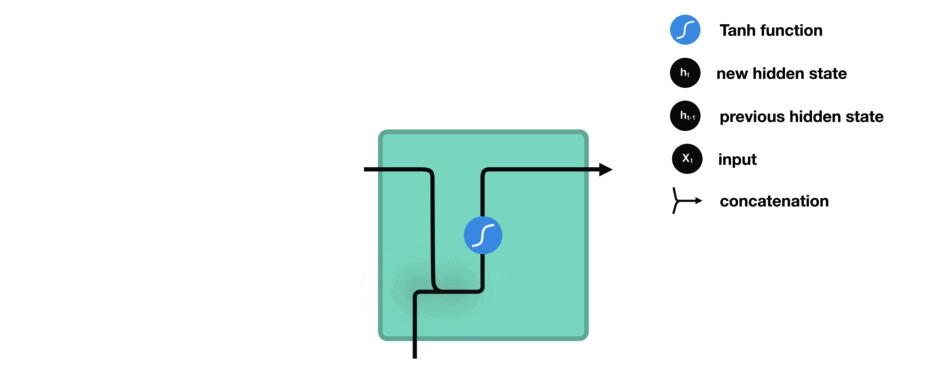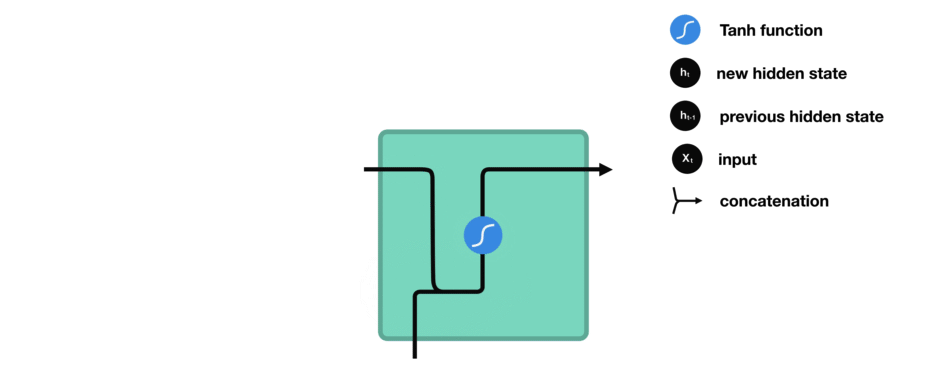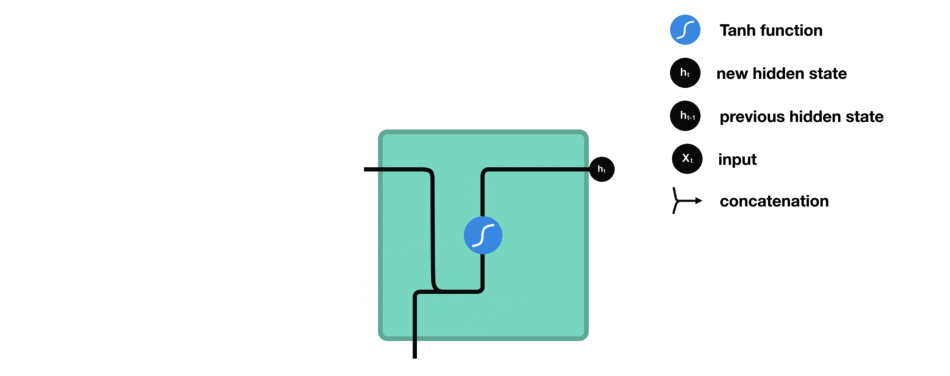
- The input and previous hidden state are combined to form a vector. (That vector now has information on the current input and previous inputs)
- The vector goes through the tanh activation, and the output is the new hidden state, or the memory of the network.
Tanh activation
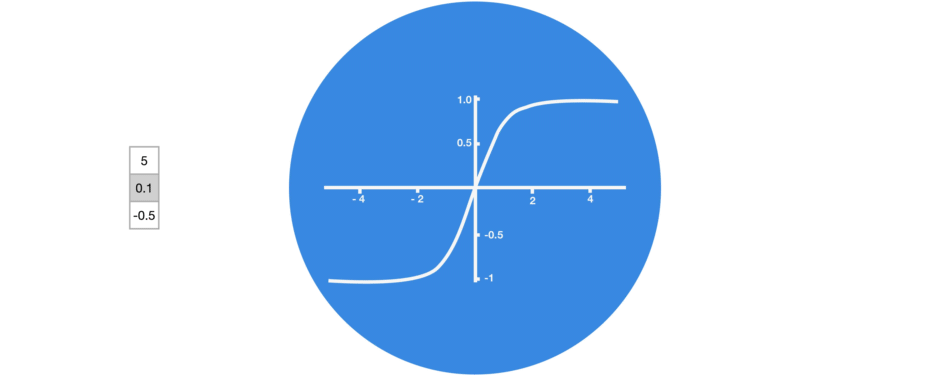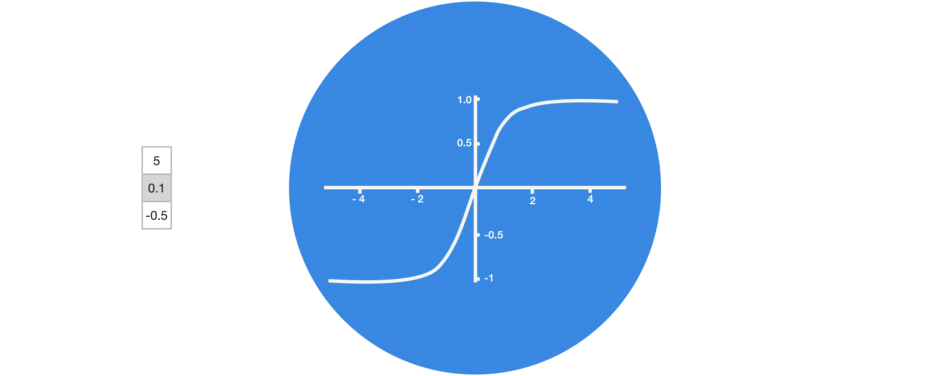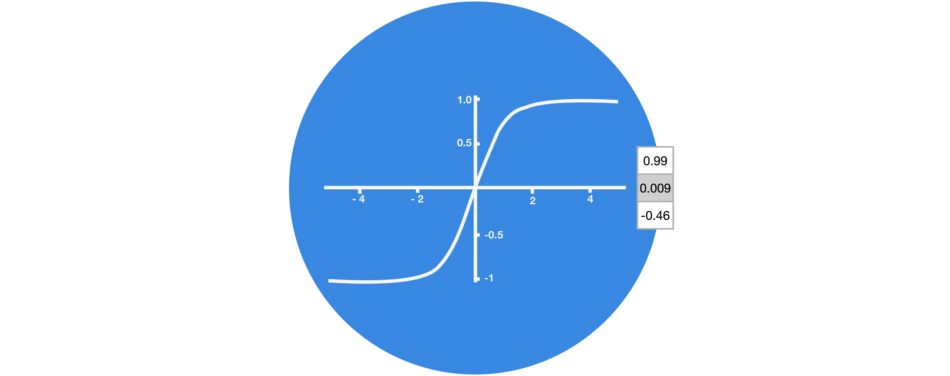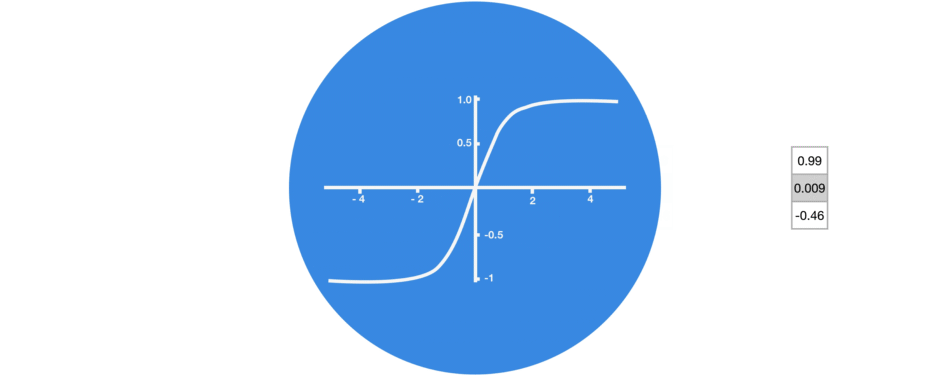
The tanh function squishes values to always be between -1 and 1. Therefore it is used to help regulating the values flowing through the network.

