Allgemeine Systeme
Generatives und probabilistisches Modell
Für Herleitung ist es super wichtig, die Eigenschaft der Dirac’schen Funktion anzuwenden:
$$ \delta (g(x)) = \sum_{i=1}^N \frac{1}{|g^\prime(x_i)|}\delta (x - x_i) $$- $g(x_i) = 0$
- $g^\prime(x_i) \neq 0$
Mit Additivem Rauschen
Generatives Modell:
$$ z = a(x) + v \quad v \sim f_v(v) $$Probabilistisches Modell:
$$ f(z \mid x) = f_v(z - a(x)) $$Mit Multiplikativem Rauschen
Generatives Modell:
$$ z = x \cdot v \quad v \sim f_v(v) $$Probabilistisches Modell:
$$ f(z \mid x) = \frac{1}{|x|}f_v(\frac{z}{x}) $$Warum lässt sich das nur bei bestimmten Modellen exakt lösen?
“For the general generative model, where the noise enters the system in an arbitrary fashion.” (Script P149)
Abstraktion
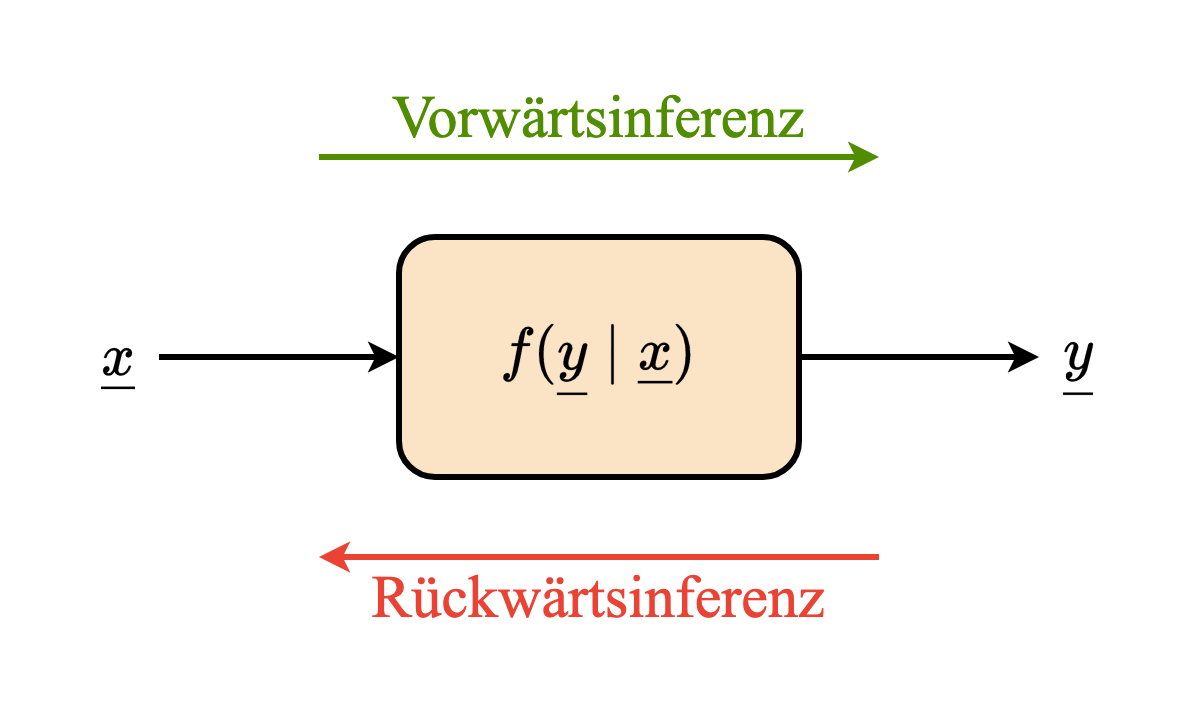
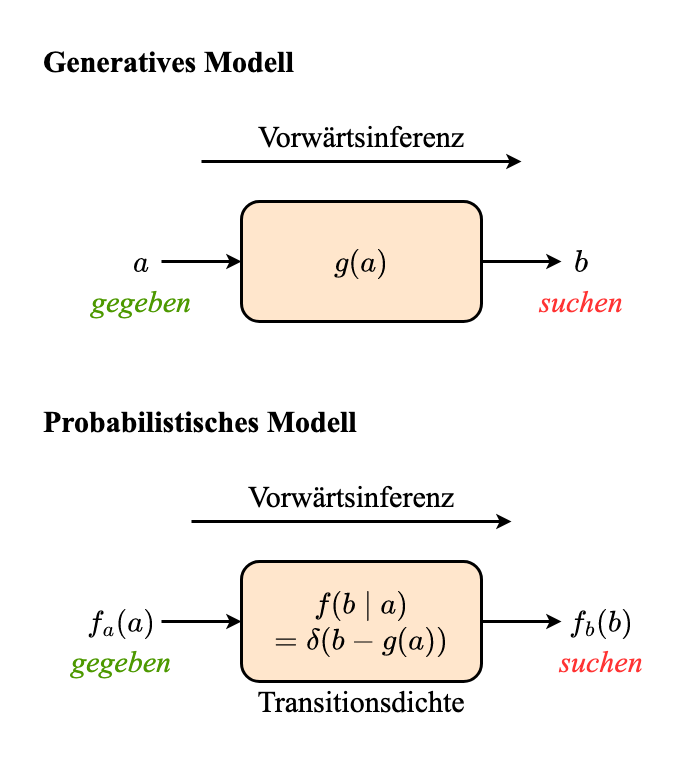
Prädiktion (Vorwärtsinferenz)
- Gegeben
- $f_a(a)$
- $g(a)$
- Gesucht: $f_b(b)$
Chapman-Kolmogorov-Gleichung
Herleitung ist ganz simple: Verbunddichte + Marginalisierung
$$ f\left(x_{k+1}\right)= \int_{\mathbb{R}^{N}} f\left(\underline{x}_{k+1}, \underline{x}_{k}\right) d \underline{x}_{k}= \int_{\mathbb{R}^{N}} f\left(\underline{x}_{k+1} \mid \underline{x}_{k}\right) \cdot f\left(\underline{x}_{k}\right) d \underline{x}_{k} $$‼️ Problem: Parameterintegral
- Integrand hängt von $\underline{x}_{k+1}$ ab (lässt sich i.Allg nicht herausziehen)
