Nichtlineare Schätzung
Approximation durch Linearisierung
Idea
Linearisierung der nichtlinear Funktion
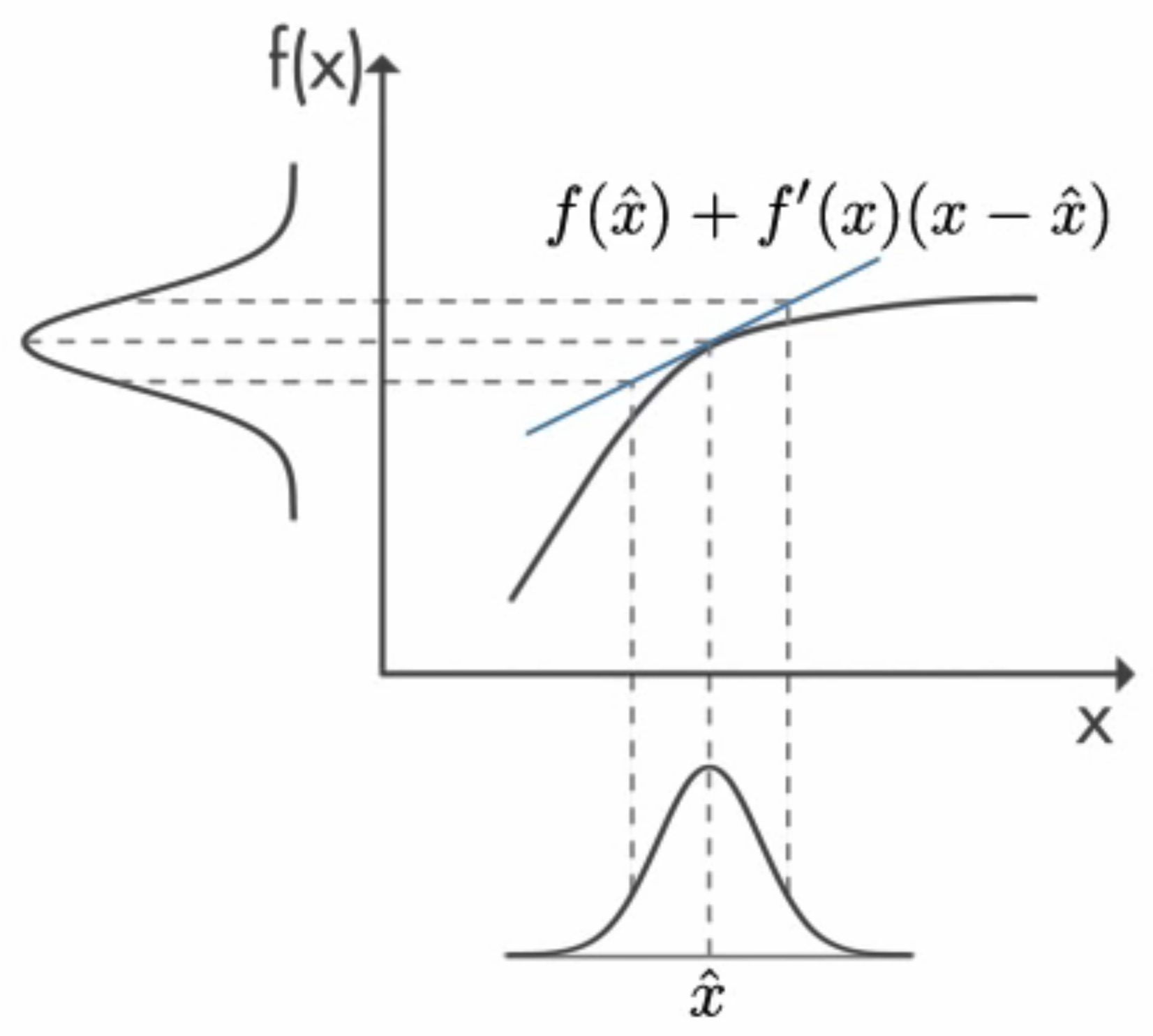
(Normal/Linear) Kalman Filter anwenden
Systemmodell
$$ \underline{x}_{k+1}=\underline{a}_{k}\left(\underline{x}_{k}, \underline{u}_{k}\right) \tag{Systemmodell} $$Linearisierung der rechten Seite von $\text{(Systemmodell)}$ mit Taylor-Entwicklung von $\underline{\overline{x}}_k, \underline{\overline{u}}_k$ :
$$ \begin{array}{ll} &\underline{a}_{k}\left(\underline{x}_{k}, \underline{u}_{k}\right) = \underline{a}_{k}\left(\underline{\overline{x}}_k, \underline{\overline{u}}_k\right) &+ \overbrace{\left.\frac{\partial \underline{a}_{k}\left(\underline{x}_{k}, \underline{u}_{k}\right)}{\partial \underline{x}_{k}^{\top}}\right|_{\underline{x}_{k}=\underline{\bar{x}}_{k}, \underline{u}_{k}=\underline{\bar{u}}_{k}}}^{=\mathbf{A}} \cdot \overbrace{(\underline{x}_{k} - \underline{\overline{x}}_k)}^{=\Delta \underline{x}_{k}} + \text{THO} \\\\ & & + \underbrace{\left.\frac{\partial \underline{a}_{k}\left(\underline{x}_{k}, \underline{u}_{k}\right)}{\partial \underline{u}_{k}^{\top}}\right|_{\underline{x}_{k}=\underline{\bar{x}}_{k}, \underline{u}_{k}=\overline{\underline{\bar{u}}}_{k}}}_{=\mathbf{B}} \cdot (\underline{u}_{k} - \underline{\overline{u}}_k) + \text{THO} \end{array} $$$\text{THO}$: Terme höherer Ordnung
Jacobi-Matrizen
$$ \begin{array}{l} \mathbf{A}_{k}=\left[\begin{array}{ccc} \frac{\partial a_{k, 1}}{\partial x_{k, 1}} & \cdots & \frac{\partial a_{k, 1}}{\partial x_{k, N}} \\ \vdots & & \vdots \\ \frac{\partial a_{k, N}}{\partial x_{k, 1}} & \cdots & \frac{\partial a_{k, N}}{\partial x_{k, N}} \end{array}\right]_{\underline{x}_{k}=\overline{\underline{x}}_{k}, \underline{u}_{k}= \bar{\underline{u}}_{k}} \\\\ \mathbf{B}_{k}=\left[\begin{array}{ccc} \frac{\partial a_{k, 1}}{\partial u_{k, 1}} & \cdots & \frac{\partial a_{k, 1}}{\partial u_{k, N}} \\ \vdots & & \vdots \\ \frac{\partial a_{k, N}}{\partial u_{k, 1}} & \cdots & \frac{\partial a_{k, N}}{\partial u_{k, N}} \end{array}\right]_{\underline{x}_{k}=\overline{\underline{x}}_{k}, \underline{u}_{k}= \bar{\underline{u}}_{k}} \end{array} $$
Annahme
- Ableitung existiert
- $\underline{a}_k(\cdot, \cdot)$ ausreichend linear um $\underline{\overline{x}}_k, \underline{\overline{u}}_k$
