Zustandsschätzung
Vorbemerkungen
Bayessches Gesetz und erweiterte Konditionierung
$$ \begin{array}{l} &P(a \mid b) \cdot P(b)=P(a, b)=P(b \mid a) \cdot P(a) \\\\ \Rightarrow &P(b \mid a)=\frac{P(a | b) \cdot P(b)}{P(a)} \end{array} $$Erweiterte Konditionierung:
$$ \begin{array}{l} P(b \mid a, c) \cdot \underbrace{P(a, c)}_{P(a \mid c) \cdot P(c)}=P(a, b, c)=P(a \mid b, c) \cdot \underbrace{P(b, c)}_{P(b \mid c) \cdot P(c)} \\\\ \Rightarrow P(b \mid a, c) \cdot P(a \mid c)=P(a \mid b, c) \cdot P(b \mid c) \quad (\triangle) \\\\ \Rightarrow P(b \mid a, c)=\frac{P(a \mid b, c) \cdot P(b \mid c)}{P(a \mid c)} \end{array} $$Notation zu Abhängigkeit vom Eingang
Abhängigkeit der Systemmatrizen $\mathbf{A}_k$ (Übergangsmatrix) und $\mathbf{B}_k$ (Messe-/Beobachtungsmatrix) von Eingang $u_k$ (4 dimensionale Felde):
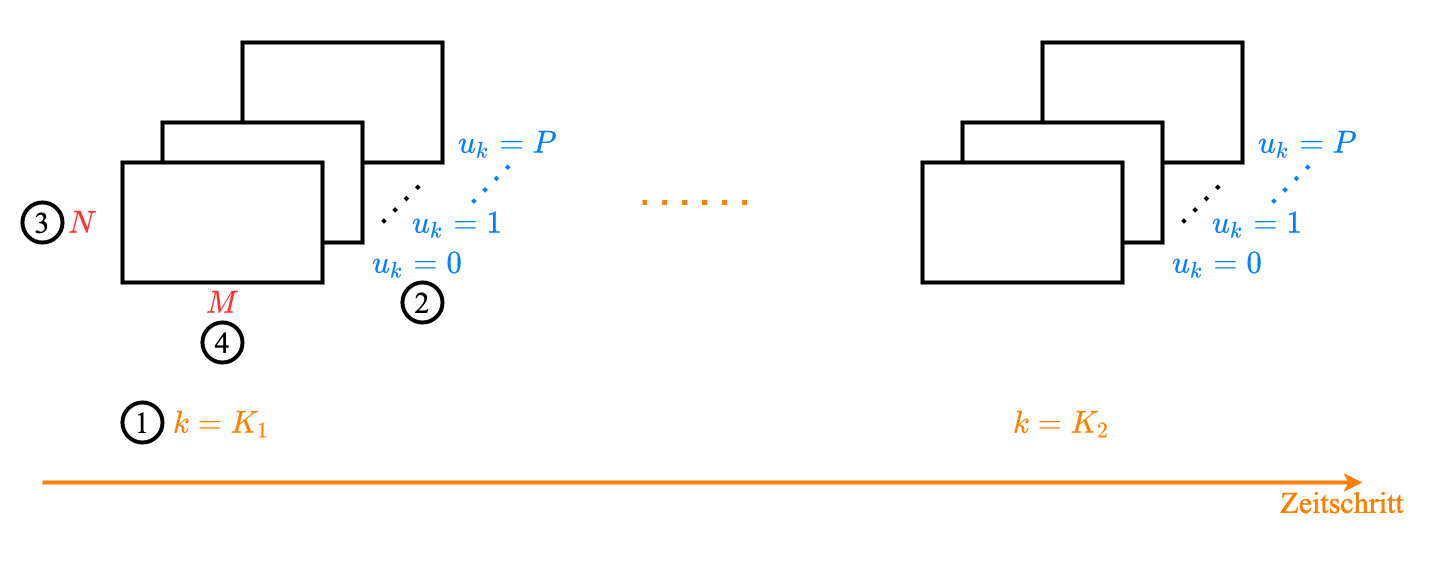
Schreibweise:
$$ \begin{array}{l} &A\left(k, u_{k}, X_{k+1} = x_{k+1}, X_{k}=x_{k}\right) \\ = &A\left(k, u_{k}, x_{k+1}, x_{k}\right) \\ = &A_{k}\left(u_{k}, x_{k+1}, x_{k}\right) \\ = &A_{k}^{u_{k}}\left(x_{k+1}, x_{k}\right) \\ \end{array} $$“Zum Zeitpunkt $k$ ist der aktuelle Zustand $X_k=x_k$. Was ist die Wahrscheinlichkeit vom den nächsten Zustand $X_{k+1}=x_{k+1}$, wenn der Eingang $u_k$ ist?”