vector transformations with tanh
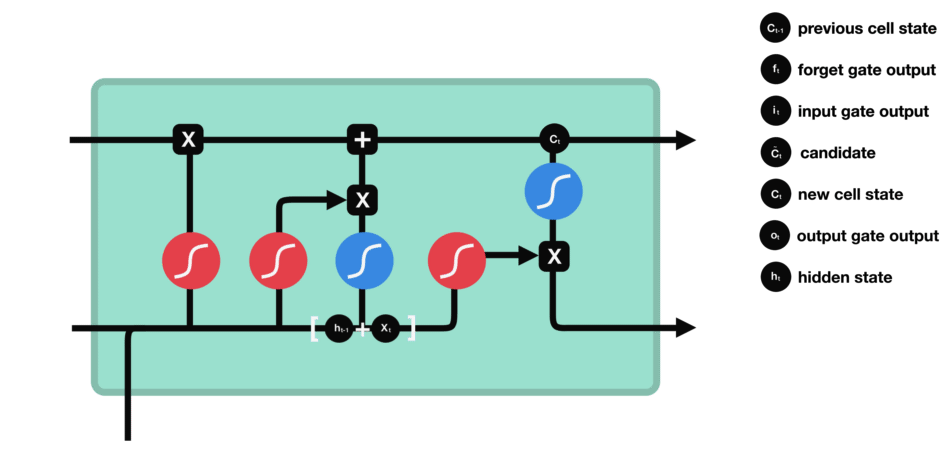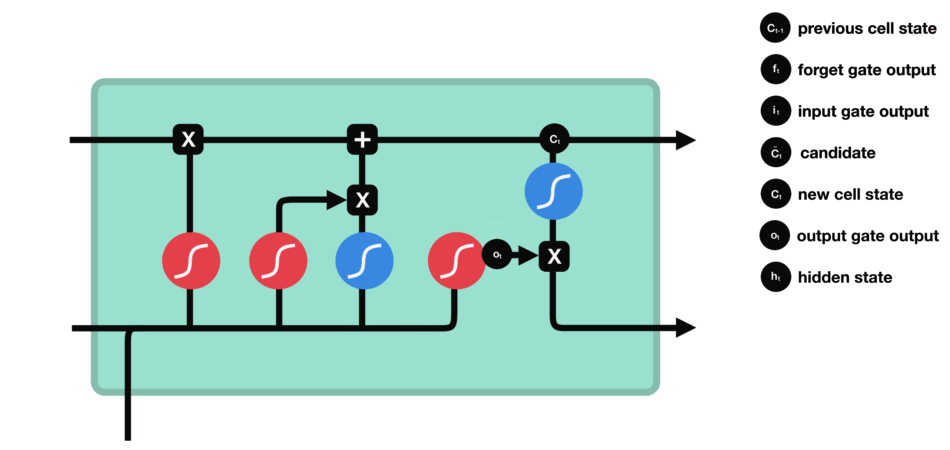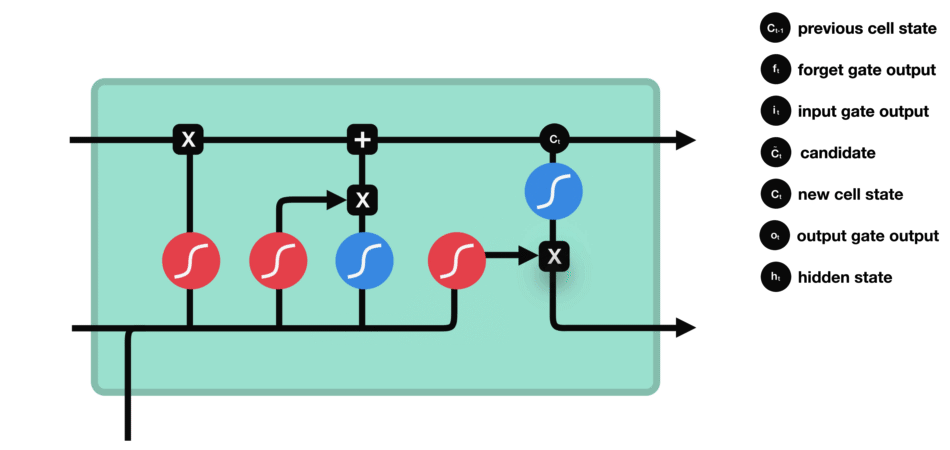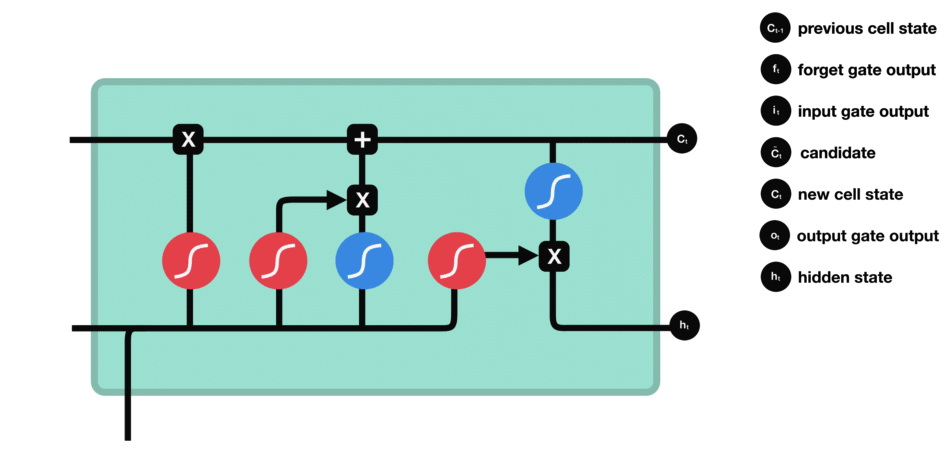
LSTM
LSTMs also have this chain like structure, but the repeating module has a different structure. Instead of having a single neural network layer, there are four, interacting in a very special way.
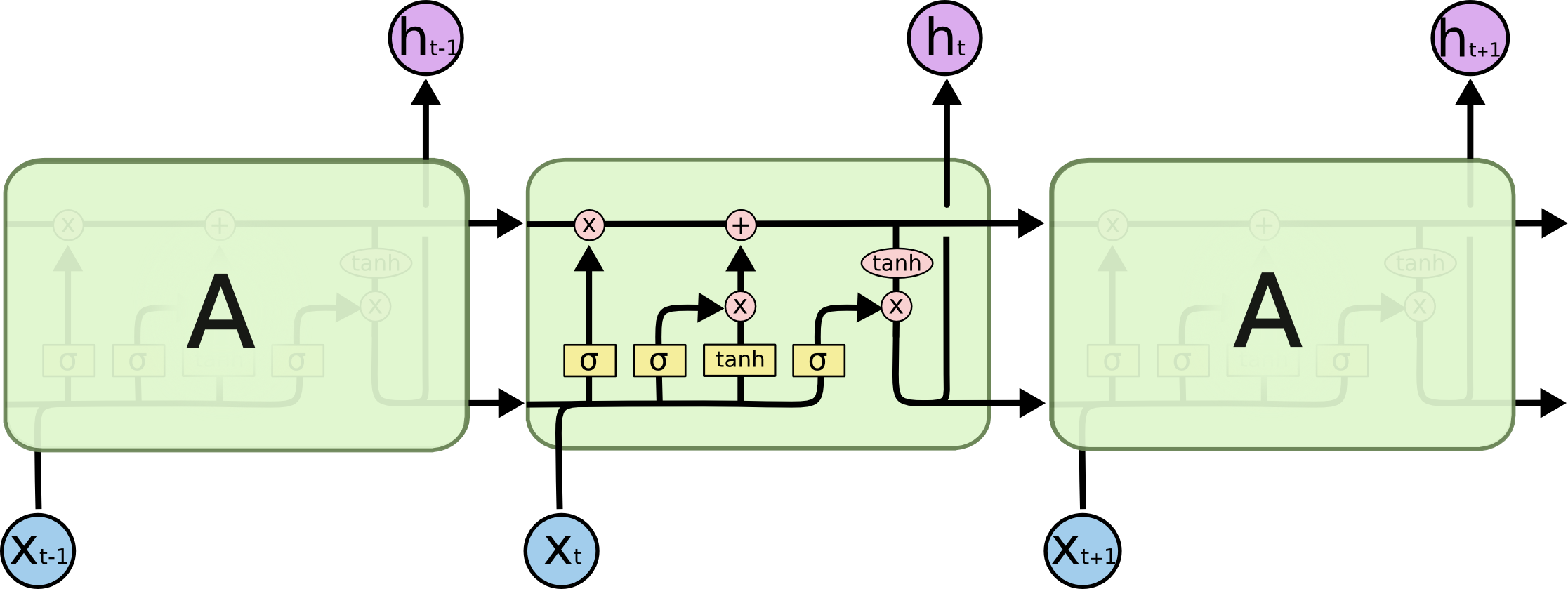

Core Idea
Cell state
Cell state is the horizontal line running through the top of the diagram.