Vernachlässigen von $\text{THO} \Rightarrow$
$$ \underline{a}_{k}\left(\underline{x}_{k}, \underline{u}_{k}\right) \approx \underline{a}_{k}\left(\underline{\overline{x}}_k, \underline{\overline{u}}_k\right)+\mathbf{A}_{k}\left(\underline{x}_k-\underline{\overline{x}}_k\right)+\mathbf{B}_{k}\left(\underline{u}_{k}-\underline{\overline{u}}_k\right) $$Für die linke Seite von $(\text{Systemmodell})$:
$$ \underline{x}_{k+1}= \underline{\overline{x}}_{k+1} + \Delta \underline{x}_{k+1} $$Für $\underline{u}_{k}$ definiere man
$$ \underline{u}_{k}:=\underline{\hat{u}}_{k}+\underline{w}_{k} $$mit $E\left\{\underline{w}_{k}\right\}=0, \operatorname{Cov}\left\{\underline{w}_{k}\right\}=\mathbf{C}_{k}^{w}$
Lineariesierung: $\overline{\underline{u}}_{k} \overset{!}{=} \hat{\underline{u}}_{k} \Rightarrow \Delta \underline{u}_{k}= \underline{u}_{k} -\overline{\underline{u}}_{k} = \underline{w}_{k}$ (d.h. die Abweichung $\underline{w}_k$ ist ein Rauschen)
Äquivalentes Rauschen
$$ w_{k}^{\prime}=\mathbf{B}_{k} \cdot w_{k} \Rightarrow E\left\{w_{k}^{\prime}\right\}=0, \operatorname{Cov}\left\{w_{k}^{\prime}\right\}=\mathbf{B}_{k} \cdot \mathbf{C}_{k}^{w} \cdot \mathbf{B}_{k}^{\top} $$
Durch obige Linearisierung der beiden Seiten kann man das Systemmodell so schreiben:
$$ \underline{\overline{x}}_{k+1} + \Delta \underline{x}_{k+1} \approx \underline{a}_{k}\left(\underline{\overline{x}}_k, \underline{\overline{u}}_k\right)+\mathbf{A}_{k}\Delta \underline{x}_k+\underline{w}_k^\prime $$Nominalteil
$$ \underline{\overline{x}}_{k+1} = \underline{a}_{k}\left(\underline{\overline{x}}_k, \underline{\overline{u}}_k\right) $$Differentialteil
$$ \Delta \underline{x}_{k+1} \approx \mathbf{A}_{k}\Delta \underline{x}_k+\underline{w}_k^\prime $$
Messgleichung
$$ \underline{y}_{k}=\underline{h}_{k}\left(\underline{x}_{k}, \underline{v}_{k}\right) \tag{Messgleichung} $$Linearisierung der rechten Seite um $\underline{\bar{x}}_{k}, \underline{\bar{v}}_{k}$ :
$$ \underline{h}_{k}\left(\underline{x}_{k}, \underline{v}_{k}\right) \approx \underline{h}_{k}\left(\underline{\bar{x}}_{k}, \underline{\bar{v}}_{k}\right)+\mathbf{H}_{k} \cdot \underbrace{\left(\underline{x}_{k}-\underline{\bar{x}}_{k}\right)}_{=\Delta \underline{x}_k}+\mathbf{L}_{k} \cdot\left(\underline{v}_{k}-\underline{\bar{v}}_{k}\right) $$mit Jacobi-Matrizen
