Zustandsschätzung: Kalman Filter
Prädiktion
Wir möchte ein Schritt Prädiktion für Zustand machen, also am Zeitschritt $k$ ($k > m$, $m:= \text{\#Messungen}$) die Prädiktion für den Zustand $\underline{x}_{k+1}$ zu machen
Modell:
$$ \underline{x}_{k+1}=\mathbf{A}_{k} \cdot \underline{x}_{k}+\mathbf{B}_{k} \cdot \underbrace{\left(\underline{\tilde{u}}_{k}+\underline{w}_{k}\right)}_{\underline{u_k}} $$Initialer Schätzwert für $k$:
$$ \underline{x}_{k|1:m} $$- basiert auf Messungen $\underline{y}_{1}, \dots, \underline{y}_{m}$
- Eingabewerte $\underline{\tilde{u}}_{0}, \dots, \underline{\tilde{u}}_{k-1}$
- mit Erwartungswert $\underline{\hat{x}}_{k|1:m}$ und Kovarianzmatrix $C_{k|1:m}^x$
Berechnung des Erwartungswerts für $k+1$
$$ \begin{aligned} &E\left\{\underline{x}_{k+1}\right\}\\\\ =&E\left\{\mathbf{A}_{k} \cdot \underline{x}_{k}+\mathbf{B}_{k}\left(\underline{\tilde{u}}_{k}+\underline{w}_{k}\right)\right\}\\\\ =&E\left\{\mathbf{A}_{k} \cdot x_{k}+\mathbf{B}_{k} \tilde{u}_{k}+\mathbf{B}_{k} \underline{w}_{k}\right\}\\\\ =&\mathbf{A}_{k} \cdot E\left\{x_{k}\right\}+\mathbf{B}_{k} \cdot \underbrace{E\left\{\tilde{u}_{k}\right\}}_{=\tilde{\underline{u}}_{k} \text{ (da } \tilde{\underline{u}}_{k} \text{ is fix)}}+\mathbf{B}_{k} \cdot\underbrace{E\left\{\underline{w}_{k}\right\}}_{=0 \text{ ("mittelwertfrei")}}\\\\ =&\mathbf{A}_{k} \cdot \underline{\hat{x}}_{k|1: m}+\mathbf{B}_{k} \tilde{\underline{u}}_{k} \qquad (+) \end{aligned} $$Berechnung der Kovarianzmatrix $C_{k+1|1:m}^x$
$$ \begin{aligned} \underline{x}_{k+1} &=\mathbf{A}_{k} \underline{x}_{k}+\mathbf{B}_{k} \underline{u}_{k} \\ &=\left[\begin{array}{ll} \mathbf{A}_{k} & \mathbf{B}_{k} \end{array}\right]\left[\begin{array}{c} \underline{x}_{k} \\ \underline{u}_{k} \end{array}\right] \end{aligned} $$ $$ \begin{aligned} \underline{x}_{k+1}-\hat{\underline{x}}_{k+1} &=\left[\begin{array}{ll} \mathbf{A}_{k} & \mathbf{B}_{k} \end{array}\right]\left[\begin{array}{c} \underline{x}_{k}-\hat{\underline{x}}_{k} \\ \underline{u}_{k}-\underline{\hat{u}}_{k} \end{array}\right] \\ &=\left[\begin{array}{ll} \mathbf{A}_{k} & \mathbf{B}_{k} \end{array}\right]\left[\begin{array}{c} \underline{x}_{k}-\underline{\hat{x}}_{k} \\ \underline{w}_{k} \end{array}\right] \end{aligned} $$Annahme: Zustand und Systemrauschen sind unkorreliert