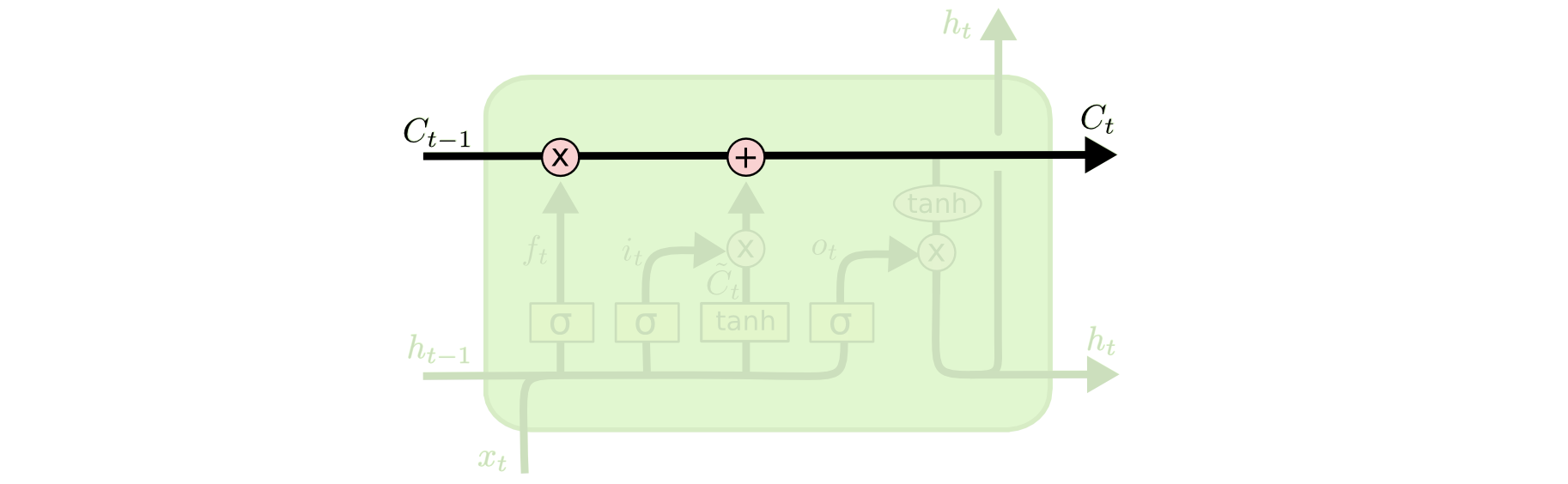
- Act as a transport highway that transfers relative information all the way down the sequence chain.
- Think of it as the “memory” of the network
- In theory, it an carry relevant information throughout the processing of the sequence.
- Even information from the earlier time steps can thus make it’s way to later time steps, reducing the effects of short-term memory 👏
Gates
The LSTM has the ability to remove or add information to the cell state, carefully regulated by structures called gates.
Gates are
- a way to optionally let information through
- composed out of a sigmoid neural net layer and a pointwise multiplication operation.
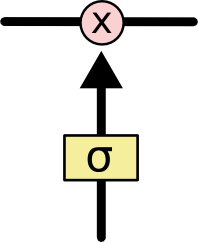
Why sigmoid?
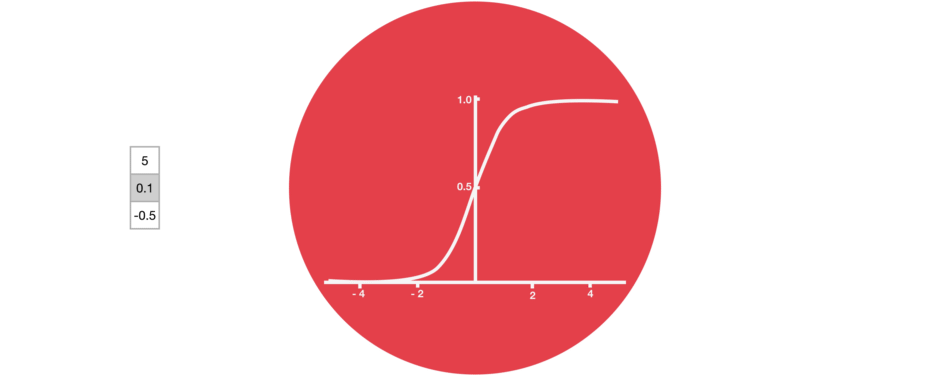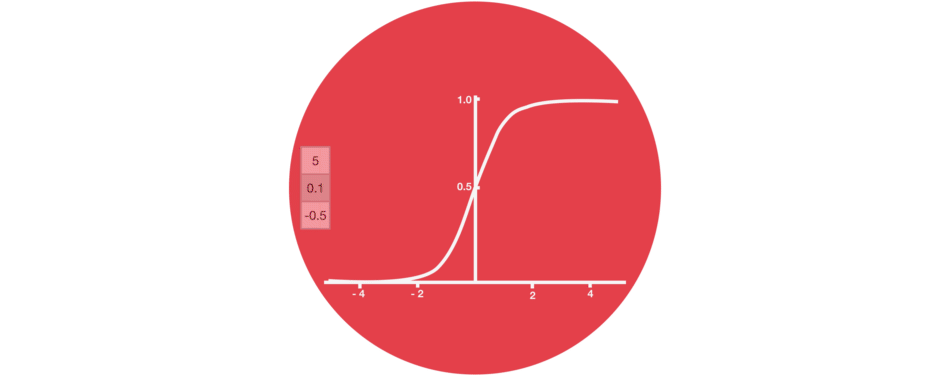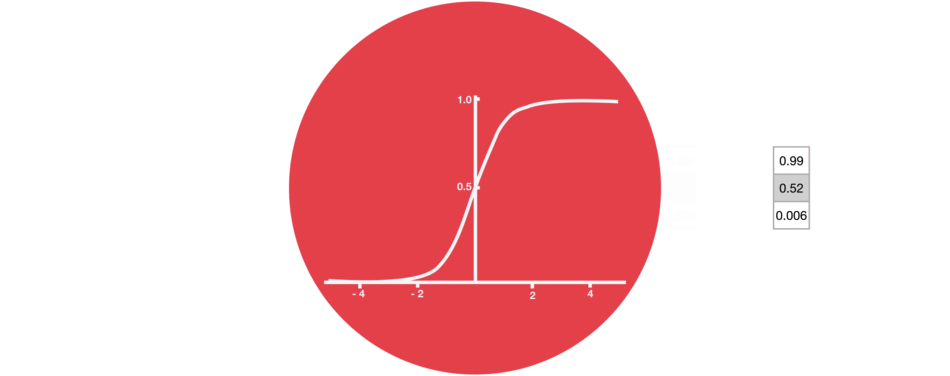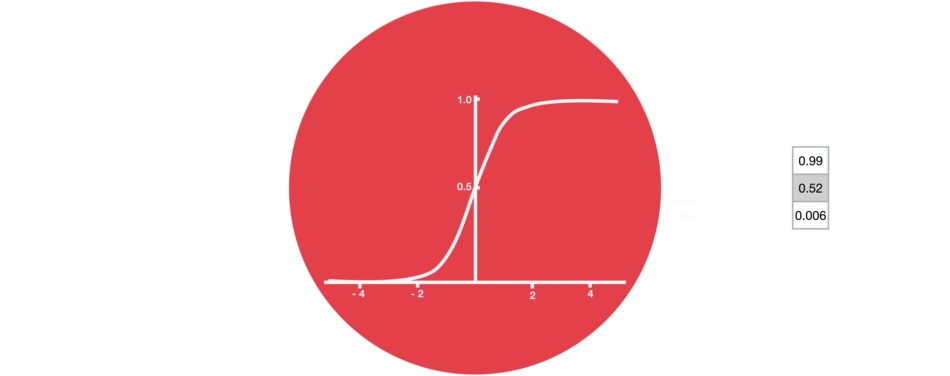
Output of sigmoid layer is between 0 and 1
The sigmoid layer squishes values between 0 and 1, describing how much of each component should be let through.