Zeitinvariante Fall:
$$ A(u_k, x_{k+1}, x_k) = A_{u_k}(x_{k+1}, x_k) $$Zustandsschätzung
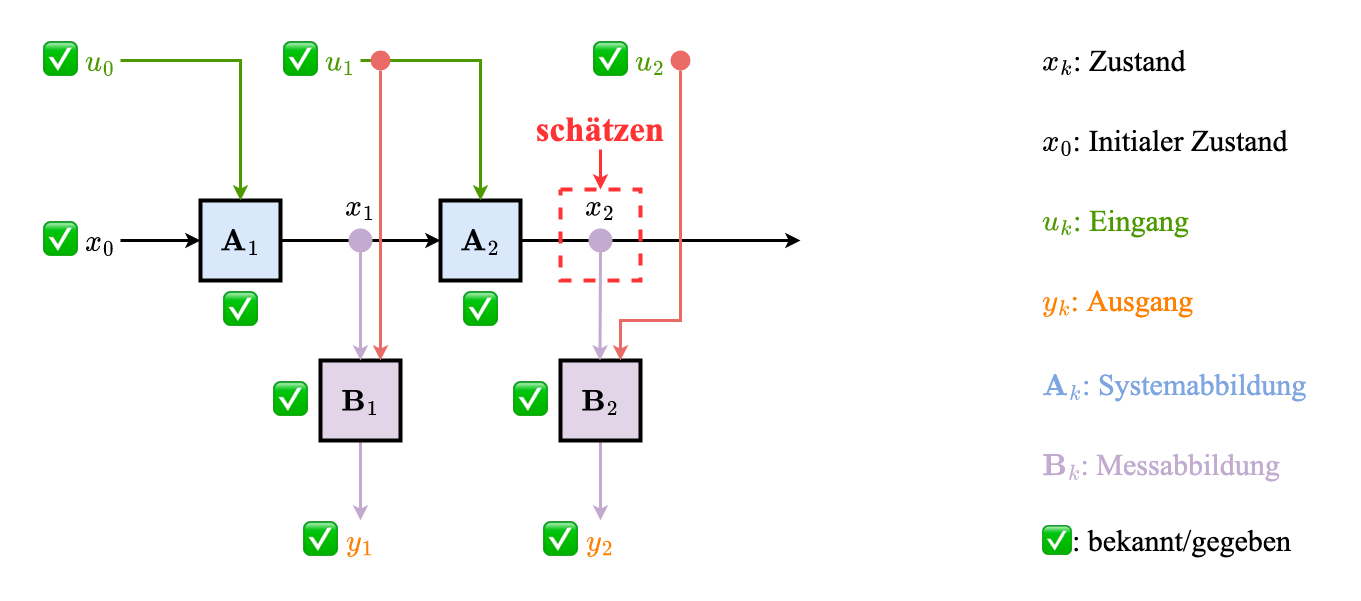
Ziel
Rekonstruktion des internen Zustands aus Messungen und Eingängen (Annahme: $\mathbf{A}_k, \mathbf{B}_k$ bekannt)
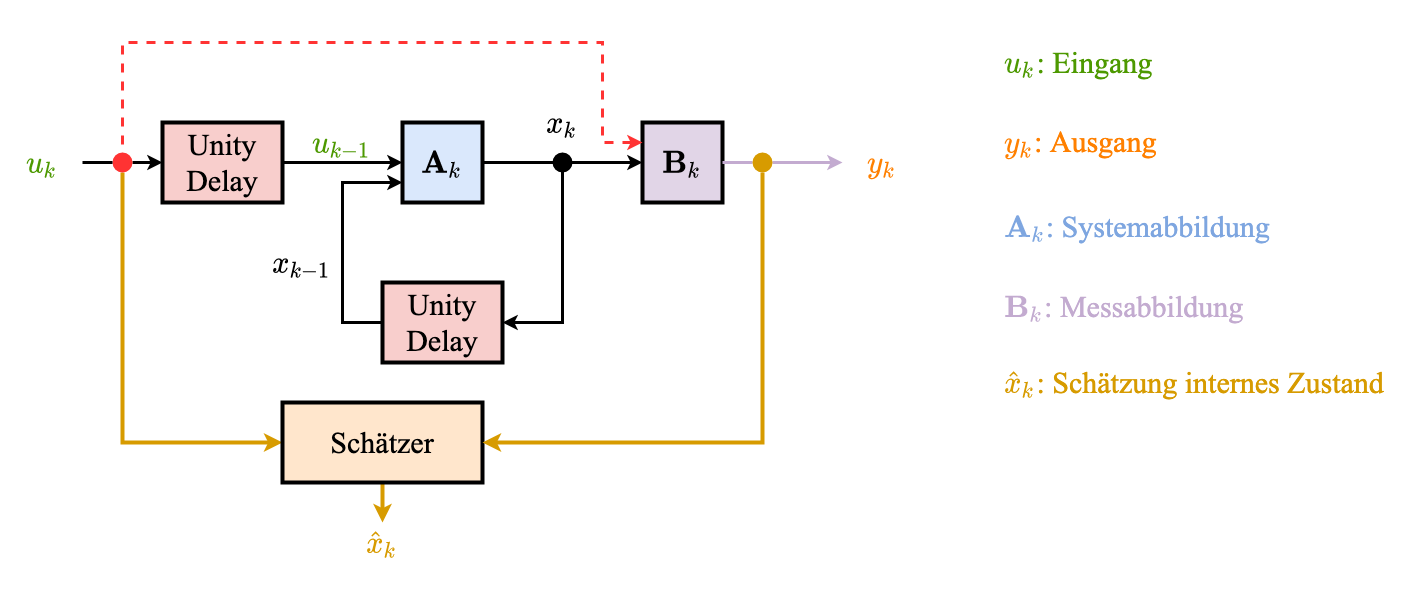
Interner Zustand Schätzer
Problemformulierung
Gegeben
Eingänge $u_k, k = 0, \dots, k_u$