$$ \begin{aligned} \operatorname{Cov}\left\{\left[\begin{array}{c} \underline{x}_{k} \\ \underline{\tilde{u}}_{k} \end{array}\right]\right\} &=E\left\{\left[\begin{array}{c} \underline{x}_{k}-\underline{\hat{x}}_{k} \\ \underline{w}_{k} \end{array}\right]\left[\left(\underline{x}_{k}-\underline{\hat{x}}_{k}\right)^{\top} \underline{w}_{k}^{\top}\right]\right\} \\ &=\left[\begin{array}{cc} C_{k \mid 1: m}^{x} & 0 \\ 0 & C_{k}^{w} \end{array}\right] \end{aligned} $$ $$ \begin{aligned} \mathbf{C}_{k+1 \mid 1 : m}^{x} &=E\left\{\left(\underline{x}_{k+1}-\hat{x}_{k+1}\right)\left(x_{k+1} - \hat{\underline{x}}_{k+1}\right)^\top\right\} \\ &=\left[\begin{array}{ll} \mathbf{A}_{k} & \mathbf{B}_{k} \end{array}\right] \cdot E\left\{\left[\begin{array}{c} \underline{x}_{k}-\hat{\underline{x}}_{k} \\ \underline{w}_{k} \end{array}\right]\left[\begin{array}{ll} \underline{x}_{k}-\hat{\underline{x}}_{k} & \underline{w}_{k} \end{array}\right]^\top\right\} \cdot\left[\begin{array}{l} \mathbf{A}_{k}^{\top} \\ \mathbf{B}_{k}^{\top} \end{array}\right] \\\\ &=\left[\begin{array}{ll} \mathbf{A}_{k} & \mathbf{B}_{k} \end{array}\right] \cdot\left[\begin{array}{cc} \mathbf{C}_{k \mid 1:m} & 0 \\ 0 & \mathbf{C}_{k}^{w} \end{array}\right] \cdot\left[\begin{array}{l} \mathbf{A}_{k}^{\top} \\ \mathbf{B}_{k}^{\top} \end{array}\right] \\ &=\mathbf{A}_{k} \cdot \mathbf{C}_{k \mid 1: m}^{x} \mathbf{A}_{k}^{\top}+\mathbf{B}_{k} \mathbf{C}_{k}^{w} \mathbf{B}_{k}^{\top} \qquad(++) \end{aligned} $$
Rekursive Prädiktion
Beginn mit Erwartungswert $\underline{\hat{x}}_{m|1:m}$ und Kovarianzmatrix $C_{m|1:m}^x$
Rekursion mit $(+)$ und $(++)$ für $k > m$
Filterung
Erinnerung
Struktur des dynamischen Systems
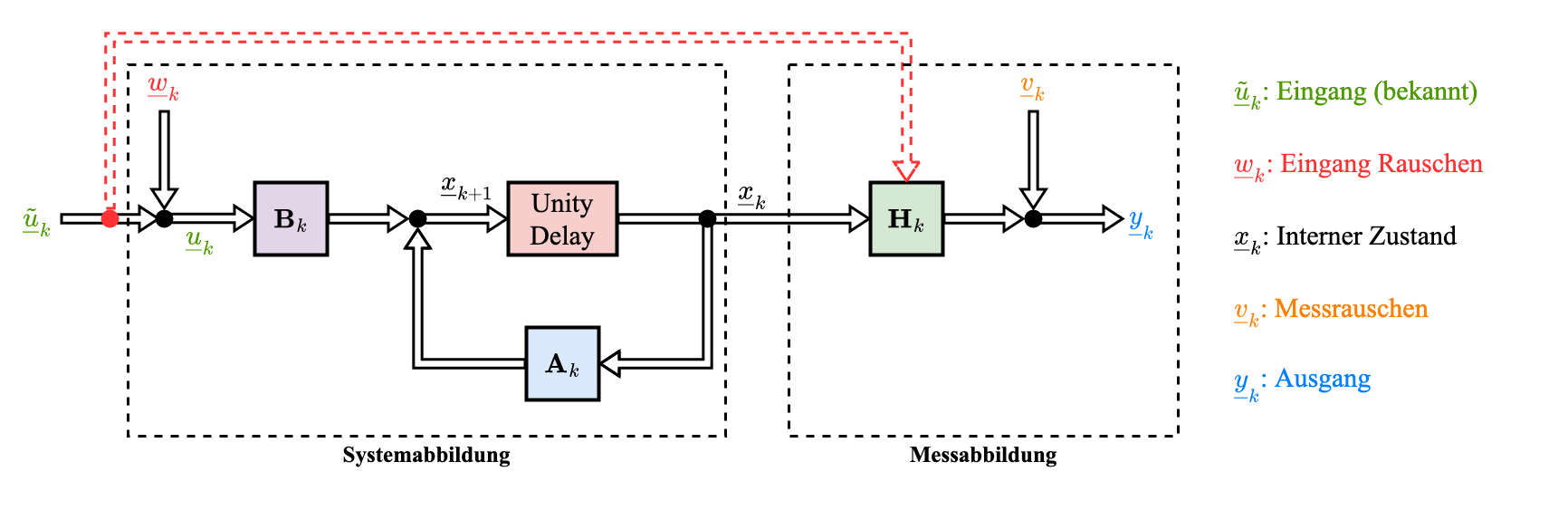
Graphische Darstellung von dynamischer Systeme
Ansatz: Linearer Schätzer