- 0: “let nothing through”, “forgotten”
- 1: “let everything through”, “kept”
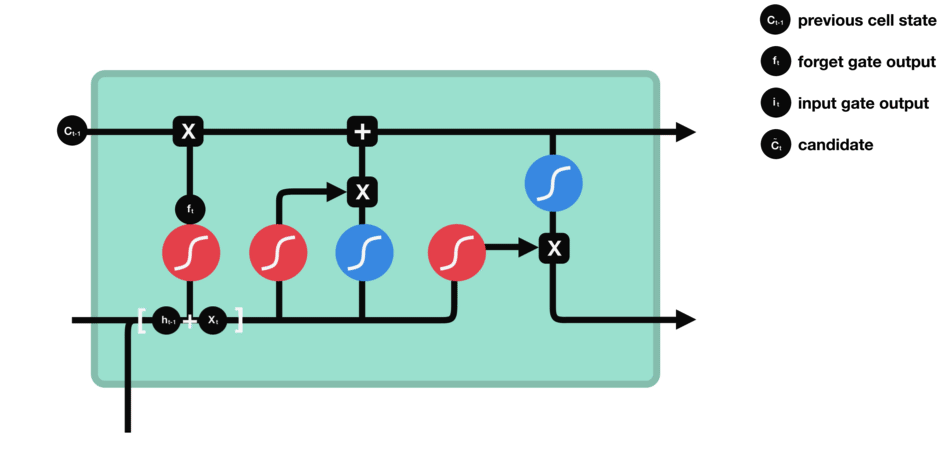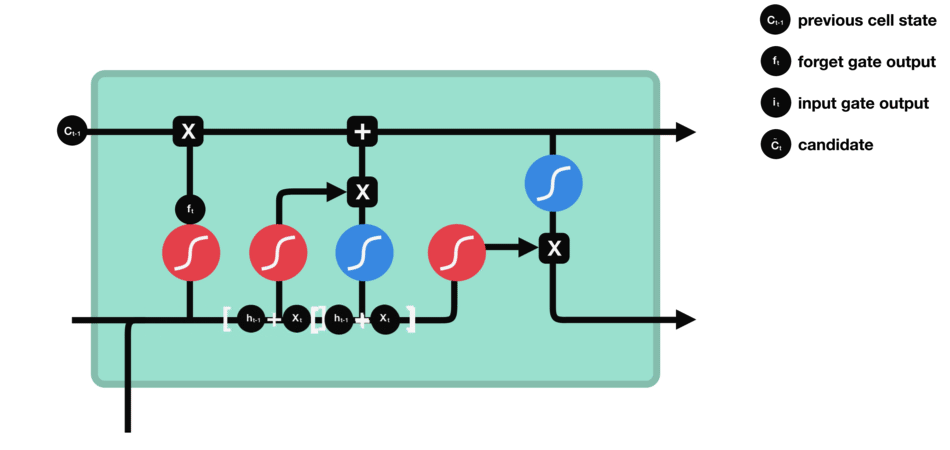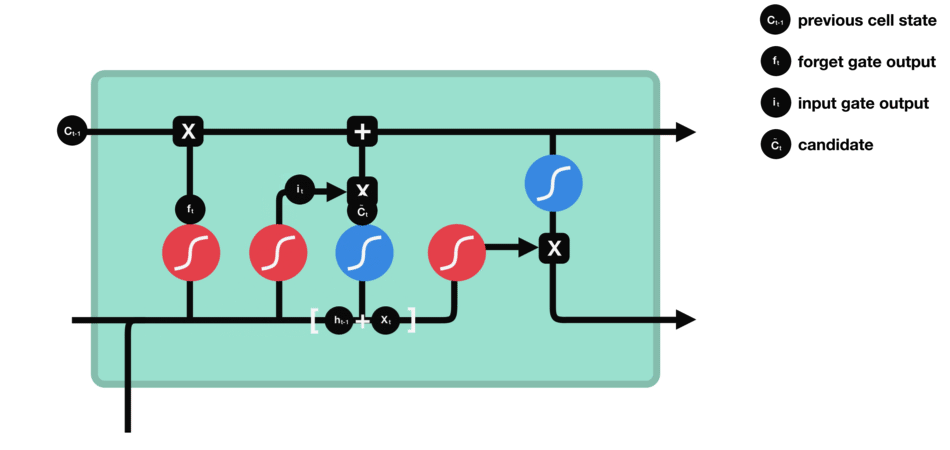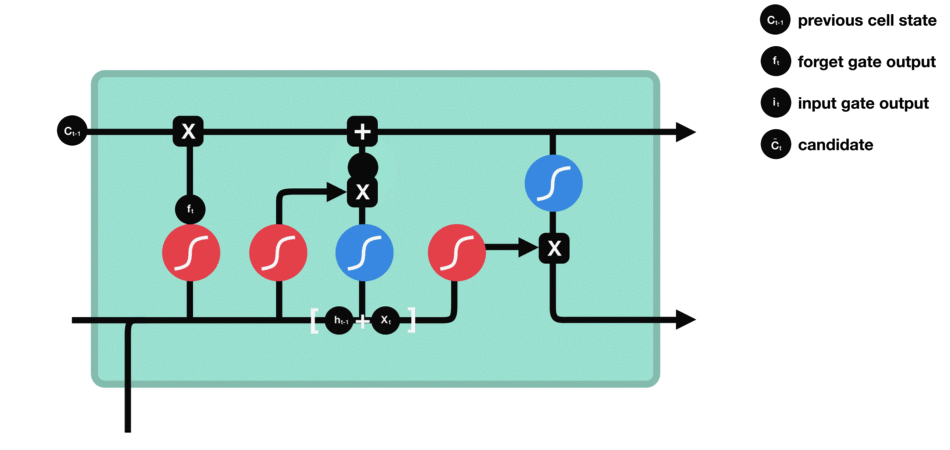
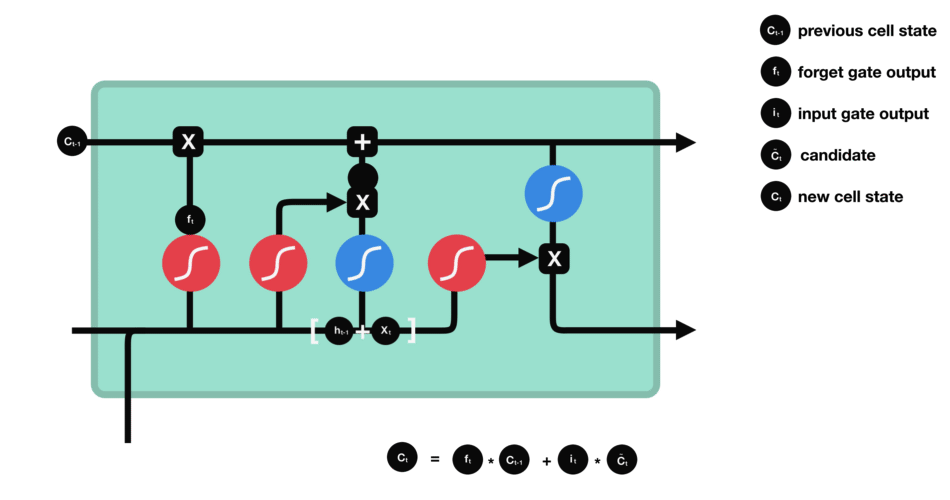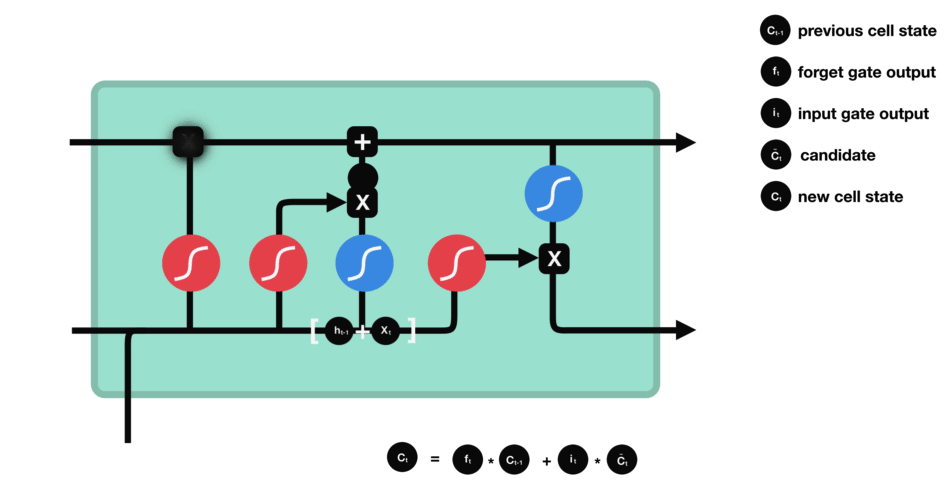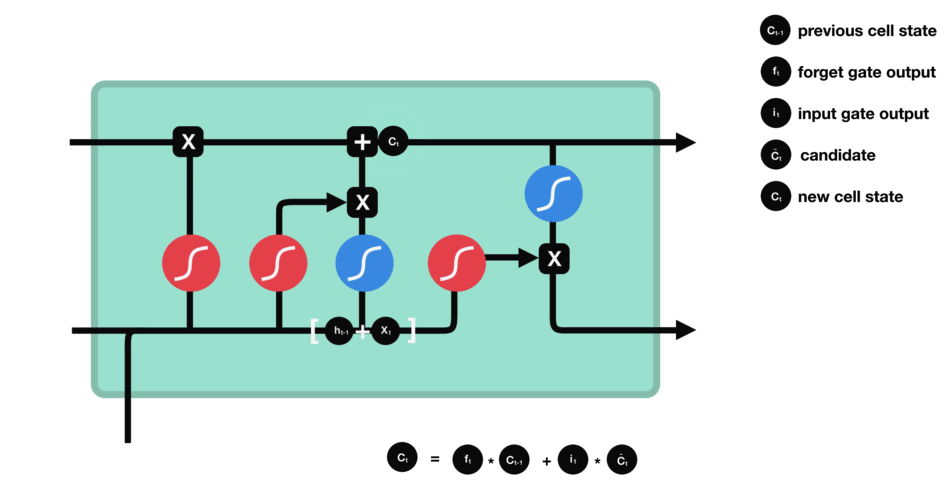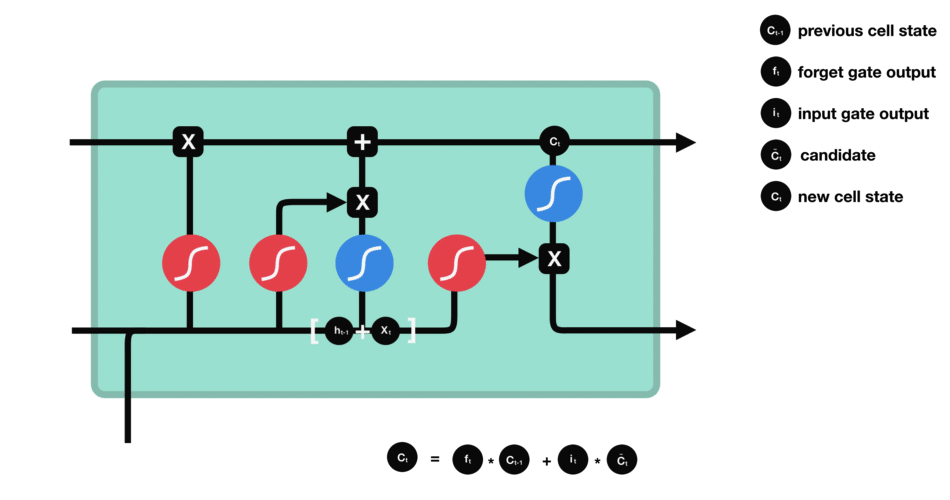
Forget gate
The first step in LSTM is to decide what information we’re going to throw away from the cell state. This decision is made by a sigmoid layer called the “forget gate layer.”