$$ \mathbf{H}_{k}=\left.\frac{\partial \underline{h}_{k}\left(\underline{x}_{k}, \underline{v}_{k}\right)}{\partial \underline{x}_{k}^{\top}}\right|_{\underline{x}_{k}=\underline{x}_{k}, \underline{v}_{k}=\underline{\bar{v}}_{k}} \qquad \mathbf{L}_{k}=\left.\frac{\partial \underline{h}_{k}\left(\underline{x}_{k}, \underline{v}_{k}\right)}{\partial \underline{v}_{k}^{\top}}\right|_{\underline{x}_{k}=\underline{x}_{k}, \underline{v}_{k}=\underline{\bar{v}}_{k}} $$Sei $\underline{\bar{v}}_{k} = \underline{\hat{v}}_{k}$ für mittelwertfreies $\underline{v}_{k} \Rightarrow \underline{\hat{v}}_{k} = \underline{0}$
Das Effektive Rauschen ist dann
$$ \underline{v}_{k}^\prime = \mathbf{L}_{k} \cdot \underline{v}_{k} $$mit
$$ E\left\{\underline{v}_{k}^{\prime}\right\}=\underline{0}, \quad \operatorname{Cov}\left\{\underline{v}_{k}^{\prime}\right\}=\mathbf{L}_{k} \cdot \mathbf{C}_{k}^{v} \cdot \mathbf{L}_{k}^{\top} $$Damit kann man die Messgliechung so umschreiben:
$$ \underline{y}_{k}=\underline{\bar{y}}_{k}+\Delta \underline{y}_{k} \approx \underline{h}_{k}\left(\underline{\bar{x}}_{k}, \underline{\bar{v}}_{k}\right)+\mathbf{H}_{k} \Delta \underline{x}_{k}+\underline{v}_{k}^{\prime} $$Nominalteil
$$ \underline{\bar{y}}_{k} = \underline{h}_{k}\left(\underline{\bar{x}}_{k}, \underline{\bar{v}}_{k}\right) $$Differentialteil
$$ \Delta \underline{y}_{k} \approx \mathbf{H}_{k} \Delta \underline{x}_{k}+\underline{v}_{k}^{\prime} $$
Erweitertes Kalmanfilter (EKF)
💡Linearisierung um jeweils beste Schätzung
Prädiktion
Berechnung Erwartungswert über nichtlineare Funktion
$$ \underline{\hat{x}}_{k+1}^{p}=\underline{a}_{k}\left(\underline{\hat{x}}_{k}^{e}, \hat{\underline{u}}_{k}\right) $$Berechnung Kovarianzmatrix über die Linearisierung
$$ \mathbf{C}_{k+1}^{p} \approx \mathbf{A}_{k} \mathbf{C}_{k}^{e} \mathbf{A}_{k}^{\top}+\mathbf{C}_{k}^{w^{\prime}}=\mathbf{A}_{k} \mathbf{C}_{k}^{e} \mathbf{A}_{k}^{\top}+\mathbf{B}_{k} \mathbf{C}_{k}^{w} \mathbf{B}_{k}^{\top} $$mit
$$ \mathbf{A}_k = \left.\frac{\partial \underline{a}_{k}\left(\underline{x}_{k}, \underline{u}_{k}\right)}{\partial \underline{x}_{k}^{\top}}\right|_{\underline{x}_{k}=\underline{\hat{x}}_{k-1}^{e}, \underline{u}_{k}=\hat{\underline{u}}_{k}} \qquad \mathbf{B}_k = \left.\frac{\partial \underline{a}_{k}\left(\underline{x}_{k}, \underline{u}_{k}\right)}{\partial \underline{u}_{k}^{\top}}\right|_{\underline{x}_{k}=\underline{\hat{x}}_{k-1}^{e}, \underline{u}_{k}=\hat{\underline{u}}_{k}} $$
