Learn PyTorch with Example
TL;DR
PyTorch provides two main features:
- An n-dimensional Tensor, similar to numpy but can run on GPUs
- Automatic differentiation for building and training neural networks
Typical procedure of neural network training with PyTorch
Define network structure
Use
torch.nn.Sequential, e.g.:model = torch.nn.Sequential( torch.nn.Linear(D_in, H), torch.nn.ReLU(), torch.nn.Linear(H, D_out), )or
Define own Modules by
- subclassing
nn.Module - defining a
forwardfunction which receives input Tensors
import torch class TwoLayerNet(torch.nn.Module): def __init__(self, D_in, H, D_out): """ In the constructor we instantiate two nn.Linear modules and assign them as member variables. """ super(TwoLayerNet, self).__init__() self.linear1 = torch.nn.Linear(D_in, H) self.linear2 = torch.nn.Linear(H, D_out) def forward(self, x): """ In the forward function we accept a Tensor of input data and we must return a Tensor of output data. We can use Modules defined in the constructor as well as arbitrary operators on Tensors. """ h_relu = self.linear1(x).clamp(min=0) y_pred = self.linear2(h_relu) return y_pred- subclassing
Define loss function and optimizer (and learning rate)
Loss function: implemented in
torch.nnE.g.: Mean Square Loss
loss_fn = torch.nn.MSELoss(reduction='sum')
Optimizer (see:
torch.optim) and learning rateE.g.: Adam
learning_rate = 1e-4 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
Iterate training dataset multiple times. In each iteration
1. Forward pass 2. Compute loss 3. Zero all of the parameters' gradients 4. Backward pass 5. Update parametersfor t in range(500): # 3.1 Forward pass y_pred = model(x) # 3.2 Compute and print loss loss = loss_fn(y_pred, y) if t % 100 == 99: print(t, loss.item()) # 3.3 Zero gradients optimizer.zero_grad() # 3.4 Backward pass loss.backward() # 3.5 Update parameters optimizer.step()
Diagramm Summary
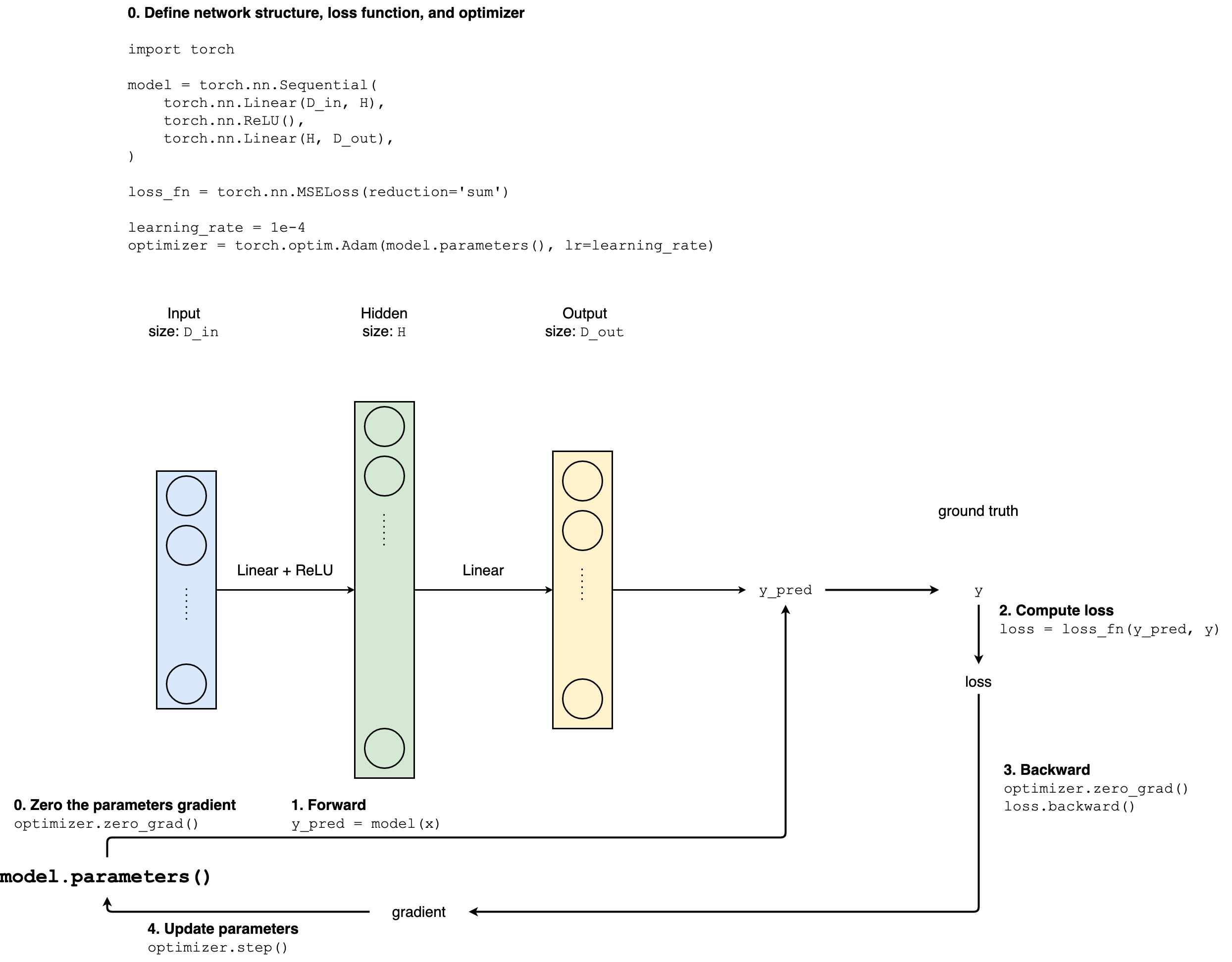
Training in PyTorch overview
From numpy to pytorch
View in nbviewer