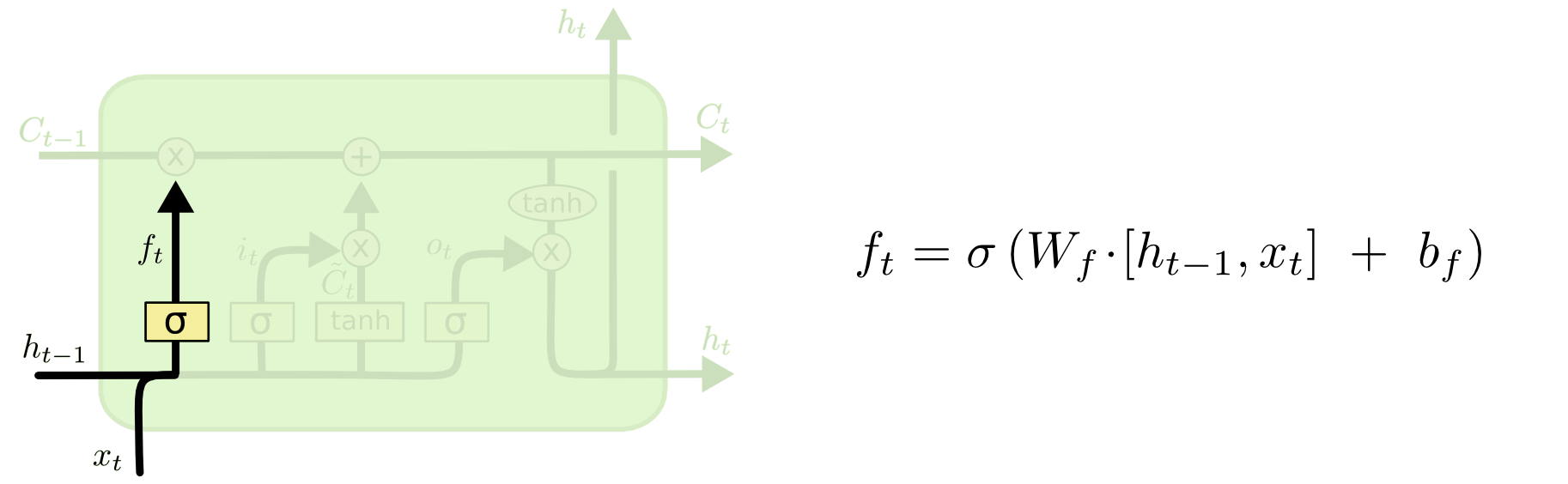
It looks at
- $h\_{t−1}$: previous hidden state, and
- $x\_t$: information from the current input
and outputs a number between $0$ and $1$ for each number in the cell state $C\_{t−1}$.
- Value closer to $1$ means to keep
- Value closer to $0$ means to forget
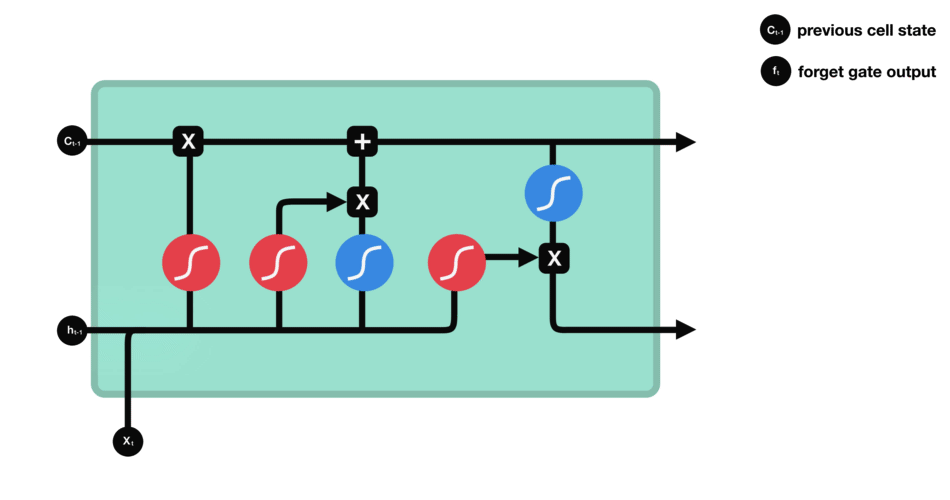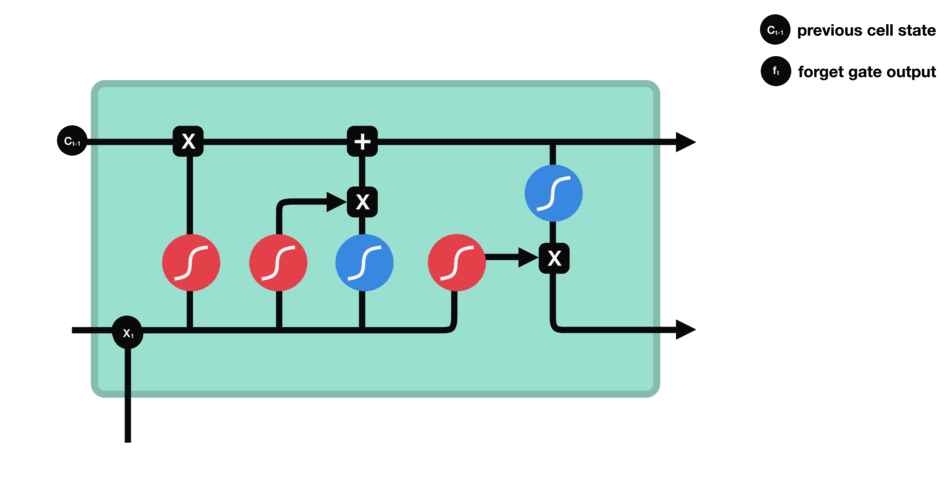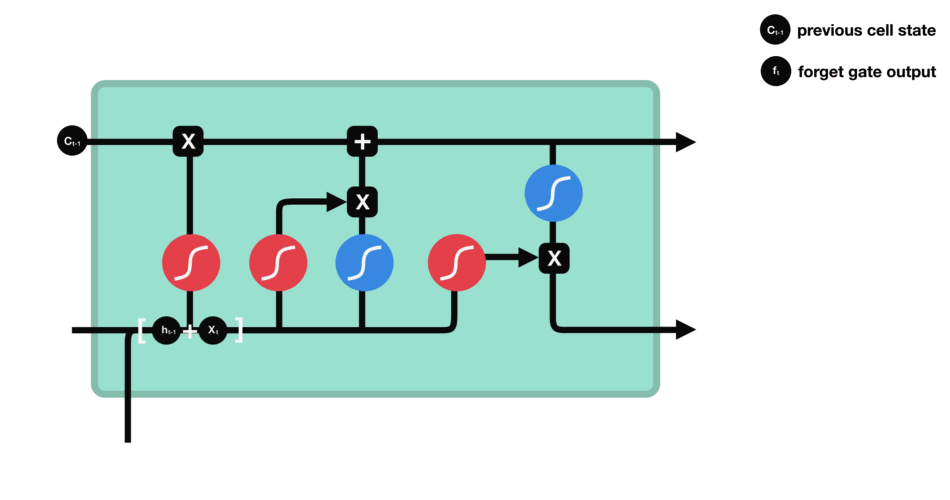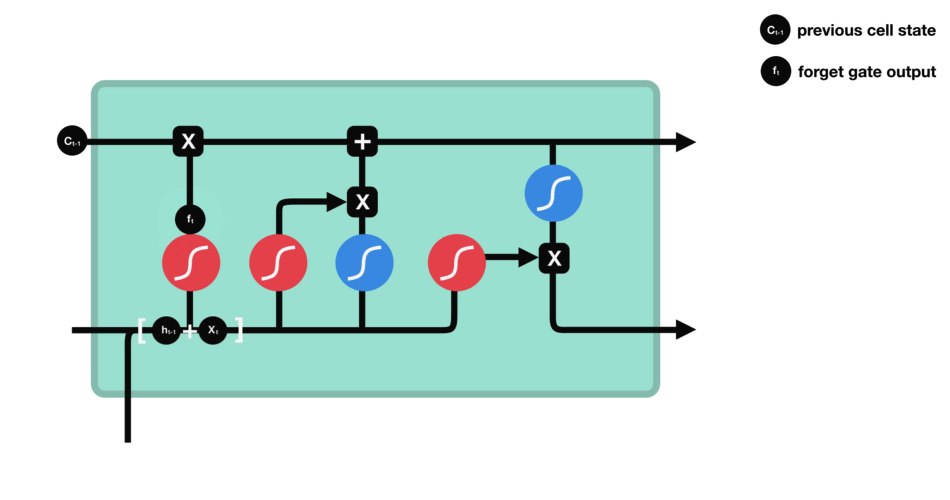
Operations of Forget gate
Input gate
To decide what new information we’re going to store in the cell state and update the cell state, we have the input gate.