Filterung
Berechnung von $\underline{\bar{y}}_k$ (Messung, die aus dem prioren Schätzwert (also die Prädiktion) bekomme, als Nominalwert zum jetztigen Zeitpunkt)
$$ \underline{\bar{y}}_k = \underline{h}_k(\underline{\bar{x}}_k^p, \underline{\hat{v}}_k) $$Berechnung von $\Delta \underline{y}_k$
$$ \Delta \underline{y}_{k}=\underline{\hat{y}}_{k}-\underline{\bar{y}}_{k} $$- $\underline{\hat{y}}_{k}$ : wahre Messung
und
$$ \Delta \underline{y}_{k} \approx \mathbf{H}_{k} \cdot\left(\underline{x}_{k}^{e}-\underline{\hat{x}}_{k}^{p}\right)+\underline{v}_{k}^{\prime} $$mit
$$ \mathbf{H}_{k}=\left.\frac{\partial \underline{h}_{k}\left(\underline{x}_{k}, \underline{v}_{k}\right)}{\partial \underline{x}_{k}^{\top}}\right|_{\underline{x}_{k}=\underline{\hat{x}}_{k}^{p}, \underline{v}_{k}=\underline{\hat{v}}_{k}} \qquad \mathbf{L}_{k}=\left.\frac{\partial \underline{h}_{k}\left(\underline{x}_{k}, \underline{v}_{k}\right)}{\partial \underline{v}_{k}^{\top}}\right|_{\underline{x}_{k}=\underline{\hat{x}}_{k}^{p}, \underline{v}_{k}=\underline{\hat{v}}_{k}} $$
Filterung Schritt
$$ \begin{aligned} \mathbf{K}_{k}&=\mathbf{C}_{k}^{p} \mathbf{H}_{k}^{\top}\left(\mathbf{L}_{k} \mathbf{C}_{k}^{v} \mathbf{L}_{k}^{\top}+\mathbf{H}_{k} \mathbf{C}_{k}^{p} \mathbf{H}_{k}^{T}\right)^{-1} \\\\ \hat{\underline{x}}_{k}^{e}&=\hat{\underline{x}}_{k}^{p}+\mathbf{K}_{k}\left[\hat{\underline{y}}_{k}-\underline{h}_{k}\left(\hat{\underline{x}}_{k}^{p}, \hat{\underline{v}}_{k}\right)\right] \\\\ \mathbf{C}_{k}^{e}&=\mathbf{C}_{k}^{p}-\mathbf{K}_{k} \mathbf{H}_{k} \mathbf{C}_{k}^{p} = (\mathbf{I} - \mathbf{K}_{k} \mathbf{H}_{k})\mathbf{C}_{k}^{p} \end{aligned} $$
Probleme bei Linearisierung
Berechnung der posteriore Verteilung nur gut für “schwache” Nichtlinearität
$\rightarrow$ Induzierte Nichtlinearität durch die Unsicherheit in priorer Dichte (Die Nichtlinearität ist induziert durch die Unsicherheit der priorer Dichte)
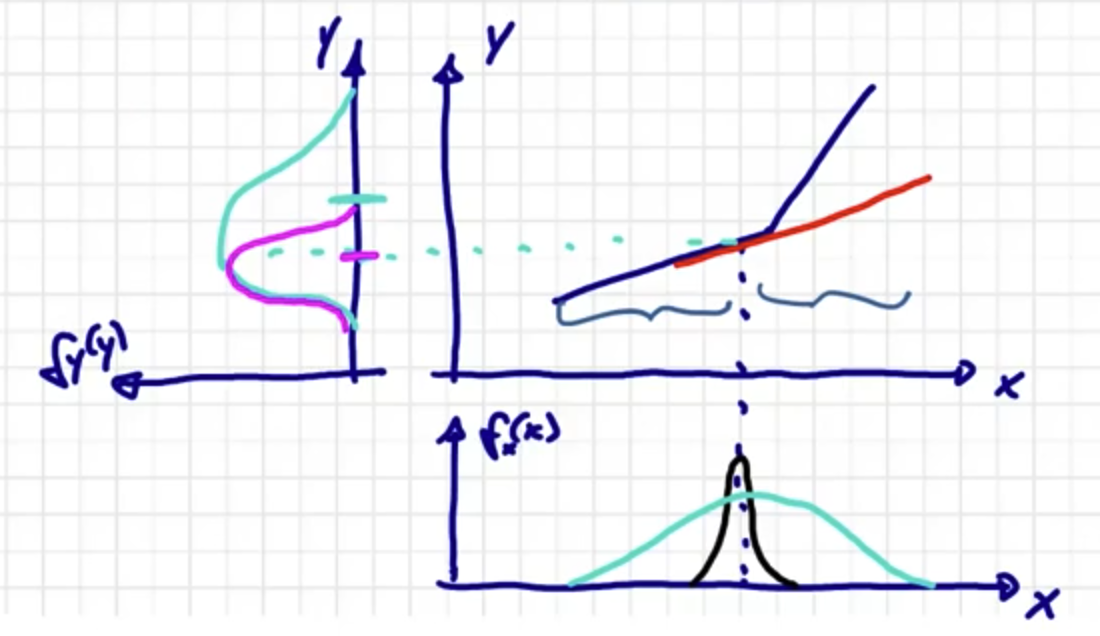
Wenn wir für priore Dichte kleines/schmales Rauschen (unten, schwarz) verwenden, dann funktioniert es gut.