Messungen $y_k, k = 1, \dots, k_y$
Gesucht: Rekonstruktion des Zustands
$\hat{x}_k, k = 1, \dots, k_x$ (alle interne Zustände)
$\hat{x}_{k_x}$ (der letzte Zustand)
Bsp Darstellung
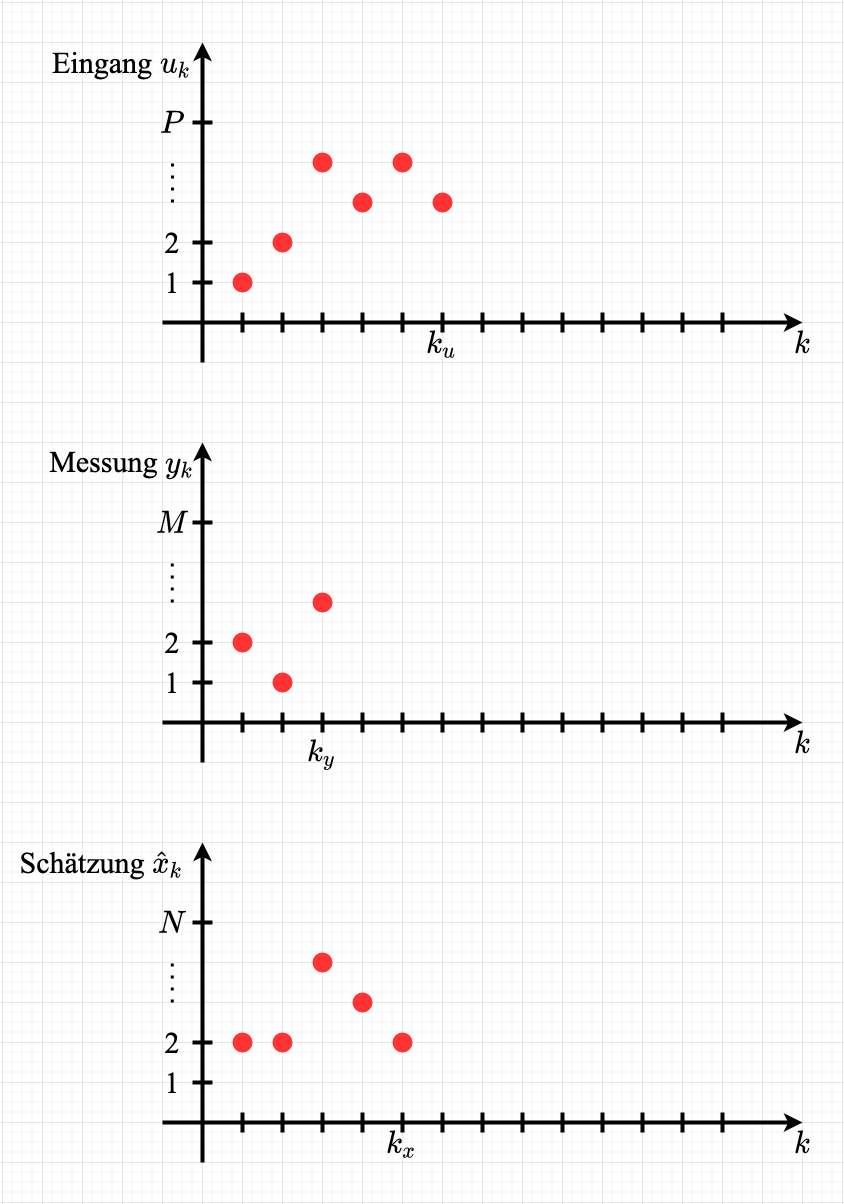
Paradigma: Nutzung aller Daten
Zwei wichtige Fälle/Phasen
Prädiktion ($k_u + 1 = k_x > k_y$)
Eine Prädiktion für den aktuellen Zustand basierend auf den letzten Zustand machen
Filterung ($k_u + 1 = k_x = k_y$)
Mit der beobachtbaren Messungen die Prädiktion updaten/verfeinern
Prädiktion
Allgemein
Gegeben
Schätzung des Zustands zu einem Zeitpunkt $m$, welche gesamte Eingang- und Messhistorik bis dahin enthält
Eingänge $u_k$ für $k > m$
Systemmatrizen $A_k$ für $k>m$
Interpretation
Ab Zeitpunkt $m+1$ fehlen Messungen. Wie entwicklt sich System rein auf Basis des Systemmodells?