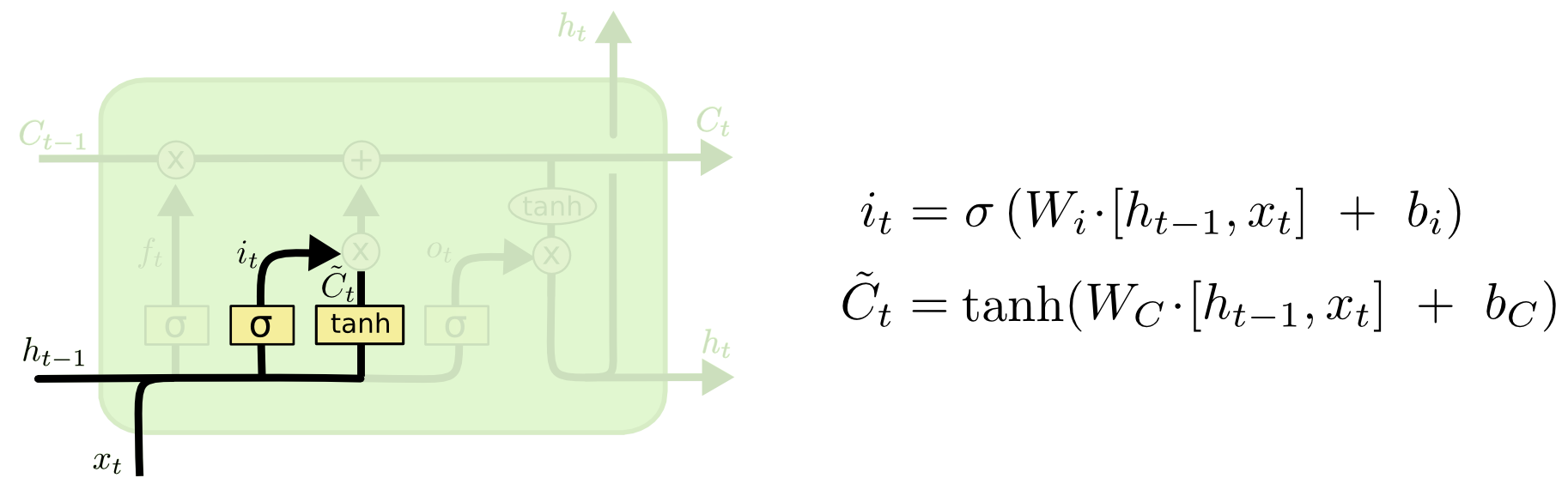
Pass the previous hidden state and current input
into a sigmoid function. That decides which values will be updated by transforming the values to be between $0$ and $1$ ($i\_t$)
- $0$: not important
- $1$: important
into the tanh function to squish values between $-1$ and $1$ to create a candidate cell state ($\tilde{C}\_t$) that should be added to the cell state.
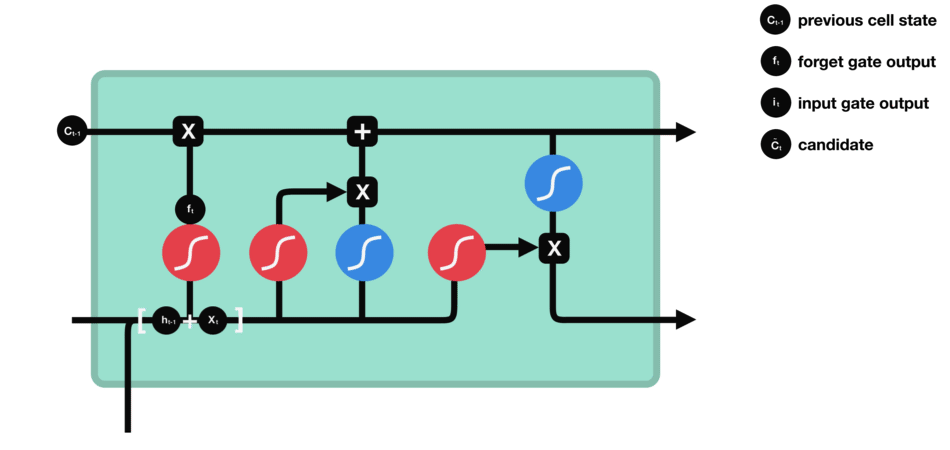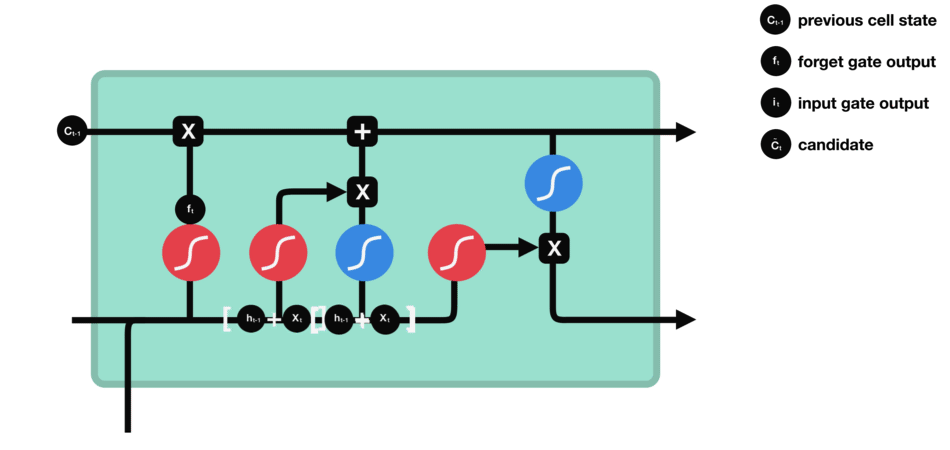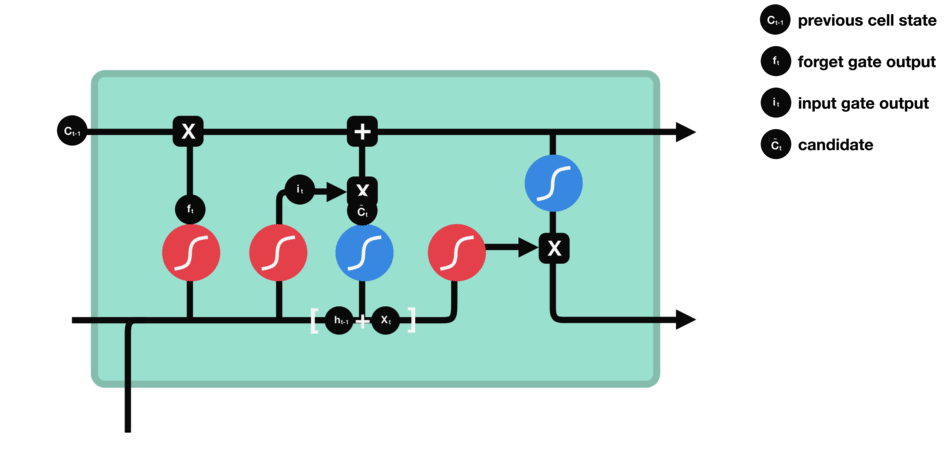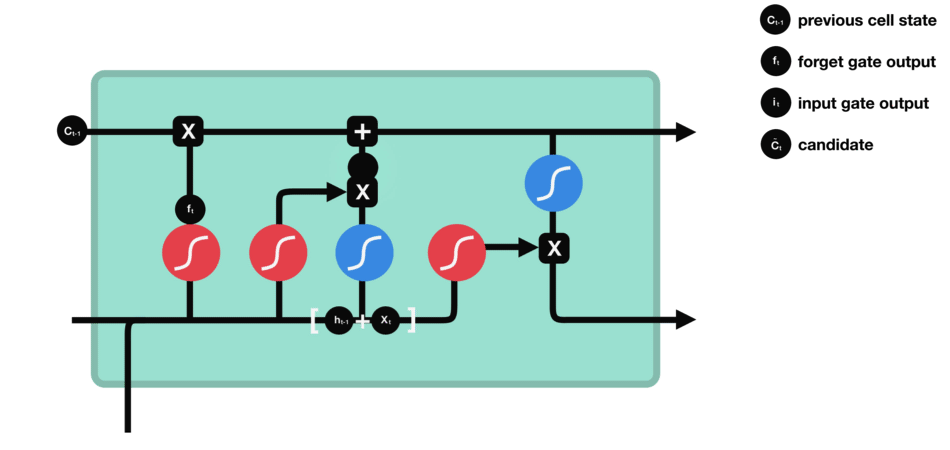