Wenn wir das Rauschen breiter machen (unten, grün), dann kommt ein Problem vor, dass die resultierende Dichte von $y$ nicht symmetrisch ist.
Induzierte nichtlinearität heißt: wir können gar nicht sagen, die ist absolut betrachtet, besonders linear oder besonders nichtlinear. Es ist potential, Problem zu machen. Aber sie macht kein Problem, solange ich mich nur in den linken Bereich oder nur in den rechten Bereich des “Knickpunkt” aufhalten. Wenn wir die Dichte habe, die über den “Knickpunkt” weggeht, dann bekomme ich Problem. Das ist die induzierte nichtlinearität, die durch das Rauschen induziert wird.
Linearisierung nur um einen Punkt
Linearisiertes System ist i.A. zeitvariant, auch wenn originalsytstem zeitinvariant ist, da Linearisierung vom Schätzwert abhängt.
Schätzung in probabilistischer Form: Nichtlineares Kalmanfilter
Erwartungswertbildung
Gegeben:
- Funktion $\underline{y}=\underline{g}(\underline{x})$
- $\underline{x} \sim f_x(x)$
Gesucht: Bestimmte Momente von $\underline{y}$
Z.B. für skalares Fall
$$ y = g(x) $$suchen wir $E\left\{y^{j}\right\}, j \in \mathbb{N}$ .
Wir wissen
$$ E\left\{y^{i}\right\}=\int_{\mathbb{R}} y^{j} f_{y}(y) d y $$Aber
- $f_y(y)$ , posteriore Dichte, ist oft nicht einfach berechbar
- Falls berechbar, die Berechnung von $f_y(y)$ is viel zu aufwändig, wenn nur Momente benötigt werden
Theorem (Dualität bei Erwartungswertbildung)
$$ E\_{f\_y}\left\\{y^{j}\right\\}=E\_{f\_{x}}\left\\{[g(x)]^{j}\right\\}=\int\_{\mathbb{R}}[g(x)]^{j} f\_{x}(x) d x $$- $f_y(y)$ muss also nicht berechnet werden.
- Nützlich, wenn
- $f_y(y)$ schwer zu berechnen
- 1-order nichtlineare Momente von $f_x(\cdot)$ einfach berechenbar
Für sample-basierte Approximation der prioren Dichte $f_x(x)$
$$ f_{x}(x)=\sum_{i=1}^{L} w_{i} \delta\left(x-x_{i}\right) $$ist berechnung der posterioren Dichte $f_y(y)$ trivial.
$$ f_y(y)=\sum_{i=1}^{L} w_{i} \delta\left(y-y_{i}\right), \quad y_{i}=g\left(x_{i}\right) $$Damit
$$ E\left\{y^{j}\right\}=\int_{\mathbb{R}} y^{j} f_{y}(y) d y=\sum_{i=1}^{L} w_{i} y_{i}^{j}=\sum_{i=1}^{L} w_{i}\left[g\left(x_{i}\right)\right]^{j} $$und
$$ E\left\{[g(x)]^{j}\right\}=\int_{\mathbb{R}}[g(x)]^{j} f_{x}(x) d x=\sum_{i=1}^{L} w_{i}\left[g\left(x_{i}\right)\right]^{j} $$Die Berechnungen sind in diesem Fall identisch, aber im allgemeinem Fall gilt dies NICHT! 🤪
Prädiktion in probabilistischer Form
Systemmodell
$$ x_{k+1}=\underline{a}_{k}\left(\underline{x}_{k}, \underline{u}_{k}\right) $$- $\underline{x}$ : Zustand
- $\underline{u}$ : Störgröße
Für einen Kalman Filter, wir möchte in nächsten Schritt die Erwartungswert und die Kovarianzmatrix haben.