Gesucht
Prädiktion zu späteren Zeitpunkt $k>m$ für gegeben Eingänge bis $k-1$
$$ P(x_k \mid y_{1:m}, u_{0: k- 1}) $$für $x_k \in \{1, \dots, N\}$
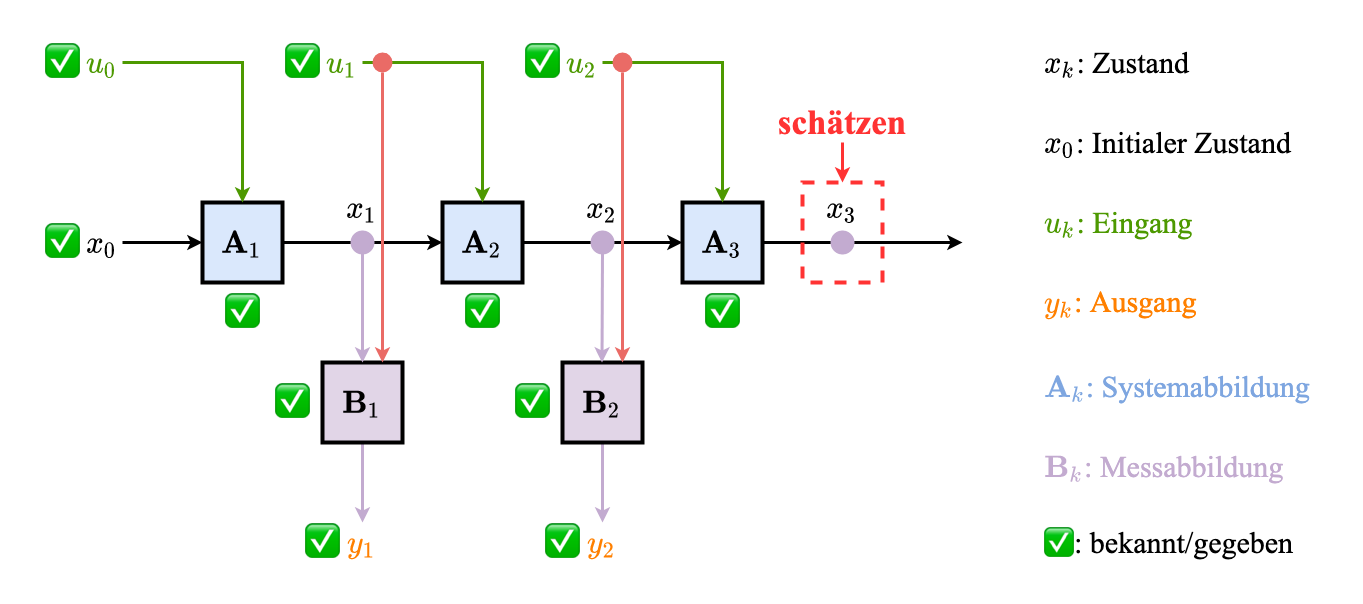
Beispiel:
$m = 2, k =3$
Prädiktion:
$$ P(x_3 \mid y_{1:2}, u_{0:2}) $$
Es ist wichtig, dem Bayessches Gesetz mit der erweiterten Konditionierung zu verwenden
$$ P(a, b \mid c) = P(a \mid b, c) \cdot P(b \mid c) \qquad (\ast) $$Zum Zeitpunkt $k > m$:
$$ \begin{array}{l} &P\left(x_{k} \mid y_{0: m}, u_{0: k-1}\right)\\ =&P\left(x_{k} \mid y_{0}, y_{1}, \cdots, y_{m}, u_{0}, u_{1}, \cdots u_{k-1}\right) \quad \mid \text{Marginalisierung}\\ =& \displaystyle \sum_{x_{k-1}=1}^{N} P\left(x_{k}, x_{k-1} \mid y_{0: m}, u_{0: k-1}\right)\\ \overset{(\ast)}{=}&\displaystyle \sum_{x_{k-1}=1}^{N} P\left(x_{k} \mid x_{k-1}, y_{0: m}, u_{0: k-1}\right) P\left(x_{k-1} \mid y_{0: m}, u_{0: k-1}\right) \quad \mid \text{Markov}\\ =&\displaystyle \sum_{x_{k-1}=1}^{N} \underbrace{P\left(x_{k} \mid x_{k-1}, u_{k-1}\right)}_{\text {Übergangswachrshheinlicheit }} \cdot \underbrace{P\left(x_{k-1} \mid y_{0: m}, u_{0 : k-2}\right)}_{\text {Schätzung für } k-1} \quad \text { (Rekursiv nach vorne) } \end{array} $$(Die Summe beschreibt eine Vektor-Matrix-Multiplikation.)