- Erfordert Lösung des Integrals für alle $\underline{x}_{k+1}$
- Nur möglich für analytische Lösung
Prädiktionsschritte
Umforme $f(b \mid a) = \delta(b - g(a))$ mit
$$ \delta (g(x)) = \sum_{i=1}^N \frac{1}{|g^\prime(x_i)|}\delta (x - x_i) $$wobei
- $g(x_i) = 0$ (also $x_i$ sind Nullstellen, $i = 1, 2, \dots, N$)
- $g^\prime(x_i) \neq 0$
Berechne $f_b(b)$ mithilfe von Chapman-Kolmogorov-Gleichung
$$ f(b) = \int f(b \mid a) f(a) da $$und setze die Unformung von $f(b \mid a)$ von Schritt 1 ein. Dann kriege die gesuchte Dichtefunktion $f_b(b)$ in Abhängigkeit von $f_a(a)$.
Vereinfachte Prädiktion
Für
$$ \underline{z} = \underline{a}(\underline{x}, \underline{w}) $$ist die Transitionsdichte $f(\underline{z} | \underline{x})$ durch Mixture approximierbar
$$ f(\underline{z} | \underline{x}) = \sum_{i \in \mathbb{Z}} f_i^z(\underline{z}) \cdot f_i^x(\underline{x}) $$wobei $f_i^z(\underline{z})$ und $f_i^x(\underline{x})$ beliebige Dichte (z.B Gaußdichte) sein können.
Schreibweise mit $\underline{x}_{k+1}$ und $\underline{x}_{k}$ :
$$ f\left(\underline{x}_{k+1} \mid \underline{x}_k\right)=\sum_{i=1}^L w_k^{(i)} f_{k+1}^{(i)}\left(\underline{x}_{k+1}\right) f_k^{(i)}\left(\underline{x}_k\right) $$Filterung
Rückwartsinferenz
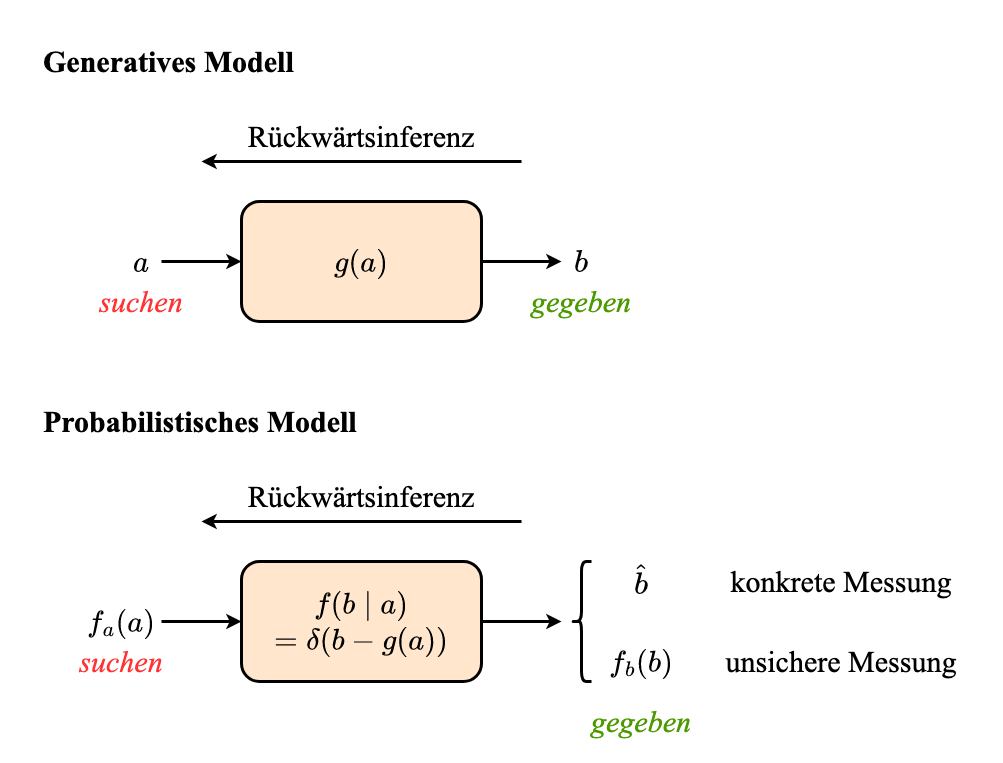
Bei Rückwartsinferenz ist es wichtig, Formel von Bayes anwuwenden.