Operations of Input gate
Combine these two to create an update to the state
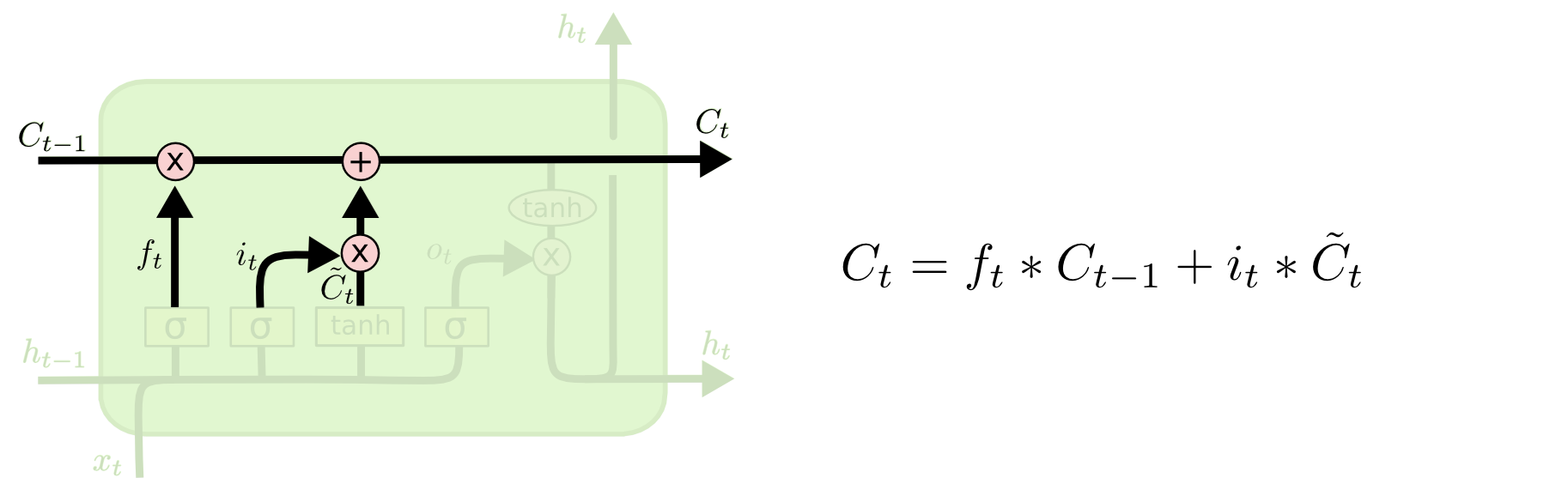
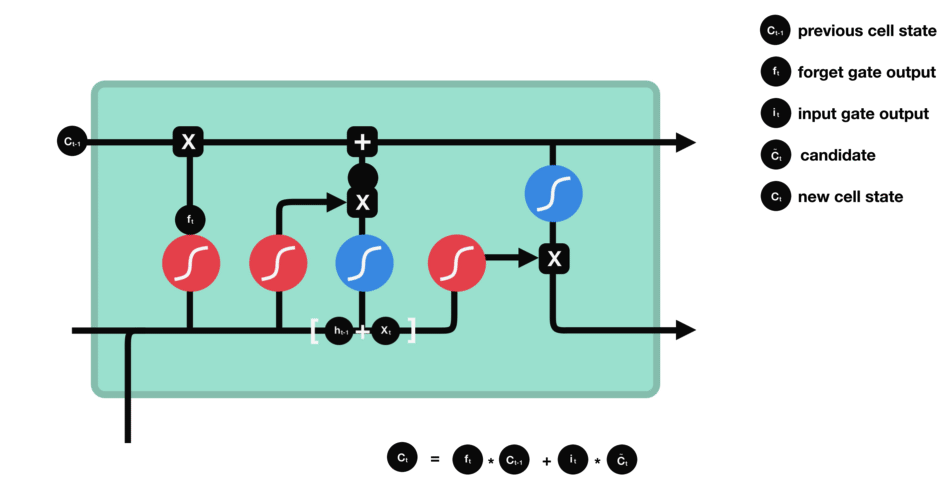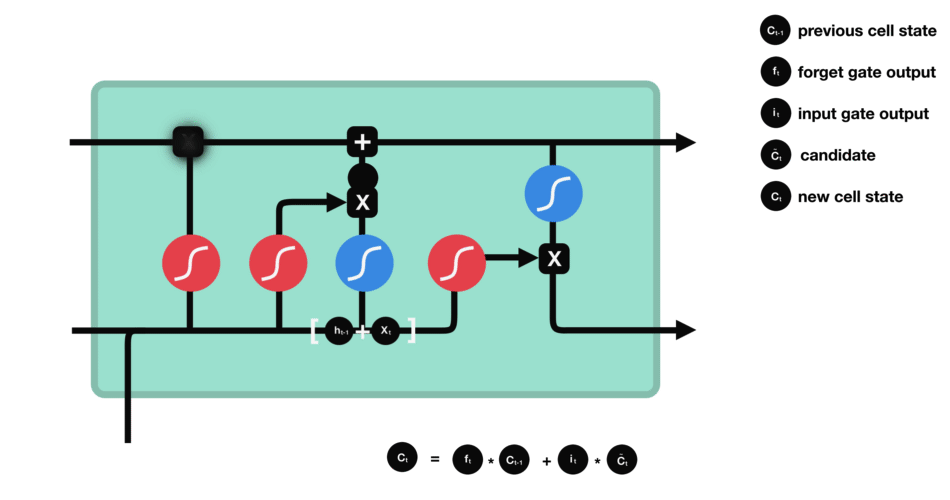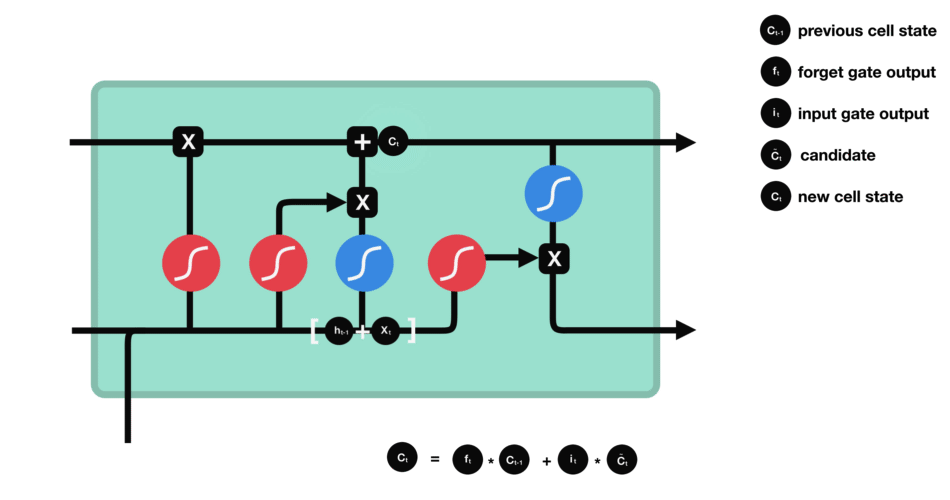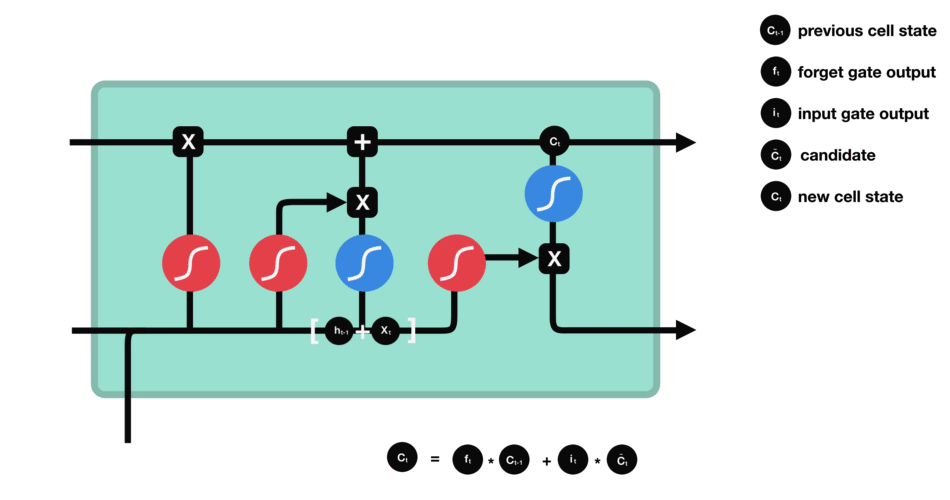
Calculating new cell state
Output gate
The output gate decides what the next hidden state should be. Remember that the hidden state contains information on previous inputs. The hidden state is also output for predictions.