$$ \underline{x}_{k \mid 1: k}=\mathbf{K}_{k}^{(1)} \underline{x}_{k \mid 1: k-1}+\mathbf{K}_{k}^{(2)} \underline{y}_{k} \qquad(\ast) $$🎯 Wir suchen den sog. BLUE-Filter (Best Linear Unbiased Estimator) 💪
Ein Schätzer heißt erwartungstreu , wenn sein Erwartungswert gleich dem wahren Wert des zu schätzenden Parameters ist.
Ist eine Schätzfunktion nicht erwartungstreu, spricht man davon, dass der Schätzer verzerrt ist. Das Ausmaß der Abweichung seines Erwartungswerts vom wahren Wert nennt man Verzerrung oder Bias. Die Verzerrung drückt den systematischen Fehler des Schätzers aus.
Source und Bsp: Wiki
Erwartungswerttreue (unbiased)
$$ \begin{aligned} E\left\{\underline{x}_{k \mid 1: k}\right\}&=E\left\{\mathbf{K}_{k}^{(1)} \underline{x}_{k \mid 1: k-1}+\mathbf{K}_{k}^{(2)} \underline{y}_{k}\right\} \\ E\left\{\underline{x}_{k \mid 1: k}\right\}&=\mathbf{K}_{k}^{(1)} E\left\{\underline{x}_{k \mid 1: k-1}\right\}+\mathbf{K}_{k}^{(2)} E\left\{\underline{y}_{k}\right\} \\ E\left\{\underline{x}_{k \mid 1: k}\right\}&=\mathbf{K}_{k}^{(1)} E\left\{\underline{x}_{k \mid 1: k-1}\right\}+\mathbf{K}_{k}^{(2)} E\left\{\mathbf{H}_{k} \cdot x_{k}+\underline{v}_{k}\right\} \\ E\left\{\underline{x}_{k \mid 1: k}\right\}&=\mathbf{K}_{k}^{(1)} E\left\{\underline{x}_{k \mid 1: k-1}\right\}+\mathbf{K}_{k}^{(2)} \mathbf{H}_{k} E\left\{\underline{x}_{k}\right\} \quad \mid \text { Erwartungstreu } \\ \underline{\tilde{x}}&=\mathbf{K}_{k}^{(1)} \underline{\tilde{x}}+\mathbf{K}_{k}^{(2)} \mathbf{H}_{k} \cdot \underline{\tilde{x}} \\ \Rightarrow \mathbf{I} &=\mathbf{K}_{k}^{(1)}+\mathbf{K}_{k}^{(2)} \mathbf{H}_{k} \end{aligned} $$z.B.
$$ \begin{aligned} \mathbf{K}_{k}^{(1)} &= \mathbf{I} - \mathbf{K}_{k}\mathbf{H}_{k} \\ \mathbf{K}_{k}^{(2)} &= \mathbf{K}_{k} \end{aligned} $$
Setze in $(\ast)$ ein:
$$ \underbrace{\underline{x}_{k \mid 1: k}}_{=: \underline{x}_{k}^{e}}=\left(\mathbf{I}-\mathbf{K}_{k}\mathbf{H}_{k} \right) \underbrace{\underline{x}_{k \mid 1: k-1}}_{=: \underline{x}_{k}^{p}}+\mathbf{K}_{k} \underline{y}_{k} \qquad(* *) $$Aber der Schätzert ist noch nicht vollständig festgelegt, da $\mathbf{K}_{k}$ noch nicht festgelegt ist.