$$ f(a \mid b) = \frac{f(a, b)}{f(b)} = \frac{f(b \mid a) f(a)}{f(b)} = \underbrace{\frac{1}{f(b)}}_{\text{Normalizationskonstant}} \cdot \underbrace{f(b \mid a)}_{\text{Likelihood}} \cdot \underbrace{f(a)}_{\text{Vorwissen}} $$Konkrete Messung
Umforme $f_b(b \mid a) = \delta(b - g(a))$ mit
$$ \delta (g(x)) = \sum_{i=1}^N \frac{1}{|g^\prime(x_i)|}\delta (x - x_i) $$wobei
- $g(x_i) = 0$ (also $x_i$ sind Nullstellen, $i = 1, 2, \dots, N$)
- $g^\prime(x_i) \neq 0$
Berechne $f_b(b)$
$$ f_b(b) = \int f_{a, b}(a, b) da = \int f_{b}(b \mid a) f_a(a) da $$mit Einsetzen der Unformung von $f(b \mid a)$ von Schritt 1 ein
Berechne $f_a(a \mid \hat{b})$ mithilfe von Bayes Regeln
$$ f_a(a \mid \hat{b}) = \frac{f_a(\hat{b} \mid a) f_a(a)}{f_b(\hat{b})} = \frac{\overbrace{\delta(\hat{b} - g(a))}^{\text{Schritt 1}} f_a(a)}{\underbrace{f_b(\hat{b})}_{\text{Schritt 2}}} $$
Unsichere Messung
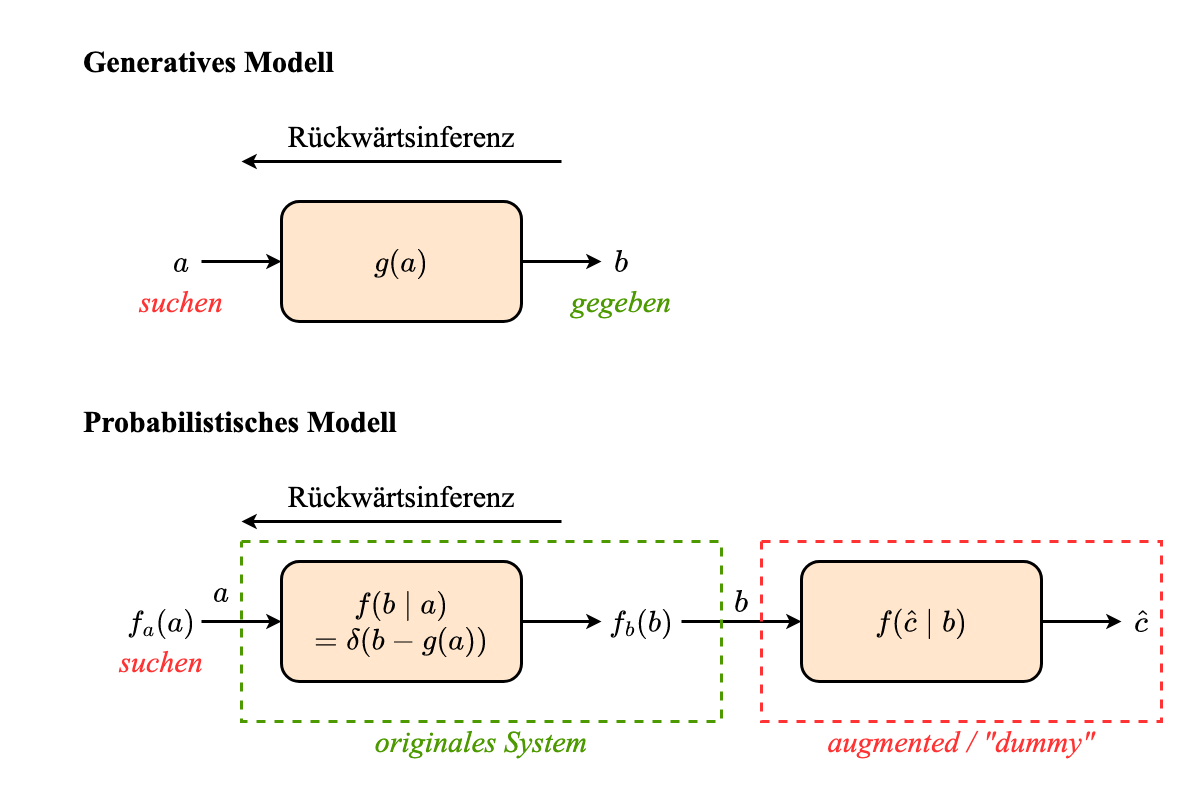
Schritte:
- Erweitere das System um eine zusätzliche stochastische Abbildung und einen festen Ausgang $\hat{z}$
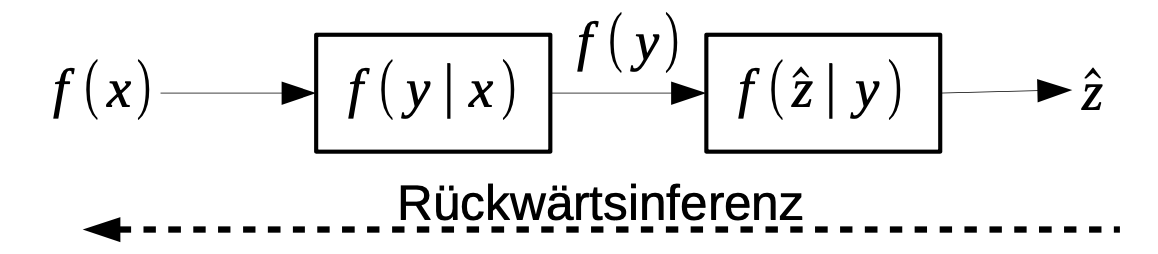
Bestimme $f(\hat{z} \mid y)$
$$ \begin{aligned} f(\hat{z} \mid y) &= \frac{f(y \mid \hat{z})f(\hat{z})}{f(y)} \\\\ &= \frac{f(y \mid \hat{z})f(\hat{z})}{\int f(y, x) dx} \\\\ &= \frac{f(y \mid \hat{z})f(\hat{z})}{\int f(y|x)f(x) dx} \\\\ &= \frac{f(y \mid \hat{z})f(\hat{z})}{\int \delta(y - g(x)) f(x) dx} \\\\ \end{aligned} $$Und setze die Umformung von $\delta(y - g(x))$