Erwartungswert
$$ \hat{x}_{k+1}^{p}=E\left\{\underline{a}_{k}\left(\underline{x}_{k}, \underline{u}_{k}\right)\right\}=\int_{\mathbb{R}^{N}} \int_{\mathbb{R}^{p}} \underline{a}_{k}\left(\underline{x}_{k}, \underline{u}_{k}\right) f_{k}^{x u}\left(\underline{x}_{k}, \underline{u}_{k}\right) d\underline{x}_{k} d\underline{u}_{k} $$In der Regel sind $\underline{x}_{k}, \underline{u}_{k}$ unabhängig. Also
$$ f_{k}^{x u}\left(\underline{x}_{k}, \underline{u}_{k}\right) = f_{k}^{e}\left(\underline{x}_{k}\right) \cdot f_{k}^{u}\left(\underline{u}_{k}\right). $$Und nehme an, dass $\underline{x}_{k}, \underline{u}_{k}$ normalverteilt sind, also
$$ \begin{aligned} f_{k}^{e}\left(\underline{x}_{u}\right) &= \mathcal{N}(\underline{x}_{k}, \hat{x}_{k}^{e}, \mathbf{C}_{k}^{e}) \\\\ f_{k}^{u}\left(\underline{u}_{k}\right) &= \mathcal{N}\left(\underline{u}_{k}, \hat{\underline{u}}_{k}, \mathbf{C}_{k}^{w}\right) \end{aligned} $$Für additives Rauschen
$$ \underline{x}_{k+1}=\underline{a}_{k}\left(\underline{x}_{k}\right)+\underline{u}_{k} \left(= \underline{a}_{k}\left(\underline{x}_{k}\right)+(\underline{\hat{u}}_{k} + \underline{w}_k)\right) $$gilt
$$ \underline{\hat{x}}_{k+1}^{p}=\int_{\mathbb{R}^{n}} \underline{a}_{k}\left(\underline{x}_{k}\right) \cdot f_{k}^{e}\left(\underline{x}_{k}\right) d \underline{x}_{k}+\underline{\hat{u}}_{k} $$Dann ist
$$ \begin{aligned} \underline{x}_{k+1} - \underline{\hat{x}}_{k+1}^{p} &= (\underline{a}_{k}(\underline{x}_{k})+(\underline{\hat{u}}_{k} + \underline{w}_k)) - \left(\int_{\mathbb{R}^{n}} \underline{a}_{k}\left(\underline{x}_{k}\right) \cdot f_{k}^{e}\left(\underline{x}_{k}\right) d \underline{x}_{k}+\underline{\hat{u}}_{k}\right) \\\\ &= \underbrace{\underline{a}_{k}(\underline{x}_{k}) - \int_{\mathbb{R}^{n}} \underline{a}_{k}\left(\underline{x}_{k}\right) \cdot f_{k}^{e}\left(\underline{x}_{k}\right) d \underline{x}_{k}}_{:= \underline{\bar{a}}_{k}(\underline{x}_{k})} + \underline{w}_k \end{aligned} $$Die Kovarianzmatrix ist
$$ \begin{aligned} \mathbf{C}_{k+1}^{p} &= E\left\{\left(\underline{x}_{k+1}-\underline{\hat{x}}_{k+1}^{p}\right)(\underline{x}_{k+1}-\underline{\hat{x}}_{k+1}^{p})^{\top}\right\} \\\\ &= E\left\{(\underline{\bar{a}}_{k}(\underline{x}_{k}) + \underline{w}_k) (\underline{\bar{a}}_{k}(\underline{x}_{k}) + \underline{w}_k) ^ \top\right\} \\\\ &= E\left\{\underline{\bar{a}}_{k}(\underline{x}_k) \underline{\bar{a}}_{k}^\top(\underline{x}_k) + \underline{w}_k\underline{\bar{a}}_{k}(\underline{x}_k) + \underline{\bar{a}}_{k}(\underline{x}_k)\underline{w}_k^\top + \underline{w}_k\underline{w}_k^\top\right\} \\\\ &= E\left\{\underline{\bar{a}}_{k}(\underline{x}_k) \underline{\bar{a}}_{k}^\top(\underline{x}_k)\right\} + \underbrace{E\left\{\underline{w}_k\underline{\bar{a}}_{k}(\underline{x}_k)\right\}}_{=0} + \underbrace{E\left\{\underline{\bar{a}}_{k}(\underline{x}_k)\underline{w}_k^\top\right\}}_{=0} + E\left\{\underline{w}_k\underline{w}_k^\top\right\} \\\\ &= E\left\{\underline{\bar{a}}_{k}(\underline{x}_k) \underline{\bar{a}}_{k}^\top(\underline{x}_k)\right\} + E\left\{\underline{w}_k\underline{w}_k^\top\right\} \\\\ &= \int_{\mathbb{R}^{N}} \overline{\underline{a}}_{k}\left(\underline{x}_{k}\right) \overline{\underline{a}}_{k}^{\top}\left(x_{k}\right) f_{k}^{e}\left(\underline{x}_{k}\right) d \underline{x}_{k}+\mathbf{C}_{k}^{w} \end{aligned} $$Filterung in probabilistischer Form
Einschub: Konditionierung einer Gaußschen Verbunddichte
Zufallsvektor $\underline{z}=\left[\begin{array}{l}\underline{x} \\ \underline{y}\end{array}\right]$ mit Gaußcher Verbundverteilung:
$$ f(\underline{z})=\mathcal{N}\left(\underline{z}_{1}, \underline{\hat{z}}, \mathbf{C}_{z}\right), \quad \underline{\hat{z}}=\left[\begin{array}{l} \underline{\hat{x}} \\ \underline{\hat{y}} \end{array}\right], \quad \mathbf{C}_{z}=\left[\begin{array}{ll} C_{x x} & C_{x y} \\ C_{y x} & C_{y y} \end{array}\right] $$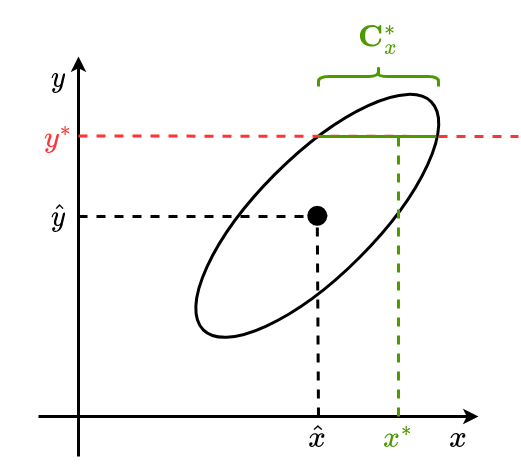
Gegeben: Messung $y^\ast$
Konditionale Verteilung:
$$ \begin{equation} f\left(\underline{x} \mid \underline{y}^{\ast}\right)= \mathcal{N}\left(\underline{x}, \underline{\hat{x}}^{*}, \mathbf{C}_{x}^{\ast}\right) \end{equation} $$Dann ist
$$ \begin{array}{l} \underline{\hat{x}}^{\ast}=\underline{\hat{x}}+C_{x y} C_{y y}^{-1}\left(\underline{y}^{*}-\underline{\hat{y}}\right) \\ \mathbf{C}_{x}^{\ast}=C_{x x}-C_{x y} C_{y y}^{-1} C_{y x} \end{array} \tag{*} $$Alternative Herleitung Kalmanfilter
Messmodell
$$ \underline{y}=\mathbf{H} \cdot \underline{x}+\underline{v} $$Gegeben:
$$ \underline{x}_{p} \sim \mathcal{N}\left(\hat{\underline{x}}_{p}, \mathbf{C}_{p}\right), \quad \underline{v}\sim \mathcal{N}\left(\underline{0}, \mathbf{C}_{v}\right) $$Wir definiere $\underline{z}$ als Verbund von $\underline{x}_{p}$ und $\underline{y}$
$$ \underline{z}:=\left[\begin{array}{l} \underline{x}_{p} \\ \underline{y} \end{array}\right]=\left[\begin{array}{l} \underline{x}_{p} \\ \mathbf{H} \cdot \underline{x}_{p}+\underline{v} \end{array}\right]=\left[\begin{array}{ll} \mathbf{I} & 0 \\ \mathbf{H} & \mathbf{I} \end{array}\right]\left[\begin{array}{c} \underline{x}_{p} \\ \underline{v} \end{array}\right] $$Die Erwartungswert ist dann
$$ \underline{\hat{z}}=\left[\begin{array}{c} \hat{x}_{p} \\ \mathbf{H} \cdot \hat{x}_{p} \end{array}\right] $$Die Kovairanzmatrix von $\underline{z}$ :
$$ \begin{array}{l} \operatorname{Cov}\{\underline{z}\}&=E\left\{\left[\begin{array}{ll} \mathbf{I} & 0 \\ \mathbf{H} & \mathbf{I} \end{array}\right]\left[\begin{array}{c} \underline{x}_{p}-\hat{\underline{x}}_{p} \\ \underline{v} \end{array}\right]\left[\begin{array}{c} \underline{x}_{p}-\underline{\hat{x}}_{p} \\ \underline{v} \end{array}\right]^{\top}\left[\begin{array}{cc} \mathbf{I} & \mathbf{H}^{\top} \\ 0 & \mathbf{I} \end{array}\right]\right\}\\\\ &=\left[\begin{array}{ll} \mathbf{I} & 0 \\ \mathbf{H} & \mathbf{I} \end{array}\right] E\left\{\left[\begin{array}{cc} \underbrace{\left(\underline{x}_{p}-\underline{\hat{x}}_{p}\right)(\underline{x}_{p}-\underline{\hat{x}}_{p})^{\top}}_{=\mathbf{C}_p} & \underbrace{\left(\underline{x}_{p}-\underline{\hat{x}}_{p}\right) \underline{v}^{\top}}_{=0} \\ \underbrace{\underline{v}\left(\underline{x}_{p}-\underline{\hat{x}}_{p}\right)}_{=0} & \underbrace{\underline{v} \underline{v}^{\top}}_{=\mathbf{C}_v} \end{array}\right]\right\}\left[\begin{array}{cc} \mathbf{I} & 0 \\ \mathbf{H} & \mathbf{I} \end{array}\right]\\\\ &=\left[\begin{array}{ll} \mathbf{I} & 0 \\ \mathbf{H} & \mathbf{I} \end{array}\right]\left[\begin{array}{cc} \mathbf{C}_p & 0 \\ 0 & \mathbf{C}_v \end{array}\right]\left[\begin{array}{cc} \mathbf{I} & 0 \\ \mathbf{H} & \mathbf{I} \end{array}\right]=\left[\begin{array}{cc} \mathbf{C}_{p} & \mathbf{C}_{p} \mathbf{H}^{\top} \\ \mathbf{H} \mathbf{C}_{p} & \mathbf{C}_{v}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top} \end{array}\right] \end{array} $$Lasse
$$ \mathbf{C}_{x x}=\mathbf{C}_{p} \quad \mathbf{C}_{x y}=\mathbf{C}_{p} \mathbf{H}^{\top} \quad \mathbf{C}_{y x}=\mathbf{H} \mathbf{C}_{p} \quad \mathbf{C}_{y y}=\mathbf{C}_{v}+\mathbf{H} \mathbf{C}_{p} \mathbf{H}^{\top} $$und in $(*)$ einsetzen, ergibt sich der Kalman Filter.