Anordnen der Einzelwahrscheinlichkeit in Vektoren:
$$ \eta_{k \mid 1: m}^{x} = \left(\begin{array}{c} P\left(x_{k}=1 \mid y_{1: m}, u_{0: k-1}\right) \\ \vdots \\ P\left(x_{k}=N \mid y_{1: m}, u_{0: k-1}\right) \end{array}\right) \qquad \eta_{k-1 \mid 1: m}^{x}=\left(\begin{array}{c} P\left(x_{k-1}=1 \mid y_{1: m}, u_{0: k-2}\right) \\ \vdots \\ P\left(x_{k-1}=N \mid y_{1: m}, u_{0: k-2}\right) \end{array}\right) $$Rekursive Prädiktion:
Beginn: Schätzvektor $\eta_{m \mid 1: m}^{x}$
Rekursion: für $k > m$
$$ \eta_{k \mid 1: m}^{x}=\mathbf{A}_{k}^{\top} \eta_{k-1 \mid 1 : m}^{x} $$Spezialfall: Einschrittprädiktion ($k = m + 1$)
Konkretes Beispiel
Systemmodell (zeitinvariant)
Systemabbildung
$$ \mathbf{A}_{u_{k}}=\left(\begin{array}{ll} a_{1}\left(u_{k}\right) & 1-a_{1}\left(u_{k}\right) \\ a_{2}\left(u_{k}\right) & 1-a_{2}\left(u_{k}\right) \end{array}\right) \qquad a_{1}\left(u_{k}\right), a_{2}\left(u_{k}\right) \in[0,1] $$Reminder: $A(i, j):=P\left(x_{k+1}=j \mid x_{k}=i\right)$
Messeabbildung
$$ \mathbf{B}=\left(\begin{array}{ll} b_{1} & 1-b_{1} \\ b_{2} & 1-b_{2} \end{array}\right) \qquad b_1, b_2 \in [0, 1] $$Reminder: $B(i, j):=P\left(y_{k}=j \mid x_{k}=i\right)$
Gegeben
Initialer Zustandsschätzvektor
$$ \eta_{0}^{x}=\left[\begin{array}{c} p_{0} \\ 1-p_{0} \end{array}\right] (=P(x_0)) \qquad p_{0} \in[0,1] $$(Also: $P(x_0 = 1) = P_0, P(x_0 = 2) = 1- P_0$)
Werte der Eingänge $u_0, u_1, u_2$
Keine Messungen
Gesucht
Verbundverteilung für die Zeitpunkt $k = 1, 2, 3$
$$ P\left(x_{1}, x_{2}, x_{3} \mid u_{0}, u_{1}, u_{2}\right)=: P\left(x_{1,3} \mid u_{0: 2}\right) $$Verteilung zum Zeitpunkt $k=3$
$$ p\left(x_{3} \mid u_{0}, u_{1}, u_{2}\right)=p\left(x_{3} \mid u_{0: 2}\right)=\eta_{3}^{x}\left(x_{3}\right) $$
Also wir sind in Zeitschritt 0, und möchte Prädiktion machen für
- zukünftige Zustände $x_k, k = 1, 2, 3$
- zukünftige Messungen $y_k, k=1,2,3$
Aufspaltung der Verbundverteilung für $k = 0, 1, 2, 3$:
$$ \begin{aligned} & P\left(x_{0: 3} \mid u_{0: 2}\right) \\ \overset{(\ast)}{=}& P\left(x_{3} \mid x_{0: 2}, u_{0: 2}\right) \cdot P\left(x_{0: 2} \mid u_{0: 2}\right) \\ \overset{\text{Markov}}{=}& P\left(x_{3} \mid x_{2}, u_{2}\right) \cdot P\left(x_{2} \mid x_{0: 1}, u_{0: 2}\right) \cdot P\left(x_{0: 1} \mid u_{0: 2}\right) \\ \overset{\text{Markov}}{=}& P\left(x_{3} \mid x_{2}, u_{2}\right) \cdot P\left(x_{2} \mid x_{1}, u_{1}\right) P\left(x_{1} \mid x_{0}, u_{0: 2}\right) \cdot P\left(x_{0} \mid u_{0: 2}\right) \\ =& P\left(x_{3} \mid x_{2}, u_{2}\right) \cdot P\left(x_{2} \mid x_{1}, u_{1}\right) \cdot P\left(x_{1} \mid x_{0}, u_{0}\right) \cdot P\left(x_{0}\right) \\ =& A_{u_{2}}\left(x_{2}, x_{3}\right) \cdot A_{u}\left(x_{1}, x_{2}\right) \cdot A_{u_{0}}\left(x_{0}, x_{1}\right) \cdot \eta_{0}^{x}\left(x_{0}\right) \end{aligned} $$Verbundverteilung für $k = 1, 2, 3$:
$$ \begin{aligned} P\left(x_{1: 3} \mid u_{0: 2}\right) &=\sum_{x_{0}=1}^{2} P\left(x_{0: 3} \mid u_{0: 2}\right) \\ &=\underbrace{P\left(x_{3} \mid x_{2}, u_{2}\right)}_{=\mathbf{A}_{u_{2}}\left(x_{2}, x_{3}\right)} \cdot \underbrace{P\left(x_{2} \mid x_{1}, u_{1}\right)}_{=\mathbf{A}_{u_{1}}\left(x_{1}, x_{2}\right)} \cdot \underbrace{\sum_{x_0=1}^{2} P\left(x_{1} \mid x_{0}, u_{0}\right) \cdot P\left(x_{0}\right)}_{=P\left(x_{1} \mid u_{0}\right)=\eta_{1}^{*}\left(x_{1}\right)} \end{aligned} $$$$ \begin{array}{l} \eta_{1}^{x}\left(x_{1}\right) &= \sum_{x_{0}=1}^{2} A_{u_{0}}\left(x_{0}, x_{1}\right) \cdot \eta_{0}^{x}\left(x_{0}\right)\\ &=A_{u_{0}}\left(x_{0}=1, x_{1}\right) \underbrace{{P}_{0}}_{=P(x_0 = 1)}+A_{u_{0}}\left(x_{0}=2, x_{1}\right) \underbrace{\left(1-P_{0}\right)}_{=P\left(x_{0}=2\right)} \quad (\text{Marginalisierung})\\ &=\left\{\begin{array}{ll} a_{1} \cdot p_{b}+a_{2}\left(1-p_{0}\right) & x_{1}=1 \\ \left(1-a_{1}\right) p_{0}+\left(1-a_{2}\right)\left(1-p_{0}\right) & x_{1}=2 \end{array}\right. \end{array} $$ $$ \begin{aligned} P\left(x_{3} \mid u_{0: 2}\right)=&\displaystyle \sum_{x_{2}=1}^{2} \sum_{x_{1}=1}^{2} P\left(x_{1: 3} \mid u_{0: 2}\right)\\ =&\displaystyle \sum_{x_{2}=1}^{2} A_{u_{2}}\left(x_{2}, x_{3}\right) \underbrace{\displaystyle \sum_{x_{1} = 1}^{2}\left(x_{1}, x_{2}\right) \eta_{1}^{x}\left(x_{1}\right)}_{=P\left(x_{1} \mid u_{0:1}\right)=\eta_{2}^{x}\left(x_{1}\right)}\\ =&\sum_{x_{2}=1}^{2} A_{u_{2}}\left(x_{2}, x_{3}\right) \cdot \eta_{2}^{x}\left(x_{2}\right)\\\\ =& \eta_{3}^{x}\left(x_{3}\right) \end{aligned} $$ $$ \begin{aligned} \eta_{3}^{x} &=\mathbf{A}_{u_{2}}^{\top} \cdot \underbrace{\eta_{2}^{x}}_{=\mathbf{A}_{u_{1}}^{\top} \cdot \eta_{1}^{x}} \\ &=\mathbf{A}_{u_{2}}^{\top} \cdot (\mathbf{A}_{u_{1}}^{\top} \cdot \underbrace{\eta_{1}^{x}}_{=\mathbf{A}_{u_{0}}^{\top} \cdot \eta_{0}^{x}})\\ &=\mathbf{A}_{u_{2}}^{\top} \cdot (\mathbf{A}_{u_{1}}^{\top} \cdot (\mathbf{A}_{u_{0}}^{\top} \cdot \eta_{0}^{x})) \quad \text { (rekursive Berechnung) } \end{aligned} $$$P\left(x_{1: 3} \mid u_{0: 2}\right)$ bedeutet: $P$ indiziert mit dem 3-dimensionalen Indexvekter $(1, 2, 3)^\top$. Jede von dem kann 2 Wer4te annehmen.