$\Rightarrow$ Wir suche $\mathbf{K}_{k}$ so, dass der resultierende Schätzer MINIMAL kovarianz aufweist. (“Minimalvarianz Schätzer”)
Nehme an, dass Messung unkorreliert mit priorer Schätzung. Aus $(\ast\ast)$ gilt
$$ \underbrace{\mathbf{C}_{k \mid 1: k}\left(\mathbf{K}_{k}\right)}_{=: \mathbf{C}_{k}^{e}\left(\mathbf{K}_{k}\right)}=\left(\mathbf{I}-\mathbf{K}_{k} \mathbf{H}_{k}\right) \underbrace{\mathbf{C}_{k \mid 1: k-1}^{x}}_{=: \mathbf{C}_{k}^{p}}\left(\mathbf{I}-\mathbf{K}_{k} \mathbf{H}_{k}\right)^{\top}+\mathbf{K}_{k} C_{k}^{v} \mathbf{K}_{k}^{\top} \qquad(\ast\ast\ast) $$Wir betrachten nun die Filterkovarianz $\mathbf{C}_{k}^{e}$ als Funktion von $\mathbf{K}_{k}$ , d. h. $\mathbf{C}_{k}^{e}(\mathbf{K}_k)$ . Ziel ist es, das $\mathbf{K}_{k}$ so zu finden, dass die Filterkovarianz so klein wie möglich ist.
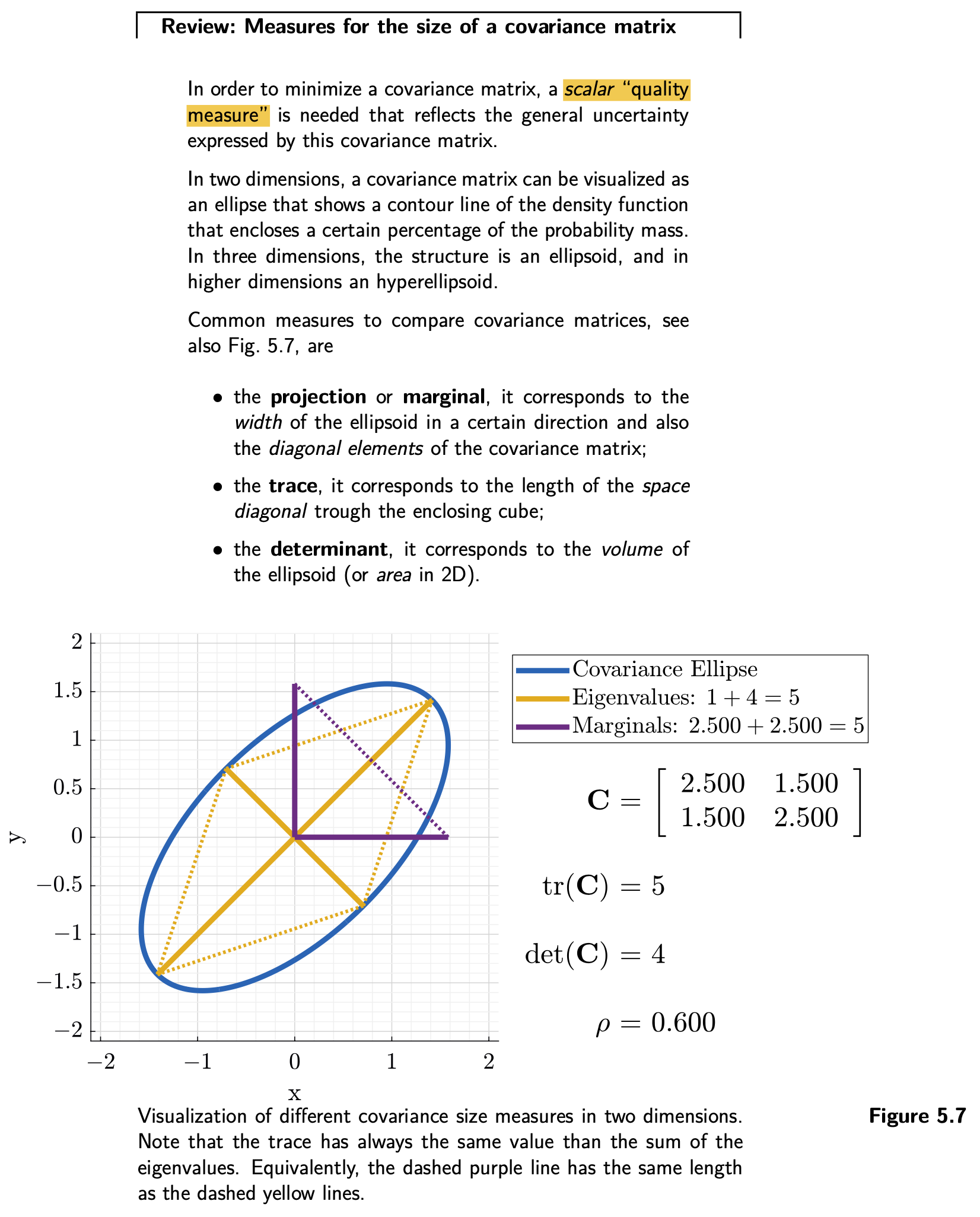
Trick: Auf Skalares Gütemaß zurückzuführen
D.h., um Kovarianzmatrizen generell vergleichen zu können, verwende man die Funktionen, die von einer $n \times n$ Matrix in $\mathbb{R}^1$ abbilden. Anders gesagt, die einer Kovarianzmatrix einen Skalar zuordnen, denn man kann nur Skalare direkt miteinander vergleichen.
Z.B., Projektion mit beliebigen Einheitsvektor $\underline{e}$
$$ P(\mathbf{K}) = \underline{e}^\top \cdot \mathbf{C}_c(\mathbf{K}) \cdot \underline{e} $$MINIMAL Kovarianz $\Leftrightarrow$ $P(\mathbf{K})$ soll minimal sein für $\underline{e}$.
Andere mögliche skalare Gütemaße:
$\operatorname{Spur}(\cdot)$: Summe der Diagonalelemente
$$ \begin{equation} \operatorname{Spur}(\mathbf{C})=\sigma\_{x}^{2}+\sigma\_{y}^{2} \end{equation} $$$\operatorname{det}(\cdot)$: Determinante, also Produkt der Eigenwerte
$$ \operatorname{det}(\mathbf{C})=\sigma\_{x}^{2} \cdot \sigma\_{y}^{2} $$
Beispiel
Ableitung mit der Matrizen Differenzregeln:
$$ \begin{aligned} \frac{\partial}{\partial \mathbf{K}} P(\mathbf{K}) &=\frac{\partial}{\partial \mathbf{K}}\left\{\underline{e}^{\top}\left[(\mathbf{I}-\mathbf{K} \mathbf{H}) \mathbf{C}_{p}(\mathbf{I}-\mathbf{K} \mathbf{H})^{\top}+\mathbf{K} \mathbf{C}_{y} \mathbf{K}^{\top}\right] \underline{e}\right\} \\ &=\frac{\partial}{\partial \mathbf{K}}\left\{\underline{e}^{\top}\left[\mathbf{C}_{p}-\mathbf{C}_{p} \mathbf{H}^{\top} \mathbf{K}^{\top}-\mathbf{K} \mathbf{H} \mathbf{C}_{p}+\mathbf{K} \mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top} \mathbf{K}^{\top}+\mathbf{K} \mathbf{C}_{y} \mathbf{K}^{\top}\right] \underline{e}\right\} \\ &=-\left[\mathbf{H} \mathbf{C}_{p} \underline{e} \underline{e}^{\top}\right]^{\top}-\underline{e} \underline{e}^{\top}\left(\mathbf{H} \mathbf{C}_{p}\right)^{\top}+2 \underline{e} \underline{e}^{\top} \mathbf{K} \mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}+2 \underline{e} \underline{e}^{\top} \cdot \mathbf{K} \mathbf{C}_{y} \\ &\overset{!}{=} \mathbf{0} \end{aligned} $$Also
$$ \begin{array}{l} -\mathbf{C}_{p} \cdot \mathbf{\mathbf{H}}^{\top}-\mathbf{C}_{p} \mathbf{H}^{\top}+2 \mathbf{K} \mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}+2 \mathbf{K} \mathbf{C}_{y} \stackrel{!}{=} \mathbf{0} \\ \mathbf{K}\left(\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}\right)^{\top}=\mathbf{C}_{p} \mathbf{H}^{\top} \\ \mathbf{K}=\mathbf{C}_{p} \mathbf{H}^{\top}\left(\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{\mathbf{H}}^{\top}\right)^{-1} \quad \text { (Kalman gain) } \end{array} $$Setze $\mathbf{K}$ in $(\ast \ast)$ ein
$$ \begin{aligned} \underline{\hat{x}}_{e} &=(\mathbf{I}-\mathbf{K} \mathbf{H}) \underline{\hat{x}}_{p}+\mathbf{K} \cdot \underline{\hat{y}} \qquad \text { (combination form) } \\ &=\underline{\hat{x}}_{p}+\mathbf{K}\left(\underline{\hat{y}}-\mathbf{H} \cdot \underline{\hat{x}}_{p}\right) \qquad \text { (feedback form) } \\ &=\underline{\hat{x}}_{p}+\mathbf{C}_{p} \mathbf{H}^{\top}\left(\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}\right)^{-1}\left(\underline{y}-\mathbf{H} \cdot \underline{\hat{x}}_{p}\right) \end{aligned} $$Das ist das Kalman Filter.