$$ \delta (g(x)) = \sum_{i=1}^N \frac{1}{|g^\prime(x_i)|}\delta (x - x_i) $$- $g(x_i) = 0$ (also $x_i$ sind Nullstellen, $i = 1, 2, \dots, N$)
- $g^\prime(x_i) \neq 0$
ein.
Berechung der Rückwärtsinferenz $f(x \mid \hat{z})$
$$ \begin{aligned} f(x \mid \hat{z}) &=\frac{1}{f\left(\hat{z}\right)} \cdot f(x, \hat{z}) \quad \mid \text{Marginalisierung nach } y\\ &=\frac{1}{f(\hat{z})} \int f(x, y, \hat{z}) d y \\ &=\frac{1}{f(\hat{z})} \int f(\hat{z} \mid y, x) \cdot f(y , x) d y \quad \mid \hat{z}, x \text{ sind unabhängig}\\ &=\frac{1}{f(\hat{z})} \int f(\hat{z} \mid y) \cdot f(y \mid x) \cdot f(x) d y \\ &=\frac{1}{f(\hat{z})} \int \underbrace{f(\hat{z} \mid y)}_{\text{Berechnet in Schritt 1}} \cdot \underbrace{f(y \mid x)}_{\text{Systemmodell}} \cdot f(x) d y \end{aligned} $$
Schwierigkeit vom Filterschritt
- Type der Dichte zur Beschreibung der Schätzung ändert sich
- Dichte wrid mit jedem Schritt komplexer
Vereinfachte Filterung
Vereinfachung der Likelihood $f(\underline{y} \mid \underline{x})$ durch Mixture (Analog zu vereinfachter Prädiktion)
$$ f(\underline{y} \mid \underline{x}) = \sum_{i \in \mathbb{Z}} f_i^y(\underline{y}) f_i^x(\underline{x}) $$