Filterung in probabilistischer Form
Messgleichung
$$ \underline{y}=\underline{h}(\underline{x}, \underline{v}) $$Definiere
$$ \underline{z}=\left[\begin{array}{l} \underline{x} \\ \underline{y} \end{array}\right]=\left[\begin{array}{c} \underline{x} \\ \underline{h}(\underline{x}, \underline{v}) \end{array}\right] \Rightarrow E\{\underline{z}\}=\left[\begin{array}{c} \underline{\hat{x}}_{p} \\ E\{\underline{h}(\underline{x}, \underline{v})\} \end{array}\right] $$Bei additivem Rauschen
$$ y=\underline{h}(\underline{x})+\underline{v} $$gilt
$$ E\{\underline{z}\}=\left[\begin{array}{c} \underline{\hat{x}}_{p} \\ E\{\underline{h}(x)\} \end{array}\right], \quad E\{\underline{h}(x)\}=\int_{\mathbb{R}^{N}} \underline{h}(x) \underbrace{f_{p}(x)}_{= \mathcal{N}(\underline{x}, \underline{\hat{x}}_{p}, \mathbf{C}_p)} d \underline{x} \in \mathbb{R}^{M} $$Kovarianzmatrix:
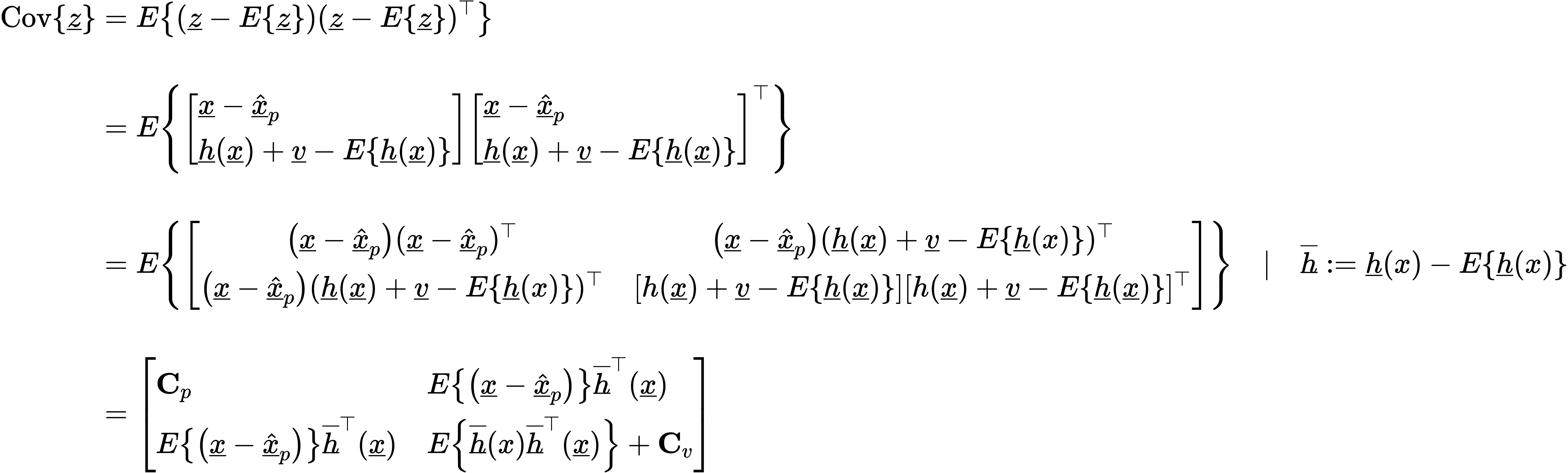
Einsetzen in $(\ast)$ ergibt sich der Nichtlineare Kalman Filter:
$$ \begin{array}{l} \underline{\hat{x}}_{e}=\underline{\hat{x}}_{p}+\mathbf{C}_{x y} \mathbf{C}_{y y}^{-1}(\underline{\hat{y}}-E\{\underline{h}(\underline{x})\}) \\ \mathbf{C}_{e}=\mathbf{C}_{p}-\mathbf{C}_{x y} \mathbf{C}_{y y}^{-1} \mathbf{C}_{y x} \end{array} $$