Nun Setze $\mathbf{K}$ in $(\ast \ast \ast)$ ein, um die Kovarianzmatrix zu berechnen.
$$ \begin{aligned} \mathbf{C}_{e}=& {\left[\mathbf{I}-\mathbf{C}_{p} \mathbf{H}^{\top}\left(\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}\right)^{-1} \mathbf{H}_{k}\right] \cdot \mathbf{C}_{p} } \\ & \cdot\left[\mathbf{I}-\mathbf{C}_{p} \mathbf{H}^{\top}\left(\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}\right)^{-1} \mathbf{H}_{k}\right]^{-1} \\ &+\mathbf{C}_{p} \mathbf{H}^{\top}\left(\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}\right)^{-1} \mathbf{C}_{y}\left(\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}\right)^{-1} \mathbf{H} \mathbf{C}_{p} \\\\ =& \mathbf{C}_{p}-2 \mathbf{C}_{p} \mathbf{H}^{\top}\left(\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}\right)^{-1} \mathbf{H} \mathbf{C}_{p} \\ &+\mathbf{C}_{p} \mathbf{H}^{\top}\left(\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}\right)^{-1} \mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}\left(\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}\right)^{-1} \mathbf{H} \mathbf{C}_{p} \\ &+\mathbf{C}_{p} \mathbf{H}^{\top}(\underbrace{\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}}_{=:\mathbf{D}})^{-1} \mathbf{C}_{y}\left(\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}\right)^{-1} \mathbf{H} \mathbf{C}_{p}\\\\ =& \mathbf{C}_{p}-2 \mathbf{C}_{p} \mathbf{H}^{\top} \mathbf{D}^{-1} \mathbf{H} \mathbf{C}_{p}+\mathbf{C}_{p} \mathbf{H}^{\top} \mathbf{D}^{-1} \mathbf{D} \mathbf{D}^{-1} \mathbf{H} \mathbf{C}_{p} \\\\ =& \mathbf{C}_{p}-\mathbf{C}_{p} \mathbf{H}^{\top}\left(\mathbf{C}_{y}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top}\right)^{-1} \mathbf{H} \mathbf{C}_{p} \end{aligned} $$Beispiel
Kompletter Kalman Filter: Übungsblatt 5 Aufgabe 3
Prädiktion: Übungsblatt 5, Aufgabe 4
Filterung: Übungsblatt 6 Aufgabe 1