Prädikition der Messungen für $k=1,2,3$:
$$ \begin{aligned} & P(y_{1}, y_{2}, y_{3}, x_{1: 3} \mid u_{0: 2}) \\\\ \overset{(\ast)}{=}& P\left(y_{1: 3} \mid x_{1: 3}, u_{0: 2}\right) \cdot P\left(x_{1: 3} \mid u_{0: 2}\right) \\\\ =& P\left(y_{1: 3} \mid x_{1: 3}\right) P\left(x_{1: 3} \mid u_{0: 2}\right) \\\\ =& P\left(y_{1} \mid x_{1: 3}\right) P\left(y_{2} \mid x_{1: 3}\right) P\left(y_{3} \mid x_{1: 3}\right) P\left(x_{1: 3} \mid u_{0: 2}\right) \\\\ =& P\left(y_{1} \mid x_{1}\right) \cdot P\left(y_{2} \mid x_{2}\right) \cdot P\left(y_{3} \mid x_{3}\right) P\left(x_{1: 3} \mid u_{0: 2}\right) \\\\ =& B\left(x_{1}, y_{1}\right) B\left(x_{2}, y_{2}\right) B\left(x_{3}, y_{3}\right) P\left(x_{1: 3} \mid u_{0: 2}\right) \end{aligned} $$Prädikition Messung für $k=3$:
$$ \begin{aligned} & P\left(y_{3}, x_{3} \mid u_{0: 2}\right) \\ \overset{(\ast)}{=}& P\left(y_{3} \mid x_{3}, u_{0: 2}\right) \cdot P\left(x_{3} \mid u_{0: 2}\right) \\ =& P\left(y_{3} \mid x_{3}\right) \cdot P\left(x_{3} \mid u_{0: 2}\right) \\ =& B\left(x_{3}, y_{3}\right) \cdot \eta_{3}^{x}\left(x_{3}\right) \end{aligned} $$Filterung (Wonham Filter)
Wie sieht $P\left(x_{k} \mid y_{1: k}, u_{0: k-1}\right)$ auf Basis der Prädiktion $P\left(x_{k} \mid y_{1: k-1}, u_{0: k-1}\right)$ aus?
Reminder
$$ P(b \mid a, c) \cdot P(a \mid c)=P(a \mid b, c) \cdot P(b \mid c) \quad (\triangle) $$- Likelihood
- Normalisierungskonstant
- Einschrittsprädikation
Filterung in Vektor-Matrix-Form:
Für $y_k = m$, Bilde eine Diagonalematrix $\operatorname{diag}(\mathbf{B}(:, m))$ mit Spalte des Messmatrix $\mathbf{B}(:, m)$
$$ \begin{aligned} \eta_{k \mid 1: k}^{x} &\overset{y_k = m}{=}\frac{\operatorname{diag}(\mathbf{B}(:, m)) \cdot \eta_{k \mid 1: k-1}^{x}}{\mathbb{1}_{N}^{T} \operatorname{diag}(\mathbf{B}(:, m)) \cdot \eta_{k \mid 1: k-1}^{x}} \\\\ &=\frac{\mathbf{B}(:, m) \odot \eta_{k \mid 1: k-1}^{x}}{\mathbf{B}(:, m)^\top \cdot \eta_{k \mid 1:k-1}^{x}} \end{aligned} $$- $\mathbf{1}_N$: Einsvektor
- $\odot$: Elementwise-Multiplikation
Das ist ein komplett rekursives Filter $\rightarrow$ Wonham Filter
Beispiel siehe hier.