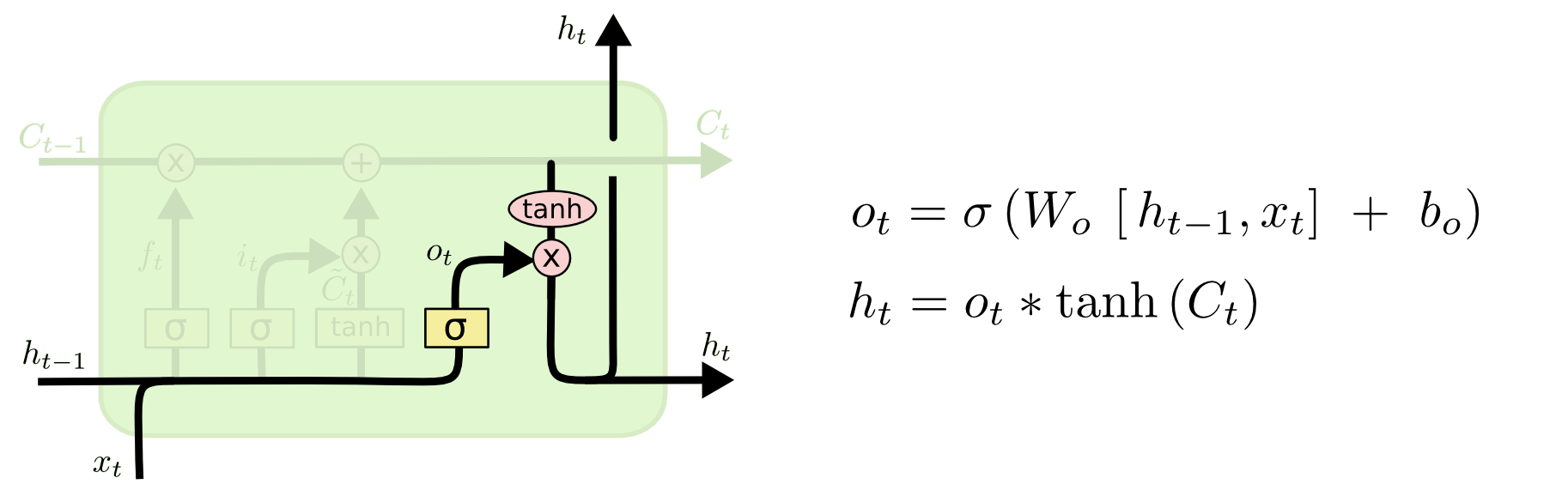
- Run a sigmoid layer which decides what parts of the cell state we’re going to output.
- Put the newly modified cell state through tanh function (to regulate the values to be between $−1$ and $1$) and multiply it by the output of the sigmoid gate, so that we only output the parts we decided to.
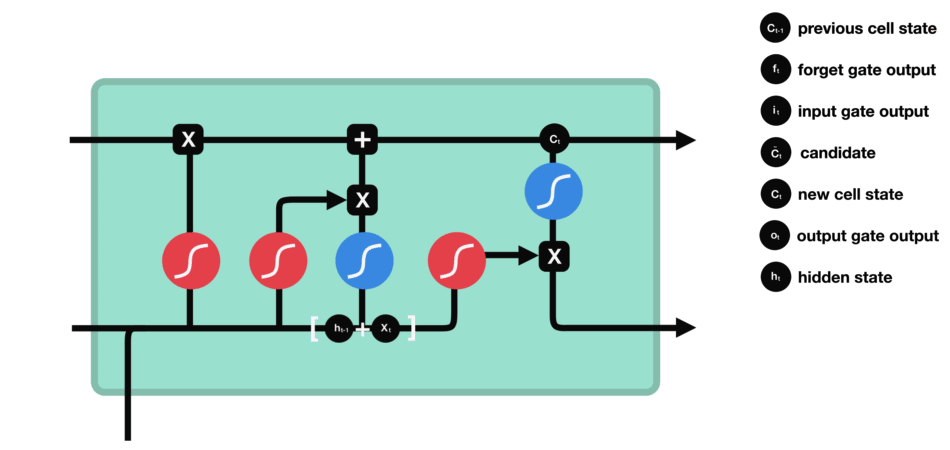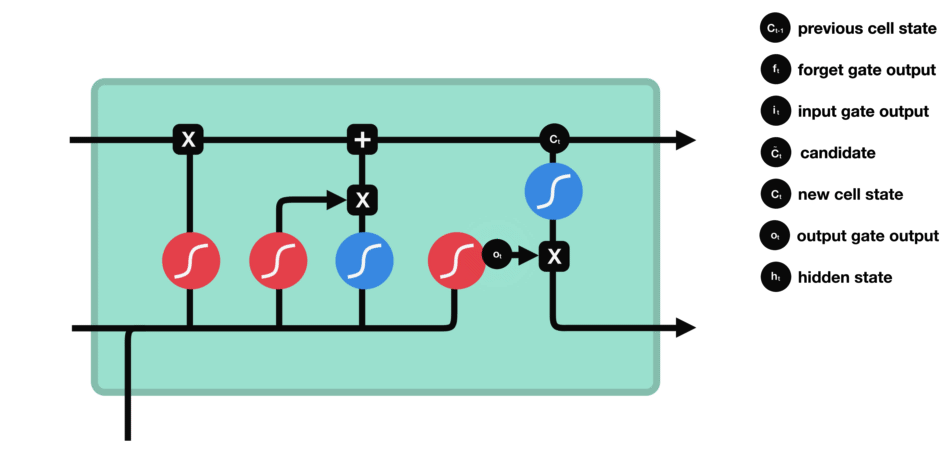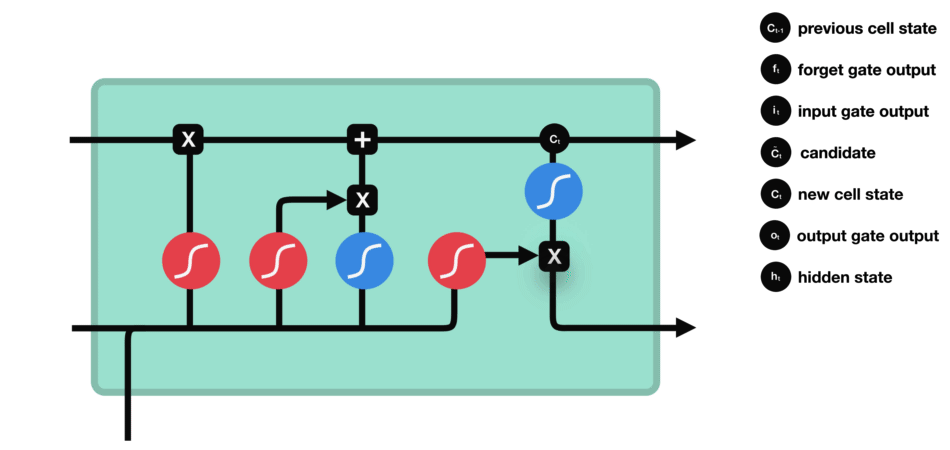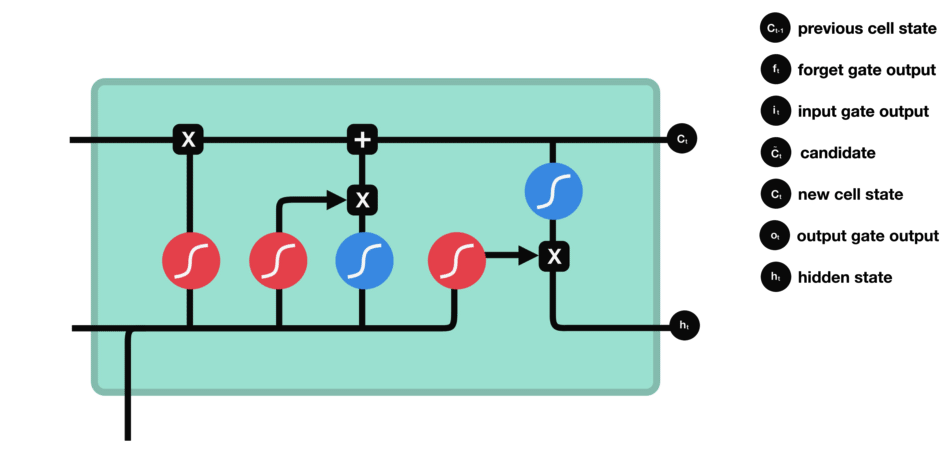
Operations of Output gate
Review
- Forget gate: decides what is relevant to keep from prior steps.
- Input gate: decides what information is relevant to add from the current step.
- Output gate: determines what the next hidden state should be.
Example
Consider a language model trying to predict the next word based on all the previous ones.
In such a problem, the cell state might include the gender of the present subject, so that the correct pronouns can be used.
| LSTM gate | In exmple model |
|---|---|
| Forget gate | When we see a new subject, we want to forget the gender of the old subject. |
| Input gate | 1. We’d want to add the gender of the new subject to the cell state, to replace the old one we’re forgetting. 2. We drop the information about the old subject’s gender and add the new information. |
| Output gate | Since it just saw a subject, it might want to output information relevant to a verb, in case that’s what is coming next. For example, it might output whether the subject is singular or plural, so that we know what form a verb should be conjugated into if that’s what follows next. |
Python Pseudocode
def LSTM_cell(prev_ct, prev_ht, input):
# Concatenate previous hidden state and current input
combine = prev_ht + input
# Forget gate remove non-relevant data
ft = forget_layer(combine)
# Candiate holds possible values to add to the cell state
candidate = candidate_layer(combine)
# Input layer decides what data from the candidate
# should be added to the new cell state
it = input_layer(combine)
# Calculate new cell state using forget layer, candidate layer
# and input layer
Ct = prev_Ct * ft + candidate * it
# Output layer decides which part should be output
ot = output_layer(combine)
# Pointwise multiplying the output gate and the new cell state
# gives us the new hidden state.
ht = ot * tanh(Ct)
return ht, Ct
ct = [0, 0, 0]
ht = [0, 0, 0]
for input in iuputs:
ct, ht = LSTM_cell(ct, ht, input)
Summary
Diagram of Strucutre
Whole Process